[ 주요 생각 포인트 ]
- 외부 공개는 최소화하고 각 계층의 책임은 인프라, 어플리케이션 계층에서 확실하게 분리한다.
- Customer Web에 트래픽이 몰리더라도,Admin Web에서의 흔들림은 없어야 한다.
- Admin Web은 관리자 페이지로 항상 폐쇄된 환경에서만 사용이 가능해야 하고, 외부에 접근은 불가하도록 설계해야 한다.
1차 MVP 예상 Architecture
Network Architecture
개요
한 줄 요약
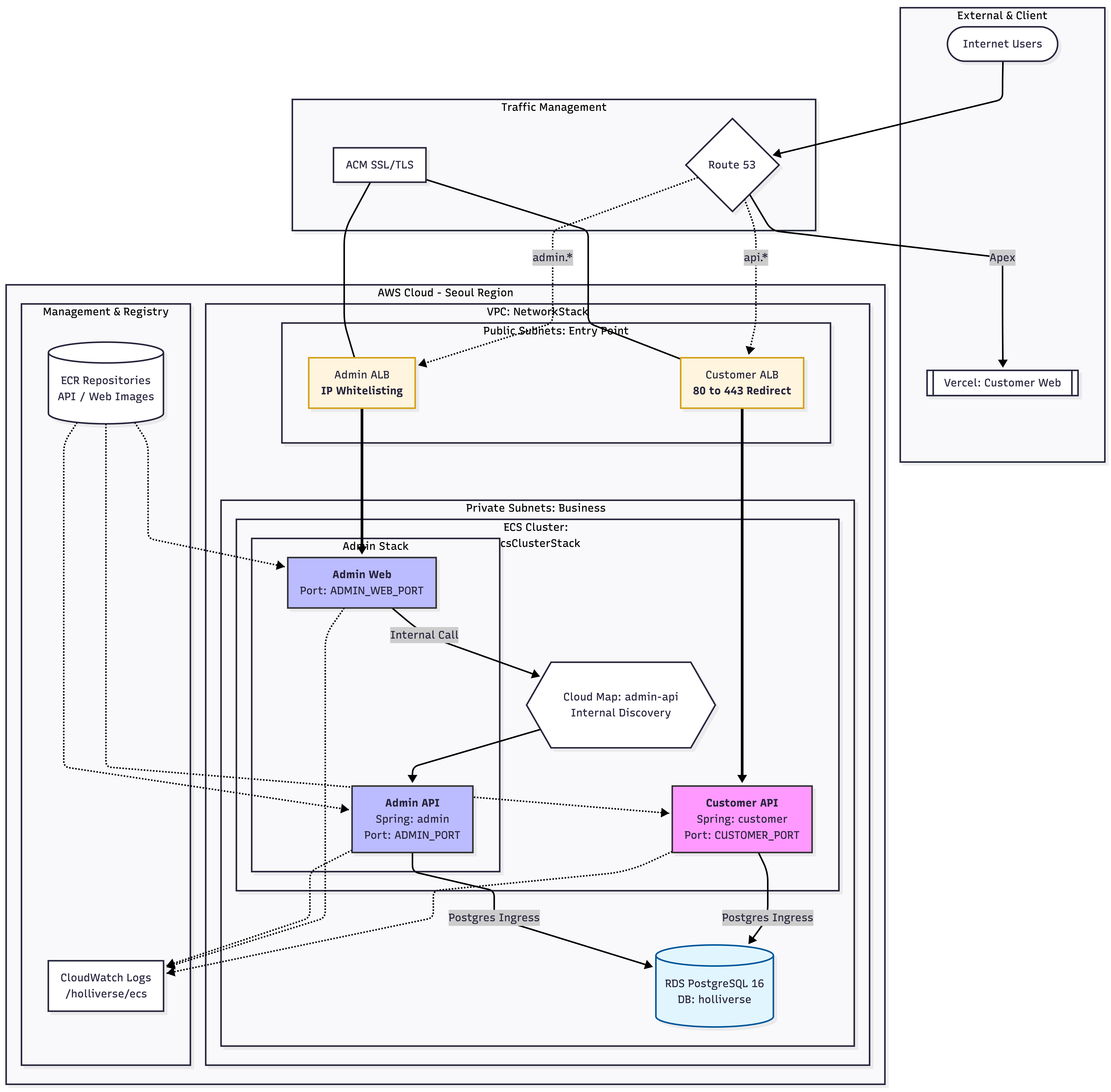
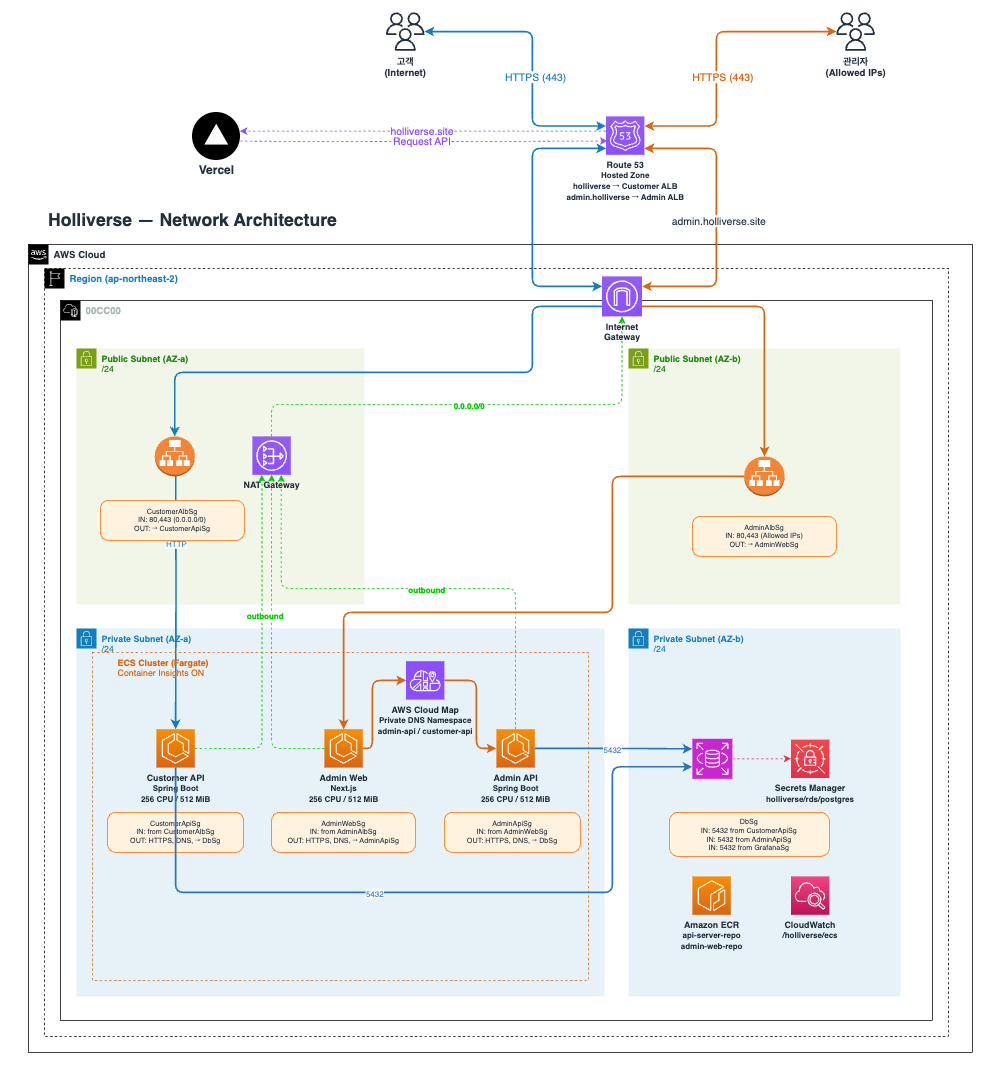
이 인프라의 네트워크는 고객 웹은 Vercel, 운영 및 비즈니스 API는 AWS에 두고, AWS 내부 자원은 public edge와 private workload를 명확히 분리한 구조이다. 외부에 직접 노출되는 자원은 DNS와 ALB 수준으로 최소화하고, 실제 애플리케이션과 데이터 계층은 모두 VPC 내부에서만 통신하도록 설계했다. <h3 style="display:block; width:100%; background:#475569; color:#F8FAFC; padding:6px; border-radius:6px;">상세 구조</h3> <h4 style="display:block; width:100%; background:#64748B; color:#F8FAFC; padding:6px; border-radius:6px;">1. 외부 진입 구조와 도메인 분리</h4> 루트 도메인은 Vercel로 연결되고, AWS로 들어오는 트래픽은 서브도메인으로 분리된다. `api.
즉 외부에서 직접 접근 가능한 자원과 내부에서만 동작해야 하는 자원을 subnet 단계에서 먼저 분리한 구조이다.
3. Customer 트래픽 경로
고객 사용자는 루트 도메인으로 접속하면 Vercel에 도달하고, API 호출은 `api.
또한 Customer API는 ALB를 통해서만 접근 가능하도록 Security Group이 구성되어 있다. 따라서 외부에서 애플리케이션 컨테이너로 직접 진입하는 경로는 차단되고, 인터넷 → ALB → Customer API 흐름만 허용된다.
4. Admin 트래픽 경로
관리자 영역은 고객 영역보다 더 강하게 제한된다. Admin ALB는 public subnet에 위치하지만, 인바운드는 `ADMIN_ALLOWED_CIDRS`에 포함된 허용 IP 대역에서만 받을 수 있다.
흐름은 admin.<domain> → Admin ALB → Admin Web ECS → Admin API ECS 구조이며, Admin API는 외부에 직접 노출되지 않는다. 즉 관리자 시스템은 공개 서비스가 아니라, 제한된 네트워크에서만 접근 가능한 폐쇄형 운영 콘솔에 가깝게 설계했다.
5. ECS 내부 서비스 통신
ECS 클러스터는 private subnet에 배치되고, 서비스 간 호출은 Cloud Map 기반 private DNS를 사용한다. 이를 통해 Admin Web, Admin API, Customer API 같은 서비스는 외부 로드밸런서를 거치지 않고 VPC 내부에서 통신할 수 있다.
이 구조는 고객-facing 서비스와 내부 운영 계층을 분리하고, 외부 공개가 필요하지 않은 호출을 내부 네트워크로만 제한하는 데 유리하다.
6. Security Group 분리 전략
이 네트워크의 핵심은 Security Group을 서비스 역할 단위로 세분화한 점이다. Customer ALB, Customer API, Admin ALB, Admin Web, Admin API, DB를 각각 독립적으로 분리해 두었다.
이렇게 하면 단순히 같은 VPC 안에 있다는 이유만으로 서로 통신할 수 없고, 누가 누구에게 어떤 포트로 접근할 수 있는지를 명시적으로 제어할 수 있다. 즉 네트워크 레벨에서 최소 권한 원칙을 적용해 불필요한 서비스 간 접근 가능성을 줄인 구조이다.
7. 데이터 계층 네트워크: RDS
RDS는 private subnet에 배치되며 `publiclyAccessible(false)`로 설정되어 외부에서 직접 접근할 수 없다. DB 접근은 Customer API와 Admin API처럼 허용된 애플리케이션 계층에만 제한된다.
즉 데이터베이스는 ALB 뒤 애플리케이션보다도 더 안쪽에 위치하며, 관리자 웹이나 외부 인터넷과는 직접 연결되지 않는다. 운영 데이터 보호를 전제로 한 폐쇄형 데이터 계층 구조이다.
정리
핵심 설계 요약
이 프로젝트의 네트워크는 고객 웹, 운영 시스템, 데이터 계층을 명확히 분리하는 방향으로 설계했다. 고객 웹은 Vercel로 분리하고, AWS에는 API와 운영 계층만 남겨 트래픽 경로와 배포 책임을 나누었다.
CI/CD Architecture
[ 주요 생각 포인트 ] 각 흩어져 있는 레포지토리의 CI/CD는 중앙 레포지토리인 ‘infra’ 레포지토리에서 담당한다. 즉, “각 서비스는 독립적으로 개발하고 테스트하지만 배포와 릴리즈 관리는 중앙 통제형 파이프라인으로 일관되게 운영해야 한다.” 이 구조를 통하여 서비스별 자율성과 운영 통제성을 확보할 수 있다.
1. CI 단계: PR에서 품질과 배포 의도 검증
1-1. 브랜치 및 커밋 정책 검증
첫 번째 게이트는 협업 (컨벤션/브랜치 규칙 통일)규칙 검증이다.
- 각 레포지토리에 husky를 이용하여 ‘[HSC-티켓 번호]
: commit message' 형식 검증. - 브랜치명은
/ 형식 검증.
- 브랜치명은
1-2. 배포 라벨 검증
릴리즈 의도 검증이다. 배포 전용 PR template를 사용하는 경우, PR 본문에서 다음 중 정확하게 하나만 선택되어야 한다.
- release:major
- release:minor
- release:patch
선택된 값은 실제 Github PR Label과 동기화되며, 이후 CD 단계에서 semver 증가 기준으로 직접 사용된다.
릴리즈 수준을 사람의 합의나 수동 판단에 의존하지 않고 PR 메타데이터 자체를 배포 입력값으로 표준화한다.
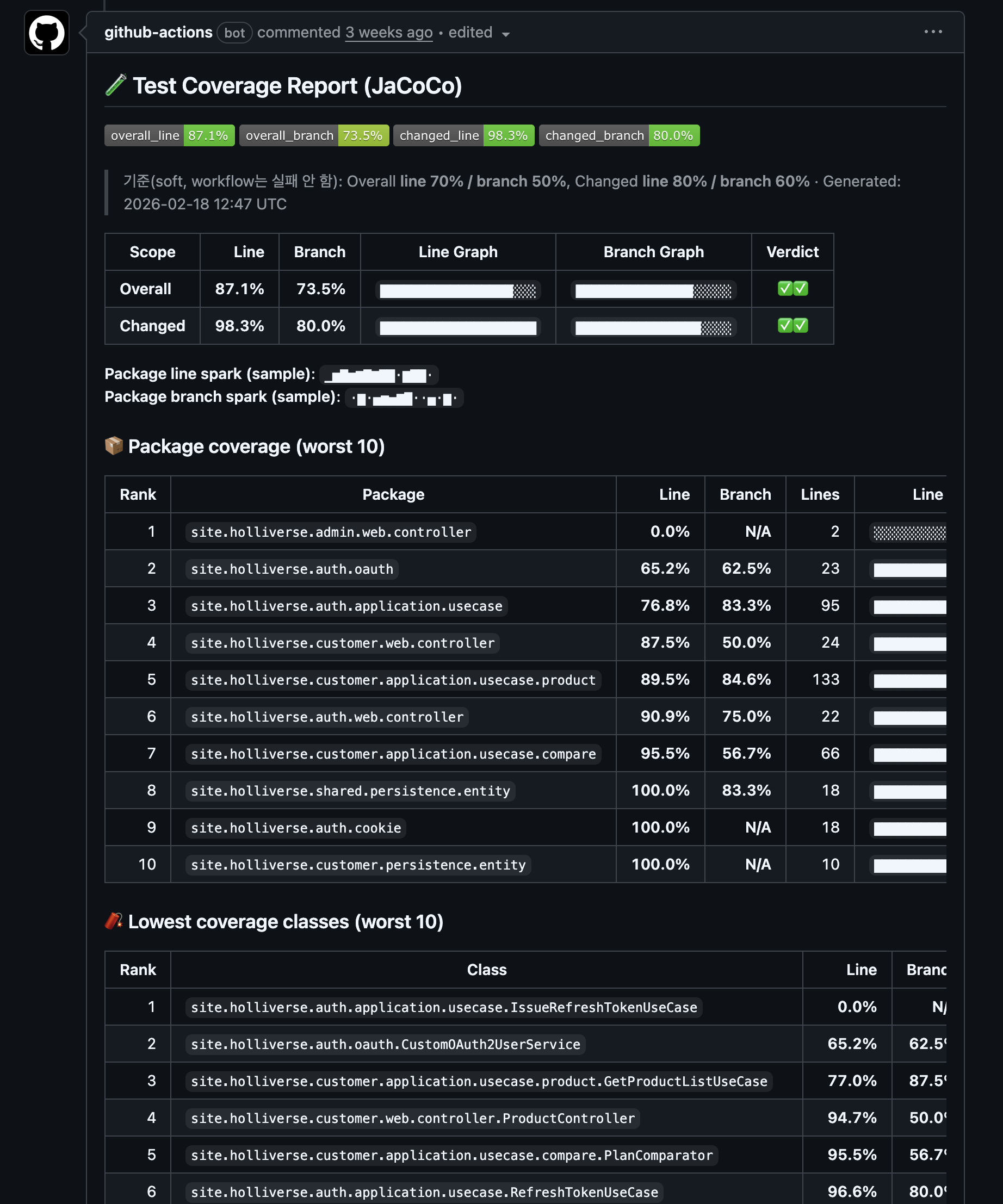
1-3. 테스트 및 커버리지 검증
실행 가능한 환경 기반의 테스트 검증이다. infra 레포지토리에 PR이 생성되면 재사용 가능한 Jacoco workflow를 호출한다. 해당 workflow는 다음 과정을 포함한다.
- Postgres 컨테이너 실행
- Flyway 실행을 위한 DB 역할 생성
vectorextension 등 테스트 실행에 필요한 DB 환경 준비- Gradle 기반 테스트 수행
- JaCoCo HTML/XML 커버리지 리포트 생성
- 결과 artifact 업로드
- PR 변경 파일 기준 changed coverage 계산 및 코멘트 가능 형태로 가공
이 방식은 단순히 단위 테스트만을 통과시키는 것이 아니라 DB 의존성을 추가하여 실제 실행 환경에서의 품질을 검증할 수 있다.
**_<실제 workflow="" 모습="">_**
2. CD 단계: 라벨 기반 중앙 릴리즈 오케스트레이션
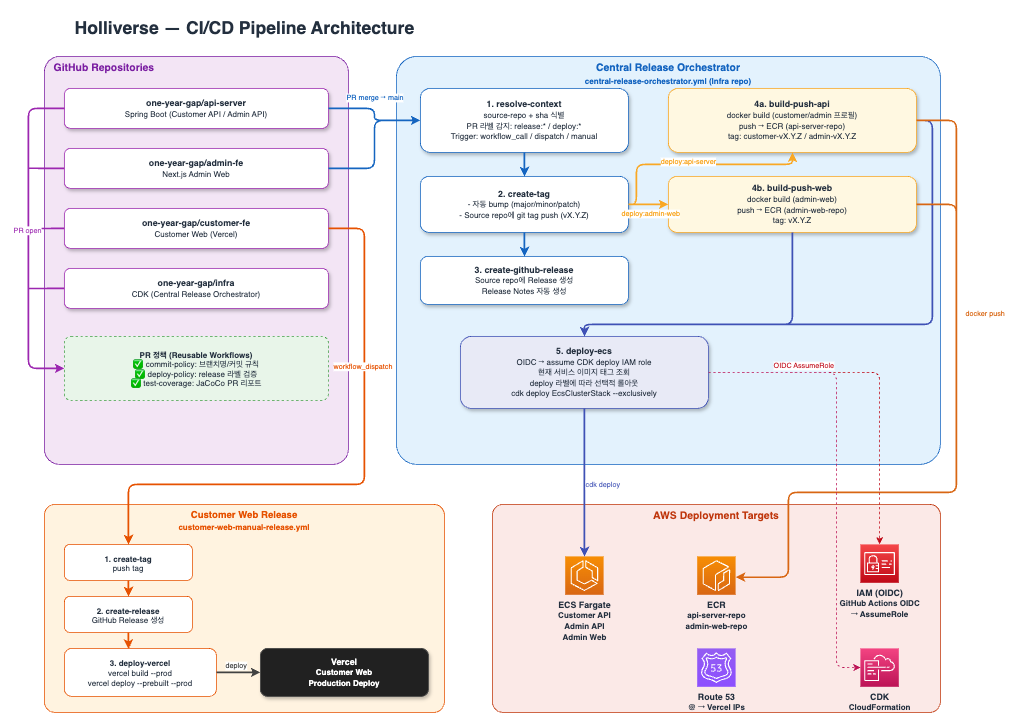
이 프로젝트의 CD는 멀티 리포 환경에서 중앙 오케스트레이터가 릴리즈와 배포를 통제하는 구조이다. 서비스별 개발은 독립적으로 이루어지지만, 실제 배포는 `infra` 레포의 공통 워크플로우를 통해 일관되게 수행된다.
Release Trigger
1. Release Trigger
CD는 workflow_call, repository_dispatch, workflow_dispatch 중 하나로 시작된다. 즉 자동 호출, 외부 레포 요청, 운영자 수동 실행을 모두 지원하는 구조이다.
2. Resolve Context
가장 먼저 source repo, source SHA, release level, deploy labels를 해석한다. 이 단계에서 어떤 서비스를 어떤 버전 수준으로 배포할지가 결정된다.
3. Customer Web 여부 분기
배포 대상이 customer-web인지 먼저 판별한다. 이 서비스는 ECS가 아니라 Vercel에 배포되므로 일반 서비스와 배포 경로를 분리한다.
Customer Web 경로
4. customer-web-manual-release
customer-web인 경우 전용 릴리즈 워크플로우로 이동한다. 이는 Vercel 기반 프론트엔드의 플랫폼 특성을 반영한 별도 경로이다.
5. Create SemVer Tag
source repo에 semver 태그를 생성한다. 버전 책임은 중앙 infra가 아니라 실제 소스 레포에 귀속되는 구조이다.
6. Create GitHub Release
같은 레포에 GitHub Release를 생성한다. 이를 통해 버전뿐 아니라 릴리즈 이력도 함께 관리한다.
7. Vercel pull
Vercel 프로젝트 설정과 배포 컨텍스트를 불러오는 단계이다.
8. Vercel build --prod
운영 배포용 결과물을 프로덕션 모드로 빌드하는 단계이다.
9. Vercel deploy --prebuilt --prod
사전 빌드된 결과물을 실제 운영 환경에 배포하는 단계이다.
일반 서비스 경로
10. Create Tag
customer-web이 아니면 일반 서비스 경로로 들어가 source repo에 semver 태그를 생성한다. 필요 시 서비스별 태그 네임스페이스도 분리하여 관리한다.
11. Create GitHub Release
릴리즈 태그 기준으로 GitHub Release를 생성한다. 이 단계에서 release label, deploy label 같은 메타데이터도 함께 남긴다.
12. Start Service Image Jobs
이후 서비스별 이미지 빌드 작업이 병렬로 시작된다. 배포 시간을 줄이기 위한 구조이다.
13. api-server Build & Push
api-server는 DB 초기화 조건까지 고려해 이미지를 빌드한다. 동일 소스에서 고객용과 관리자용 이미지를 각각 만들어 ECR에 푸시한다.
14. admin-web Build & Push
admin-web은 단일 이미지를 빌드하여 ECR에 푸시한다. 프론트엔드이지만 ECS에서 운영되므로 일반 서비스 경로에 포함된다.
15. worker Build & Push
worker 이미지를 빌드해 ECR에 푸시한다. 필요 시 ECR 리포지토리도 자동 생성한다.
16. counseling-analytics Build & Push
counseling-analytics 이미지도 빌드 후 ECR에 푸시한다. 이후 실시간 서비스인지 배치용인지에 따라 후속 반영 방식이 달라진다.
17. Deploy ECS
빌드가 끝나면 ECS 반영 단계로 이동한다. 이때 전체 재배포가 아니라 이번 릴리즈 대상 서비스만 새 태그로 교체하고, 나머지는 기존 운영 태그를 유지한다.
18. Optional Post-deploy Branches
ECS 반영 후에는 서비스 특성에 따라 추가 분기가 실행된다. 즉 이미지 반영 이후에도 worker 실행 검증이나 실시간 서비스 안정화 같은 후속 절차가 이어진다.
Worker 분기
19. deploy:worker 확인
deploy:worker 라벨이 있을 때만 worker 후속 절차를 수행한다.
20. Register Worker Task Definition
새 이미지 기준으로 worker task definition revision을 등록한다.
21. CI_RUN_WORKER_TASK 확인
설정값이 true이면 실제 task를 실행하고, 아니면 revision만 등록한다.
22. ECS Run Task
실행 모드인 경우 ecs run-task로 worker를 실제 기동한다.
23. Verify Worker Task
task가 종료될 때까지 기다린 뒤 exit code를 확인한다. 즉 worker는 배포 후 실제 실행 성공 여부까지 검증하는 구조이다.
24. Skip Execution
실행이 비활성화된 경우에는 새 revision만 유지하고 종료한다.
Recommendation Realtime 분기
25. deploy:recommendation-realtime 확인
실시간 추천 서비스 배포 여부를 확인한다.
26. Update Counseling Analytics ECS Service
해당 라벨이 있으면 counseling analytics ECS service의 task definition을 새 이미지로 교체한다.
27. Wait Services Stable
배포 후 services-stable 상태까지 기다려 실제 서비스 안정화를 확인한다.
Counseling Batch 분기
28. deploy:counseling-batch only 확인
배치 전용 배포인지 판별한다.
29. Register Batch Task Definition Revision
배치 전용인 경우 새 task definition revision만 등록한다. 즉 상시 서비스 반영이 아니라, 이후 실행 가능한 상태만 준비하는 구조이다.
30. Release Completed
모든 분기가 끝나면 릴리즈가 완료된다.
즉 이 CD는 태그 생성, Release 기록, 이미지 빌드, ECS 반영, 필요 시 task 실행 검증까지 포함하는 운영 파이프라인이다.
Monitoring Architecture
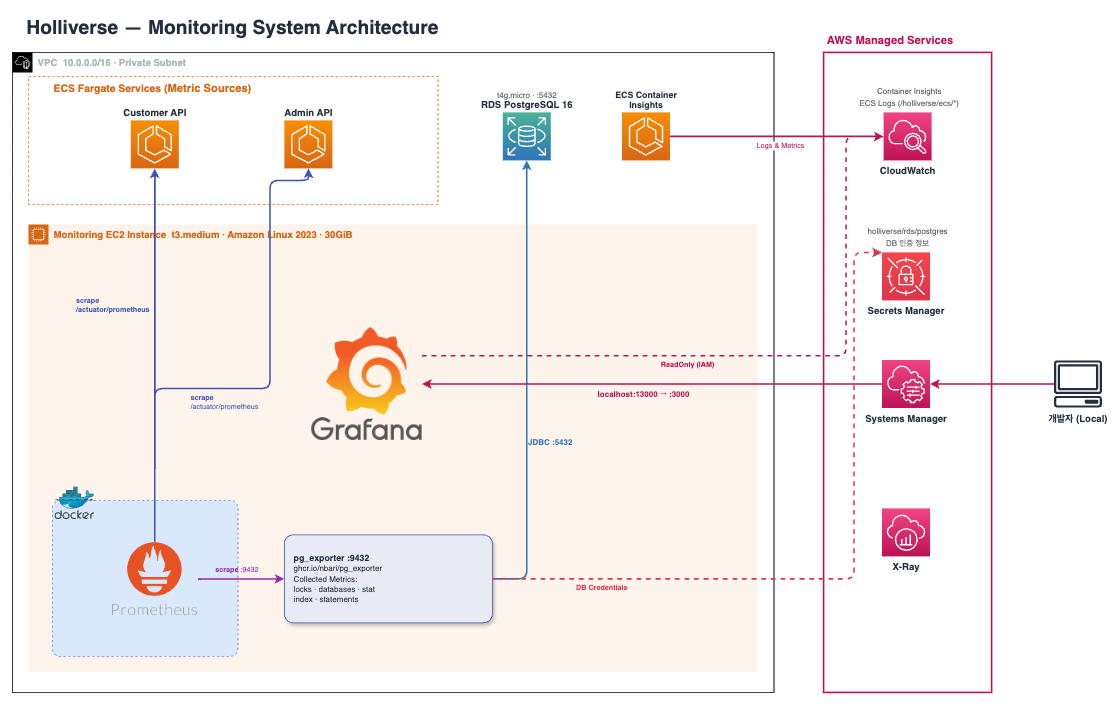
Monitoring Architecture
개요
한 줄 요약
이 프로젝트의 모니터링 시스템은 전용 EC2 위에 Grafana와 Prometheus 계열 구성요소를 올리고, CloudWatch를 함께 연동해 애플리케이션, 데이터베이스, AWS 인프라 메트릭을 한 곳에서 통합적으로 확인할 수 있도록 설계했다. <h3 style="display:block; width:100%; background:#475569; color:#F8FAFC; padding:6px; border-radius:6px;">상세 구조</h3> <h4 style="display:block; width:100%; background:#64748B; color:#F8FAFC; padding:6px; border-radius:6px;">1. 전체 구조</h4> 모니터링 전용 EC2를 하나 두고, 그 안에서 Grafana와 Prometheus 계열 구성요소를 운영하는 구조이다. 중요한 점은 이 인스턴스가 public으로 직접 노출되지 않는다는 것이다. 운영자는 외부에서 바로 Grafana 포트에 접속하는 것이 아니라, SSM Port Forwarding을 통해서만 접근한다.
즉 모니터링 시스템 자체를 내부망에 두고, 접근 경로는 AWS 관리 채널로 제한한 구조이다. 이 EC2는 VPC 내부에서 Admin API, Customer API, RDS에 접근할 수 있도록 구성되어 있으며, 이 자원들로부터 메트릭을 수집한다.
2. 구성 요소별 역할
Grafana는 최종 대시보드 역할을 담당한다. 메트릭을 직접 저장하지 않고, Prometheus와 CloudWatch를 데이터소스로 연결해 시각화한다. Prometheus는 애플리케이션과 데이터베이스 메트릭을 수집하는 수집기 역할을 한다.
pg_exporter는 PostgreSQL 상태를 Prometheus가 읽을 수 있는 형태로 변환하는 exporter이다. DB 접속 정보는 하드코딩하지 않고, 부팅 시 Secrets Manager에서 읽어 동적으로 구성한다. CloudWatch는 AWS 관리형 인프라 메트릭을 제공하며, Grafana는 EC2 IAM Role을 통해 이를 조회한다.
즉 Grafana는 보는 창, Prometheus는 수집기, pg_exporter는 DB 메트릭 변환기, CloudWatch는 AWS 인프라 메트릭 공급원 역할을 한다.
3. 메트릭 수집 흐름
메트릭 수집 흐름은 크게 세 갈래이다.
- 애플리케이션 메트릭은 Admin API와 Customer API의 actuator/prometheus 엔드포인트에서 수집한다. 이를 통해 요청 수, 응답 시간, 에러율, JVM, GC, 커넥션 풀 상태 같은 애플리케이션 메트릭을 확인할 수 있다.
- 데이터베이스 메트릭은 pg_exporter가 RDS에 접속해 PostgreSQL 상태를 수집하고, Prometheus가 이를 다시 scrape 하는 방식으로 가져온다. 이를 통해 connection, lock, statement, index 같은 DB 운영 메트릭을 확인할 수 있다.
- AWS 인프라 메트릭은 CloudWatch datasource를 통해 조회한다. ECS는 Container Insights가 활성화되어 있어 클러스터와 서비스 단위의 운영 지표도 함께 볼 수 있다.
즉 애플리케이션과 DB 메트릭은 Prometheus에서, AWS 관리형 인프라 메트릭은 CloudWatch에서 가져오고, 최종 시각화는 Grafana에서 통합하는 구조이다.
4. 운영 방식과 자동화
이 모니터링 시스템은 수동 설치형이 아니라, 인프라 코드와 함께 자동 배포되도록 구성했다. CDK가 모니터링용 bootstrap asset을 만들고, EC2 UserData가 이를 내려받아 설치 스크립트를 실행한다.
이 과정에서 호스트 환경 준비, Prometheus와 pg_exporter 실행, Grafana datasource 프로비저닝까지 자동으로 처리된다. 따라서 운영자가 EC2에 직접 접속해 하나씩 설치하는 방식이 아니라, 인프라 배포와 모니터링 구성이 함께 코드로 관리되는 구조이다.
5. 보안과 운영 측면의 장점
이 구조의 장점은 먼저 모니터링 시스템이 외부에 직접 노출되지 않아 공격 표면이 작다는 점이다. Grafana 접근도 public endpoint가 아니라 SSM Port Forwarding으로 제한해 운영 경로를 통제할 수 있다.
또한 DB 자격증명을 코드나 파일에 하드코딩하지 않고, IAM Role과 Secrets Manager를 통해 동적으로 주입한다. 여기에 Grafana 하나에서 Prometheus와 CloudWatch를 함께 볼 수 있어 애플리케이션, 데이터베이스, AWS 인프라를 분리된 도구 없이 통합적으로 관측할 수 있다.
정리
핵심 설계 요약
이 프로젝트의 모니터링 시스템은 전용 EC2 위에 Grafana, Prometheus, pg_exporter를 구성하고, CloudWatch를 함께 연동해 애플리케이션 메트릭과 DB 메트릭, AWS 인프라 메트릭을 한 곳에서 통합 관측할 수 있도록 설계했다.
또한 운영 접근은 public endpoint 대신 SSM Port Forwarding으로 제한하고, DB 자격증명은 Secrets Manager와 IAM Role을 통해 주입하도록 구성했다. 이를 통해 보안성과 운영 편의성을 함께 확보하고, 인프라 코드 기반의 자동화된 모니터링 환경을 구축했다.