고민 1. 배포 단위 및 시스템 설계
요구사항을 바탕으로 기능 명세서 작성 및 구체화 - 2월 9일 진행
- 기능 단위로 보았을때 추천 + 분석 + 고객 CRUD(로그인/상담 진행) + 관리자 + CRM 방향성의 발송
- 각 서비스의 트래픽 분산도와 장애 범위의 분리 단위는 어떻게 가져가야 하는가 ⇒ 예를 들자면, 추천 시스템에서 실시간 또는 주기적인 분석을 통해 추천 알고리즘이 동작하는데 해당 부분에서 장애가 발생하면 고객 CRUD 부분까지 장애가 전파되며 기본적인 상담과 상품 조회 등을 하지 못하는 장애가 발생한다.
- 기능 명세서를 기준으로 보면 서비스는 크게 추천, 분석, 고객 CRUD(로그인/상담), 관리자, 발송으로 나뉘었다. 이때 트래픽 패턴과 장애 발생 가능 지점이 서로 다르다고 판단.
- 고객 CRUD와 상담, 상품 조회는 항상 안정적으로 동작해야 한다고 보았고, 반면 추천과 분석은 로그 수집과 집계, 캐시, 인덱스 같은 변수가 많아 장애가 발생할 가능성이 높다고 판단.
- 배치 기반 분석은 CPU 사용량과 디스크 I/O, DB 스캔이 비교적 큰 작업이므로 온라인 트래픽과 같은 런타임에서 돌리면 장애 전파 가능성이 높아진다고 판단.
- 시스템 단위 설계에서 핵심은
“항상 살아야 하는 영역”과“부하/실험/집계로 흔들릴 수 있는 영역”을 분리. - 추천과 분석은 같은 기능 묶음으로 보일 수 있으나 역할이 다르다고 판단
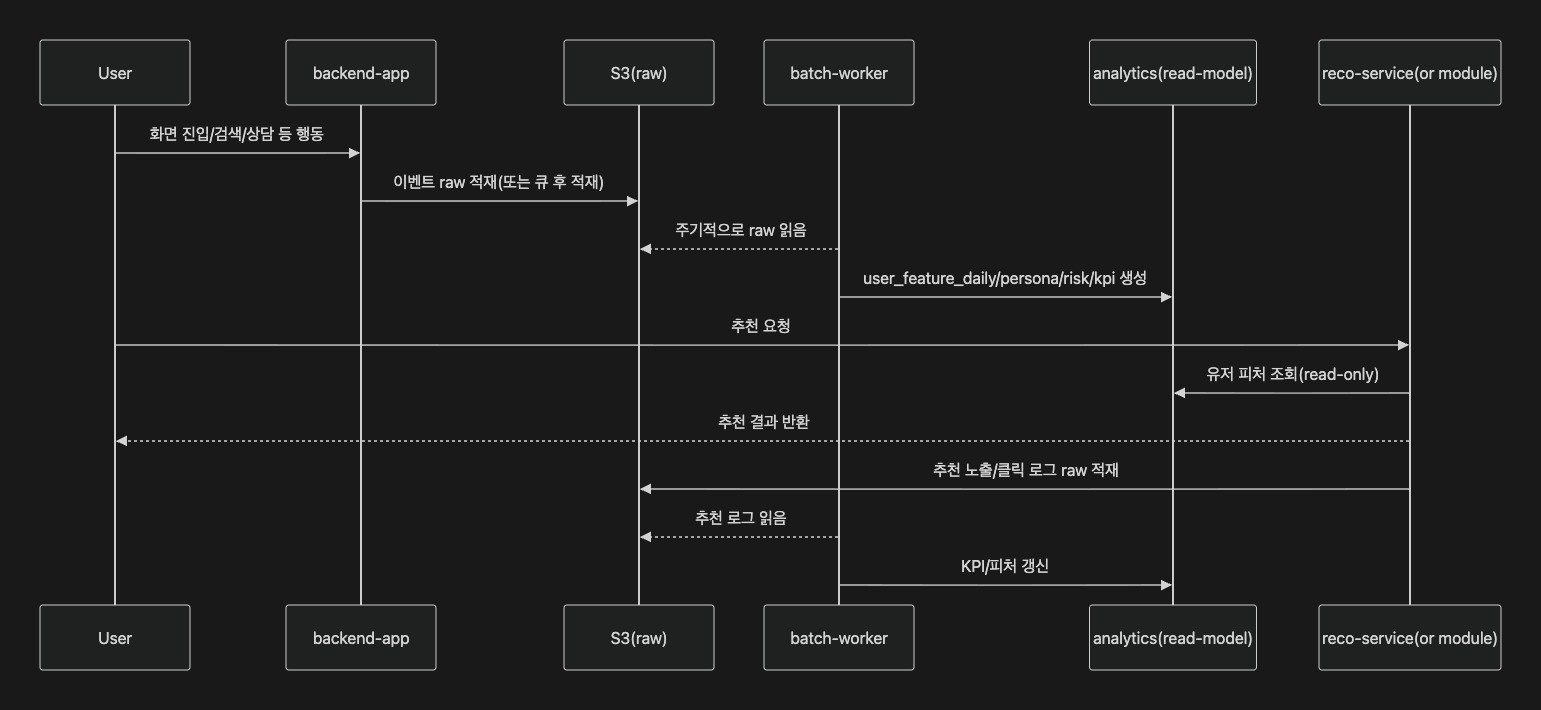
- 추천은 사용자가 요청했을 때 저지연으로 결과를 반환하는 서빙(Serving) 영역
- 분석은 로그+사용자 이용내역+사용자 기본정보를 기반으로 집계와 피처를 생성하여 추천이 읽을 수 있는 read-model을 만들어 주는 생산(Feature/KPI 생산) 영역이라 보았다. 따라서 추천과 분석을 직접 결합시키기보다는, 분석이 생성한 read-model을 추천이 읽는 구조로 분리하는 것이 합리적이라 판단
고민 2. 각 서비스들의 Database 분리와 배포 단위는 어떻게 분리해야 하는가
- 배포 단위는 처음부터 여러 서비스를 상시로 운영하는 방향 보다 상시 런타임은 최소로 두고(비용/운영 부담 감소), **장애 전파 **가능성이 높은 작업(배치/발송)은 런타임을 분리하는 방향으로 정리했다.
- 추천/검색은 트래픽이 튀거나(OpenSearch/Vector Search가 붙는 경우) 장애 가능성이 커지는 시점에 가장 먼저 분리 배포로 승격되는 대상으로 두었다.
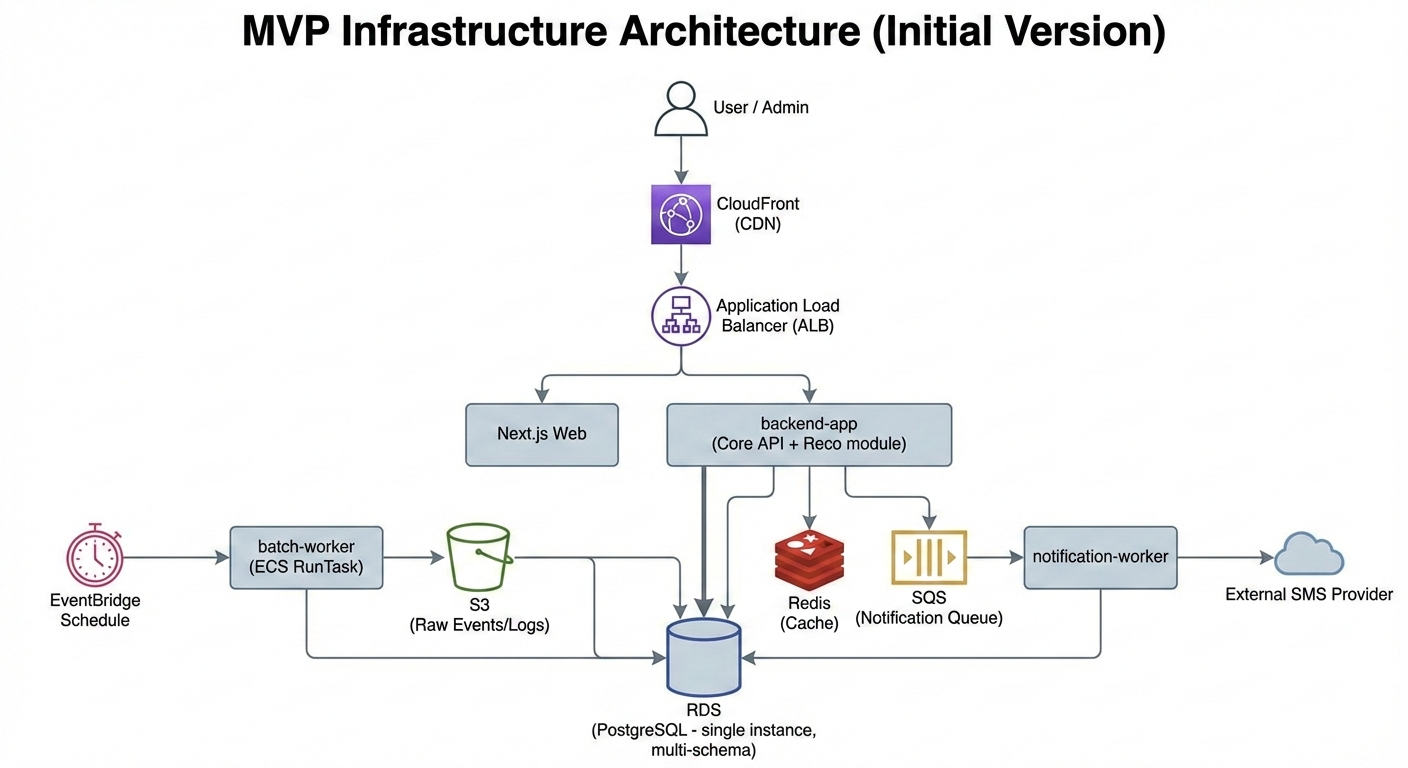
1) MVP
backend-app은 상시로 운영하며 고객 CRUD(로그인/세션), 상담(텍스트), 상품 조회/요금제/혜택, 관리자 API를 포함한다.- 추천 API는 초기에는
backend-app에 포함할 수 있으나, 이후 분리 배포가 가능해야 하므로 코드와 DB 경계는 미리 나누어 두는 방식으로 정리했다.
batch-worker는 상시 운영하지 않고 스케줄 또는 트리거에 의해 실행되며(raw 이벤트 전처리, KPI/통계 생성, 유저 피처 생성, 페르소나/리스크 생성, 추천용 인덱스 갱신을 수행한다).
notification-worker는 상시 운영하지 않거나 최소화하며 큐 기반으로 발송 요청을 처리하고 외부 SMS provider 호출과 재시도, 결과 저장을 수행한다.
프론트는 Next.js를 사용하며 customer/admin은 초기에는 하나의 Next 앱에서 라우팅(/admin)과 권한으로 분리하는 방식으로 운영해 비용과 운영 복잡도를 낮추는 방향으로 정리했다.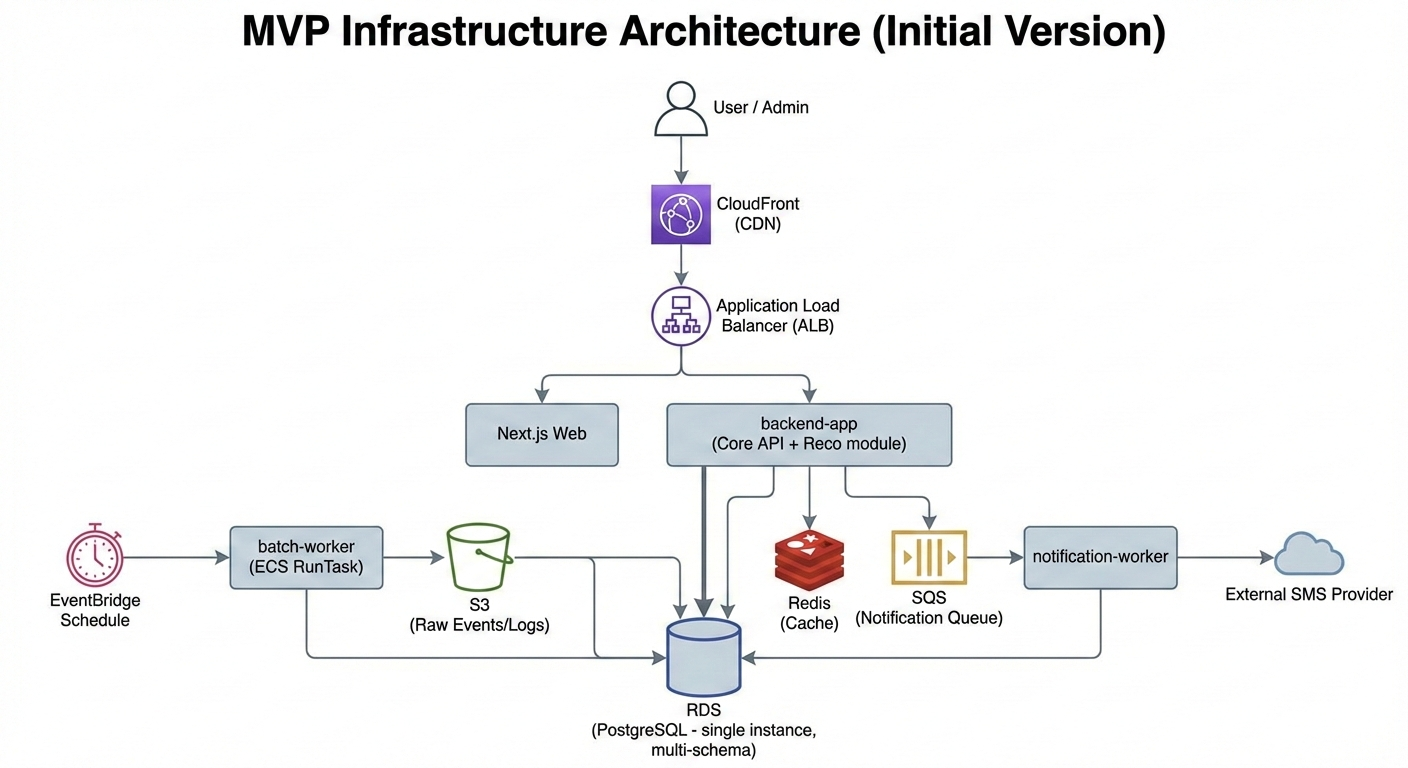
2) 확장
확장 단계에서는 추천/검색이 핫스팟이 되는 경우(호출량 증가, 검색/벡터 인덱스 부하 증가, 추천 장애가 core로 전파되는 리스크 증가)에 한하여 reco-service를 분리 배포 단위로 승격하는 방식으로 했다.
이때 reco-service는 retrieval(키워드/벡터/하이브리드), ranking(가중치 스코어링), 캐시, 추천 로그 적재를 담당하며, 고객 CRUD와 상담을 담당하는 backend-app과 런타임을 분리하여 장애 전파를 차단하는 것이 목적임.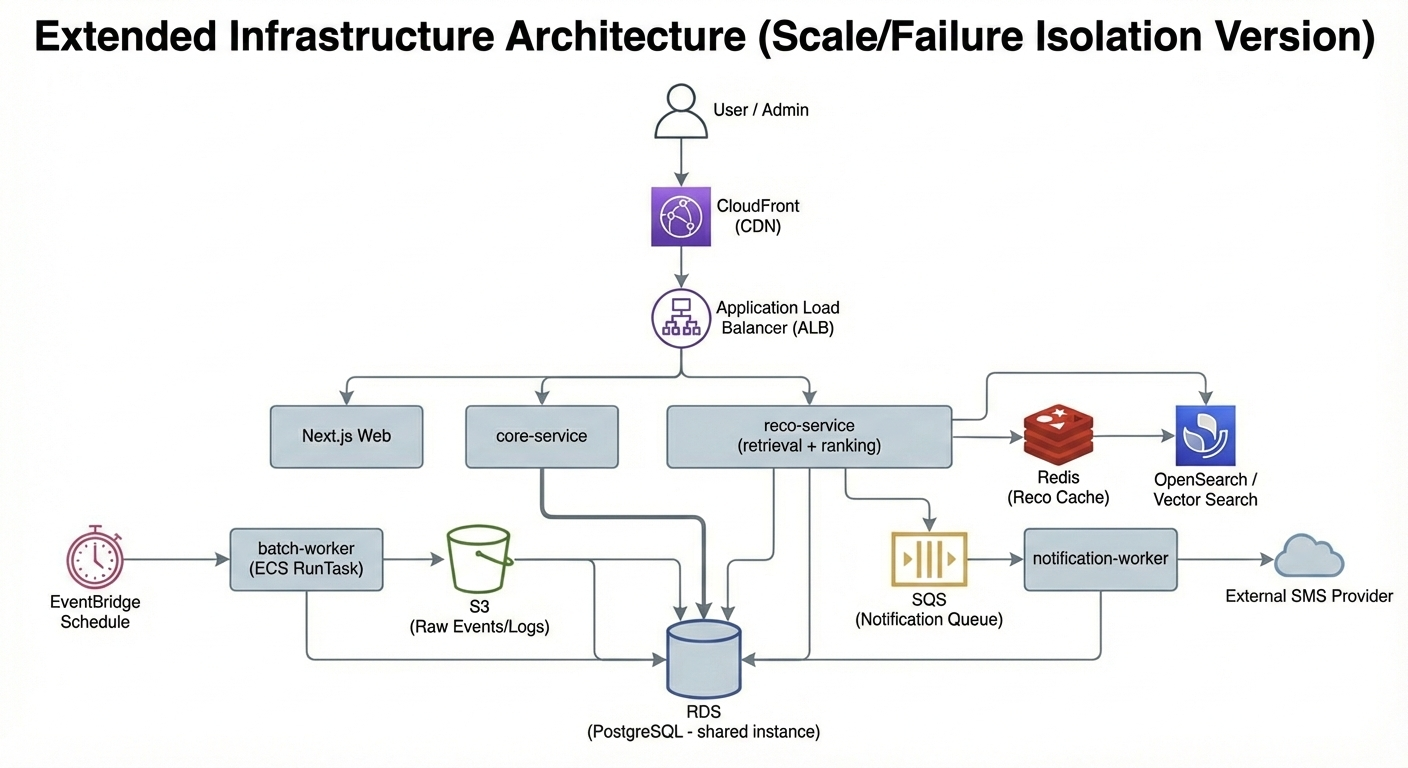
추천과 분석의 연결 방식은 _“직접 조인/직접 결합”_이 아닌 _“분석이 만든 read-model을 추천이 읽는 방식”_으로 정리했다. 즉 이벤트(raw)가 쌓임 → 배치가 이를 집계하여
analytics
영역에 유저 피처/페르소나/리스크/KPI를 생성 → 추천은 이 피처를 읽어서 ranking을 수행하는 구조.
고민 3. 7주 동안의 프로젝트 기간동안 develop 서버(또는 stage 서버)+운영 서버(production) 형태로 배포 시 60만원이라는 제한된 비용 이내로 구축가능한가?
7주 기간 동안 항상 배포를 유지한채로 서버를 유지하지는 않는다. 하지만, 프론트엔드 측에서 렌더링 성능 향상을 위한 프레임 워크로 Next.Js를 선택하였고, Next.Js는 SSR(Sever Side Rendering) 방식을 채택함으로써 AWS에서 구축하려면, ECS 또는 EC2와 같은 인스턴스 유형을 사용해야 한다. 즉, 기존 React.Js 사용 시, S3에 정적 리소스로써 배포하는 비용보다 당연히 부담될 수 밖에 없으며, 고객(customer-web)와 관리자 페이지(admin-web)를 필수적으로 분리함으로써 추가적인 인스턴스 또는 ALB(Application Load Balencer)는 필수적이다. 뿐만 아니라, 추천 알고리즘에 사용되는 벡터DB(어떤 종류인지는 미정)를 사용하여 서버 리소스 비용은 큰 부담으로 다가오며 이는 Infra와 System 설계 단계에서 많은 부담.
여기서 초안에서 “customer-web과 admin-web 분리 시 인스턴스 또는 ALB가 필수”라는 부분은 초기 단계 기준으로는 필수라고 보지 않았다. 초기에는 하나의 Next 앱에서
/admin경로와 권한으로 분리하는 방식으로 운영 가능하다고 판단했다. 이 방식은 서버 런타임을 1개로 유지할 수 있어 비용과 운영 복잡도를 낮추는 데 도움이 된다고 판단하여 필요해지는 시점(**트래픽/배포주기/권한 분리가 더 강하게 필요해지는 시점**)에만 customer/admin을 물리적으로 분리하는 방식으로 정리.
develop 서버를 포기하고 production 서버만을 두는 건 안전하다고 볼 수 있는가?
- production과 develop 서버는 반드시 존재해야 한다고 판단.
- 검증되지 않은 코드가 production에 바로 반영되는 구조는 곧 장애를 내포한 배포 구조라고 판단.
- 다만 develop 환경을 24시간 상시 운영할 필요는 없다고 판단했다. develop은 필요 시에만 올리고 내리는 방식으로 운영 비용을 줄이는 방식이 현실적이라 판단.
- 즉 develop/prod는 분리하되, develop은 상시 고정비를 만들지 않는 방식으로 정리했다. ECS 서비스는 필요 시에만 desired count를 올리고 평상시에는 0으로 유지하는 방식으로 정리했으며, 배치 역시 스케줄을 고정으로 돌리기보다 필요 시 실행하는 방식으로 조정 가능하다고 판단.
RDS 비용은 이전 프로젝트에서의 2개 비용을 직접 체감했는데 비용을 적게 가져갈 수 없을까?
- TR1L 프로젝트에서 DB를 여러 개로 분리했을 때 비용의 상당 부분이 RDS/DocumentDB에서 발생했다고 체감.
- Postgres 기준으로 인스턴스 클래스는 보통
db.t4g.micro가 가장 작은 축이고, 다음 단계로db.t4g.small을 고려하는 흐름이 일반적이라고 정리했다. - 이번 프로젝트에서는 서비스별로 RDS를 추가로 분리하여 DB 수를 늘리는 방식보다, MVP 단계에서 RDS 1개 내부에서 스키마/권한 경계를 강제하는 방식으로 비용을 줄이는 방향을 선택.
- 즉 production용 RDS 1개와 develop용 RDS 1개는 유지하되, “서비스 분리 = RDS 분리”로 바로 이어지지 않도록 정리
- MVP 단계에서는 RDS 1개 내부에서
core/reco/analytics/notification스키마로 분리하고 서비스 계정별 권한을 부여하여 경계를 강제하는 방식으로 정리
DB 분리는 “처음부터 RDS를 여러 개로 쪼개는 방식”이 아니라, MVP 단계에서는 **RDS 1개 내부에서 스키마와 권한 경계를 강제**하여 비용을 낮추는 방식으로 정리.
즉 core, reco, analytics, notification 스키마로 나누고, 서비스별 DB 계정을 분리하여 각 서비스가 자기 스키마에만 쓰기 권한을 가지도록 정리했다. 추천/코어 서비스가 필요한 데이터가 있을 경우에는 analytics가 만들어주는 read-model만 읽도록 하여 결합을 낮추는 방향.
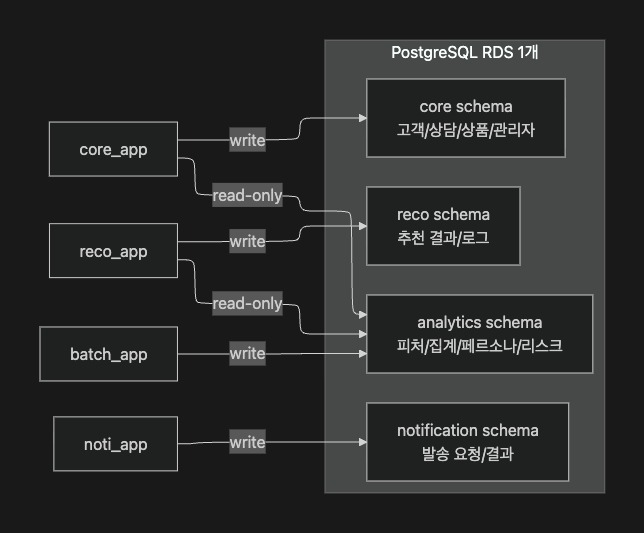
core_app은core에만 write 권한을 가진다.reco_app은reco에만 write 권한을 가진다.batch_app은analytics에 write 권한을 가진다.reco_app은core에 대한USAGE권한을 가지지 않아core.*조회 자체가 불가능하다.analytics_read는analyticsread-model에 대해서만 SELECT 권한을 가진다.
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA core TO core_app;
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA reco TO reco_app;
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA analytics TO batch_app;
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA notification TO noti_app;
-- 앞으로 생성될 테이블도 자동으로 권한 부여
ALTER DEFAULT PRIVILEGES IN SCHEMA core
GRANT SELECT, INSERT, UPDATE, DELETE ON TABLES TO core_app;
ALTER DEFAULT PRIVILEGES IN SCHEMA reco
GRANT SELECT, INSERT, UPDATE, DELETE ON TABLES TO reco_app;
ALTER DEFAULT PRIVILEGES IN SCHEMA analytics
GRANT SELECT, INSERT, UPDATE, DELETE ON TABLES TO batch_app;
ALTER DEFAULT PRIVILEGES IN SCHEMA notification
GRANT SELECT, INSERT, UPDATE, DELETE ON TABLES TO noti_app;
-- sequence 권한
ALTER DEFAULT PRIVILEGES IN SCHEMA core
GRANT USAGE, SELECT, UPDATE ON SEQUENCES TO core_app;
ALTER DEFAULT PRIVILEGES IN SCHEMA reco
GRANT USAGE, SELECT, UPDATE ON SEQUENCES TO reco_app;
ALTER DEFAULT PRIVILEGES IN SCHEMA analytics
GRANT USAGE, SELECT, UPDATE ON SEQUENCES TO batch_app;
ALTER DEFAULT PRIVILEGES IN SCHEMA notification
GRANT USAGE, SELECT, UPDATE ON SEQUENCES TO noti_app;
고민 4. 이전 프로젝트에서 여러 번 시도하였지만 실패하였던 DDD 중심의 아키텍처의 적용
이번 프로젝트 요구사항을 분석하던 중 도메인 모델의 확장성을 고려하며 배포 단위를 고려했을때 DDD+모듈러 모노리스식이 가장 적합하다고 판단한다. 이유는 아래와 같다.
- 트래픽이 몰리는 지점이 다르므로(추천/분석 부분에서의 로그 수집 VS 클라이언트의 일반 사용 트래픽 부하) 배포 단위를 분할하고 스케일 범위를 다르게 가져가야 함.
- 배치 시스템은 비교적 많은 CPU 자원과 Disk I/O가 발생하므로 다른 서비스와 같이 DB 및 인스턴스 공유 시 다른 서비스의 장애는 분명하다.(장애 전파 가능성)
- 기능 명세서를 작성하기 이전 이벤트 스토밍은 아니지만 요구 사항 정의를 위해 포스트를 붙여가며 진행한 요구사항 추출과정에서 추천+분석+발송 이라는 명확한 도메인 모델의 추출
총 3번의 DDD 기반의 architecture 적용 시도와 완전 실패 및 부분 실패
- DDD 기반 아키텍처 적용 시도는 총 3번 있었고, 실패 원인은 항상 동일했다. 아키텍처를 제안한 사람은 나였고, 나 자신도 완벽히 공부하지 못한 상태에서 “다 같이 공부하면서 모델링하고 구현하면 되겠다”는 생각으로 접근했다.
- 하지만 실제 프로젝트는 설계/구현/테스트 외에도 명세서 작성과 발표 자료 구성, 예상하지 못한 에러 대응 등 부가 작업이 많았고, 이 과정에서 학습에 시간을 충분히 투자하지 못했다.
- 결과적으로 내가 주도하며 이해를 먼저 해야 했으나 러닝 커브를 감당하지 못했고, 팀원 역시 레이어드 아키텍처 경험이 중심이어서 DDD+모듈러 모노리스는 이번 프로젝트에서도 높은 러닝 커브를 만든다고 판단했다.
결론:
- DDD 적용이 아니라, 레이어드를 기본으로 두고 변화 가능성이 큰 지점만 Port로 분리하는 구조를 적용하는 것으로 판단.
- 추천에서 후보군을 가져오는 방식은 SQL 기반에서 OpenSearch/Vector로 바뀔 수 있다고 판단했고, 이 지점은 **인터페이스(Port)**로 분리하여 **구현체(Adapter)**를 교체하는 방식으로 판단.
- 이벤트 적재(S3/SQS), SMS 발송 provider, 캐시(Redis) 등 외부 연동도 동일하게 Port/Adapter로 분리하는 방식으로 정리했다. 이 방식은 레이어드 기반 개발 경험을 유지하면서도, 확장 단계에서 reco-service 분리나 검색/벡터 엔진 교체를 가능하게 하는 최소한의 유연성을 제공한다고 판단.
REST API 구현이니깐 모두 JPA를 사용하면 될까?
결론부터 말하면 “모두 JPA”로도 구현은 가능하다(아마?). 다만 우리 서비스 모델(추천/분석/배치/로그 집계가 핵심)에서 내가 판단하였을 때 SW에서 가능”과 “좋다”는 엄연히 다르다. JPA를 전부에 적용하면, 개발 속도는 초반에 확실히 빨라 보이지만 배치·집계·랭킹 쿼리에서 성능/예측 가능성/디버깅 비용이 급격히 올라갈 가능성이 크다.(쿼리 튜닝 힘듦/다중 조인 및 집계 어려움/양방향 매핑)
⇒ JPA / Querydsl / jOOQ / JDBC를 비교한 내용이다.(참고로 이미 기능 자체가 매우 hard한 주제이므로 최대한 러닝 커브가 낮다고 판단하는 선에서 선정 ex) Mybatis같은 경우는 xml 형태로 구성되기 때문에 제외했다.)
1) JPA
장점
- 생산성이 높다. 엔티티 기반으로 CRUD가 빠르게 나온다.
- 트랜잭션 단위에서 변경 감지(dirty checking)로 도메인 로직 구현이 편하다.
- 관계 매핑으로 “비즈니스 규칙”을 코드에 담기 쉽다(특히 core 영역).
단점
- 대량 처리/집계/벌크 업데이트에 약하다.
- 대량 INSERT/UPDATE는 영속성 컨텍스트, flush/clear, batch size 튜닝 등 “JPA식 최적화”가 필요하다.
- 벌크 update는 영속성 컨텍스트와 불일치가 발생해 운영 사고 포인트가 생긴다.
- 복잡한 SQL(윈도우 함수, CTE, 세밀한 조인 전략)을 끌고 가기 어렵다. → 결국 Native Query로 작성해야함.
- 추천/분석은 결국 “데이터를 계산”해야 하는데, 이때 ORM 추상화가 오히려 장애물이다.
- 성능이 “코드만 봐서는” 예측이 안 되는 경우가 많다(N+1, 지연 로딩, 예상치 못한 쿼리 폭발).
JPA vs Mybatis, 현직 개발자는 이럴 때 사용합니다. I 이랜서 블로그
| [Hibernate Core Reference Guide | Red Hat JBoss Web Server | 3 | Red Hat Documentation](https://docs.redhat.com/en/documentation/red_hat_jboss_web_server/3/html-single/hibernate_core_reference_guide/index#d0e340) |

적합한 곳(우리 기준)
core스키마: 로그인/세션, 고객 CRUD, 상담 기록, 상품/요금제(카탈로그) 같은 OLTP 트랜잭션성 CRUD- 관리자 영역도 “CRUD + 간단 통계” 수준이면 JPA로 충분.
2) Querydsl
장점
- 동적 필터 검색을 타입 세이프하게 만들기 좋다(조건이 많아질 때).
- JPA와 같이 쓰면 팀 입장에서 러닝커브가 낮다
- 컴파일 타임에 필드 오타가 잡혀서 유지보수성이 좋아진다.
단점
- 결국 기반은 JPA라서 집계/배치의 한계는 그대로 남는다.
- 복잡한 분석용 SQL(CTE/윈도우 함수 중심)로 가면 Querydsl로 “가능은 한데 보기 어렵거나” “결국 native SQL”로 돌아가기 쉽다.
적합한 곳(우리 기준)
core에서 “필터링 검색(특징별 검색 → SQL)” 같은 부분- 관리자 화면에서 조건이 많은 조회(기간/상담유형/요금제/세그먼트 등)
3) jOOQ
장점
- SQL을 그대로 쓰면서도 타입 세이프하고(코드 생성), IDE 지원이 강하다.
- 실행되는 쿼리가 명확해서 성능 예측/디버깅/튜닝이 쉬웠다.
- 분석/집계에서 자주 쓰는 패턴(CTE, 윈도우 함수, upsert, 복잡 조인)을 자연스럽게 표현한다.
- “우리가 DB 권한/스키마로 경계 강제”하려는 설계에 적합.
단점
- 엔티티 기반 도메인 모델링(JPA 느낌)은 약하다. (그냥 SQL 중심)
- 코드 생성/스키마 변경 관리(Flyway와 연계)가 필요해서 셋업이 들어간다.
- 팀원이 SQL에 익숙하지 않으면 초기 러닝커브가 생긴다.
적합한 곳(우리 기준)
analytics스키마: 피처 테이블 생성, 페르소나/리스크 집계, KPI 산출reco스키마: 추천 로그 기반 집계, 랭킹 계산에 필요한 조합 조회- “배치/집계 중심 워크로드” 전반
4) JDBC
장점
- 오버헤드가 적고 단순해서 대량 INSERT/UPDATE에 유리하다.
- Spring Batch와 조합할 때 chunk 기반 처리에 잘 맞는다.
- 실행되는 SQL이 명확하고, 커서/스트리밍 같은 제어를 직접 하기 쉽다.
단점
- 타입 세이프가 약하고, 쿼리 문자열 관리가 부담이다.
- 복잡 쿼리는 jOOQ 대비 유지보수성이 떨어지기 쉽다(문자열 지옥).
- 매핑/에러 처리/코드 중복이 늘어날 수 있다.
적합한 곳(우리 기준)
- 이벤트 raw 적재(대량 insert), 배치성 bulk write
- Spring Batch에서 DB writer를 단순하게 가져갈 때
결론
-
성능/운영 관점
- 추천/분석은 “데이터 계산”이 많다 → SQL 튜닝 지점이 명확해야 운영이 된다.
- JPA는 쿼리가 간접적으로 생성되어 병목 원인 추적이 느려질 가능성 존재.
- 배치에서 대량 처리하면 flush/clear, batch size, fetch 전략 등 ORM 최적화 지식이 필요해져 러닝커브가 다시 생김.
-
팀 러닝커브 관점
- “JPA만”은 초반엔 편하지만, 결국 집계/추천 로직에서 native SQL이 늘어나며
- “JPA + 네이티브 혼합”으로 복잡도가 올라갈 가능성 존재
- 차라리 분석/배치는 처음부터 SQL 도구(jOOQ/JDBC) 로 통일하는 편이 좋다고 판단.
-
아키텍처/결합도 관점(우리가 중요하게 본 부분)
- DB를
core/reco/analytics/notification스키마로 나누고 권한으로 경계를 강제한다면,- core : JPA로 엔티티 중심
- analytics : jOOQ/JDBC(대량 적재에는)로 read-model 생성
- reco : DB 조회/랭킹 쿼리 jOOQ
- notification : 명확한 SQL/락/outbox 패턴 중요
- writer(발송요청 저장): JPA(단순 INSERT)
- dispatcher(대량 조회/선점/상태변경/재시도): jOOQ 또는 JDBC