키워드 매핑 알고리즘 후보군 선정
1) 1차: 정규화 + Exact / Alias 매칭
핵심 아이디어
raw 키워드를 비교하기 전에 **표준화(norm)**를 강하게 해서 “같은 의미인데 표기가 다른 케이스”를 최대한 줄인다. → 이거는 키워드 추출할 떄
- 공백 정리:
"선택 약정" → "선택약정" -> 키워드 추출할때 - 특수문자 제거:
/ _ ()등 - 숫자/영문 케이스 통일:
5G, LTE, u+등 규칙화 - 자주 등장하는 조사/어미/상투어 제거(키워드 후보가 짧으면 과하지 않게)
그 다음:
norm_text == canonical_norm이면 바로 매핑- 별칭(alias) 사전:
{"선약": "선택약정 할인", "유심": "유심 관련", ...}
장점
- 정확도/설명가능성 최고, 속도 매우 빠름
- 운영자가 “왜 이렇게 매핑됐는지” 바로 납득함
2) 2차: 룰 기반 멀티패턴 매칭 (Aho–Corasick / Trie)
언제 쓰나
사전 정의 키워드가 수백~수천 개로 늘고, raw 텍스트가 길어지거나(상담 요약/메모) “부분 포함” 매칭이 중요해질 때.
- 예:
"납부 방법 변경"이 들어오면"요금 납부","납부 방법 변경"둘 다 후보로 잡고 싶음
방식
- business_keyword 및 alias들을 패턴으로 등록
- Aho–Corasick으로 한 번 스캔해서 후보들을 뽑음
- 후보가 여러 개면 “길이(더 구체적인 phrase 우선)”, “우선순위(업무상 중요)”로 tie-break
장점
- 정규식 난사보다 훨씬 빠르고 안정적
- 후보 생성 성능이 좋아서 뒤 단계(유사도) 호출량을 줄임
1/2차는 동일 진행
키워드 매핑 알고리즘 선정을 위한 후보군 테스트
U+ 플러스 1:1 상담 문의 카테고리와 자체 선정 키워드를 포함한 총 60개의 비즈니스 키워드를 기준으로, 각 키워드별 유사어 10개씩을 생성해 총 600개의 키워드에 대해 문자열 유사도 기반 매핑 성능을 비교했다. 이번 테스트의 목적은 상담 문장에서 추출된 키워드를 사전에 정의한 비즈니스 키워드에 매핑할 때, 정확도와 처리 성능을 모두 고려해 가장 적합한 알고리즘을 선정하는 것이다.
테스트 환경은 https://www.notion.so/3128a2b6906580829e2dffe888460cff?source=copy_lin와 같이 Docker의 독립된 컨테이너에서 아래와 같은 환경으로 테스트를 진행했다.
deploy:
resources:
limits:
cpus: "0.5"
memory: 1G
1. 후보 알고리즘
이번 비교 대상은 총 5개의 알고리즘이다.
1) Damerau-Levenshtein Disatance
Damerau-Levenshtein Distance는 기존 Levenshtein Distance에 전치(transposition) 연산을 추가한 편집 거리 알고리즘이다. 즉, 한 문자열을 다른 문자열로 변환할 때 필요한 삽입, 삭제, 치환뿐 아니라, 인접 문자 위치 변경까지 고려한다.
예를 들어 **“선택약정”**과 **“선텍약정”**처럼 철자 순서가 바뀐 오타에 상대적으로 강하다. 실제 사용자 입력에서는 오타, 띄어쓰기 오류, 철자 교체가 빈번하게 발생하므로, 이러한 변형을 폭넓게 처리할 수 있다는 장점이 있다.
2) Jaccard
Jaccard는 두 집합의 교집합 크기 / 합집합 크기를 기반으로 유사도를 계산하는 방식이다. A와 B 두 개의 집합이 있을 때, 두 집합의 합집합은 양쪽의 모든 원소를 포함할 것이고, 교집합은 공통으로 가지고 있는 원소들만 포함한다. 따라서 합집합 내에서 교집합의 비율을 구한다면, 두 집합이 같은 원소를 얼마나 많이 가지고 있는지, 그 비율을 알 수 있다.
따라서 두 집단 간의 유사도를 나타내는 **자카드 유사도(Jaccard Index)**는 다음과 같은 수식으로 나타낸다.
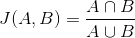
반대로, **자카드 거리(Jaccard Distance)**는 두 집합 간의 비유사도를 측정하는 지표이다. 자카드 유사도의 반대 개념이죠. 아래와 같이 수식으로 표현할 수 있다.
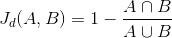
3) Levenshtein Distance
Levenshtein Distance는 가장 널리 알려진 편집 거리(Edit Distance) 기반 알고리즘으로, 두 문자열 사이를 변환하는 데 필요한 삽입, 삭제, 치환의 최소 횟수를 계산한다. Levenshtein 거리는 두 문자열 사이의 유사성을 비교하는데, 하나의 입력 문자열을 다른 입력 문자열로 변환하는 데 필요한 삽입(insertion), 삭제(deletion), 대체(substition)의 최소 횟수를 계산한다. 예를 들어, ‘kitten’과 ‘sitting’의 Levenshtein 거리를 구하면 아래와 같다.
- kitten → sitten (“k”를 “s”로 대체)
- sitten → sittin (“e”를 “i”로 대체)
- sittin → sitting (끝에 “g” 삽입)
위의 경로대로 계산하면, Levenshtein 거리의 값은 3이다. Levenshtein 거리를 계산하는 구체적인 방법은 Levenshtein (edit) distance를 이용한 한국어 단어의 형태적 유사성 글에서 잘 설명한다.
4) TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency)는 단어의 빈도와 역 문서 빈도(문서의 빈도에 특정 식을 취함)를 사용하여 DTM 내의 각 단어들마다 중요한 정도를 가중치로 주는 방법이다. 우선 DTM을 만든 후, TF-IDF 가중치를 부여한다. 문서를 d, 단어를 t, 문서의 총 개수를 n이라고 표현할 때 TF, DF, IDF는 각각 다음과 같이 정의할 수 있다.
(1) tf(d,t) : 특정 문서 d에서의 특정 단어 t의 등장 횟수
(2) df(t) : 특정 단어 t가 등장한 문서의 수.
(3) idf(t) : df(t)에 반비례하는 수.
5) Token-Set-Ratio
oken-Set-Ratio는 문자열을 토큰 단위로 분해한 뒤, 토큰 집합의 중복 제거 및 정규화를 거쳐 유사도를 계산하는 방식이다. 단어 순서가 바뀌어도 비교적 강인하다는 장점이 있다.
예를 들어 **“요금 납부 방법”**과 **“납부 방법 요금”**처럼 토큰 순서가 달라도 유사하게 평가할 수 있다. 반면, 짧은 키워드 중심의 데이터에서는 토큰 분해 기준에 따라 성능 편차가 생길 수 있다.
2. 데이터 셋
비즈니스 키워드는 실제 상담 분류 체계를 반영할 수 있도록 구성했다.
기본 카테고리에는 모바일, 인터넷, TV, 스마트홈, 국제전화, 부가전화, 홈페이지, 멤버십, 개인정보침해신고, 가입, 해지, 요금조회, 요금 납부, 요금제, 부가서비스, 결합상품 등이 포함되며, 여기에 실무 활용 가능성을 고려해 다음과 같은 키워드를 추가했다.
- 번호이동 문의
- 단말기분실 신고
- 자동이체 신청
- 위약금 조회
- 회선이전
- 속도변경 요청
- 와이파이 설정
- 채널추가
- 녹화예약
- CCTV 설치
- 기기추가
- 국가별 요금제
- 음성메시지 설정
- 발신제한 설정
- 비밀번호 찾기
- 앱오류
- 포인트 조회
- 쿠폰등록
- 정보수정
- 보이스피싱
1) 비즈니스 키워드
| 모바일 | 인터넷 | TV | 스마트홈 |
|---|---|---|---|
| 국제전화 | 부가전화 | 홈페이지 | 멤버십 |
| 개인정보침해신고 | 가입 | 해지 | 요금조회 |
| 요금 납부 | 요금제 | 부가서비스 | 결합상품 |
| 휴대폰 결제 | 일시정지 | 해외로밍 | 통화품질 |
| 육아 지원 | 데이터 혜택 | 혜택 | 설치장소 |
| 장애 점검 | 수신자부담전화 | 선불 카드 | 후불 카드 |
| 회원가입 | 로그인 | VIP콕 문의 | 영화 예매 |
| 유플투쁠 | 멤버십 등급 | 제휴사 혜택 | 멤버십 바코드 |
| 앱 기능 개선 | 명의 도용 | 기기 변경 | 유심 변경 |
| 번호이동 문의 | 단말기분실 신고 | 자동이체 신청 | 위약금 조회 |
| 회선이전 **** | 속도변경 요청 | 와이파이 설정 **** | 채널추가 |
| 녹화예약 | CCTV 설치 | 기기추가 | 국가별 요금제 |
| 음성메시지 설정 | 발신제한 설정 | 비밀번호 찾기 | 앱오류 |
| 포인트 조회 | 쿠폰등록 | 정보수정 | 보이스피싱 |
2) 유사어 라벨
각 비즈니스 키워드에 대해 실제 사용자가 입력할 수 있는 표현 변형을 고려해 유사어 10개씩을 수작업 또는 규칙 기반으로 생성했다. 이를 통해 총 600개의 평가용 키워드를 구성했으며, 각 유사어가 어떤 기준 키워드에 매핑되어야 하는지를 정답 라벨로 사용했다.
business_keyword_alias_map.json
2. 테스트 결과
1) 정확도 지표
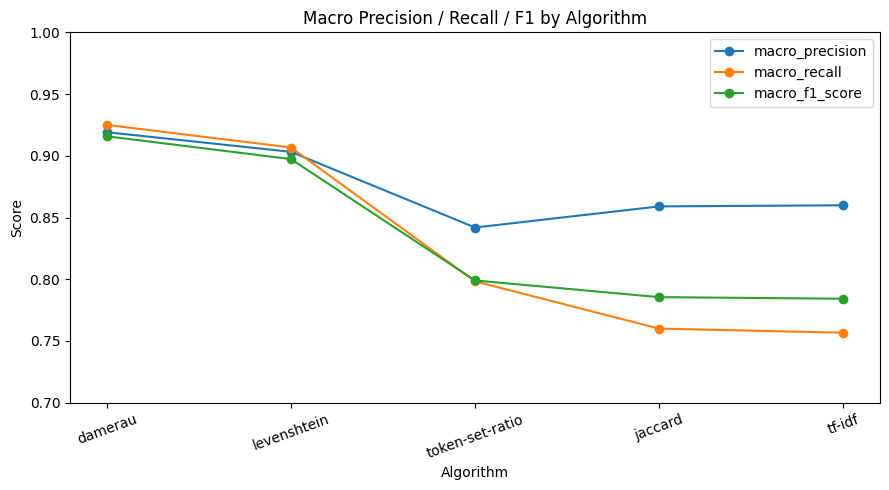
| tool | precision | recall | f1_score | macro_precision | macro_recall | macro_f1_score |
|---|---|---|---|---|---|---|
| damerau | 0.925 | 0.925 | 0.925 | 0.9191 | 0.925 | 0.9158 |
| levenshtein | 0.9067 | 0.9067 | 0.9067 | 0.9032 | 0.9067 | 0.8973 |
| token-set-ratio | 0.7983 | 0.7983 | 0.7983 | 0.8419 | 0.7983 | 0.799 |
| jaccard | 0.76 | 0.76 | 0.76 | 0.859 | 0.76 | 0.7855 |
| tf-idf | 0.7567 | 0.7567 | 0.7567 | 0.8599 | 0.7567 | 0.7842 |
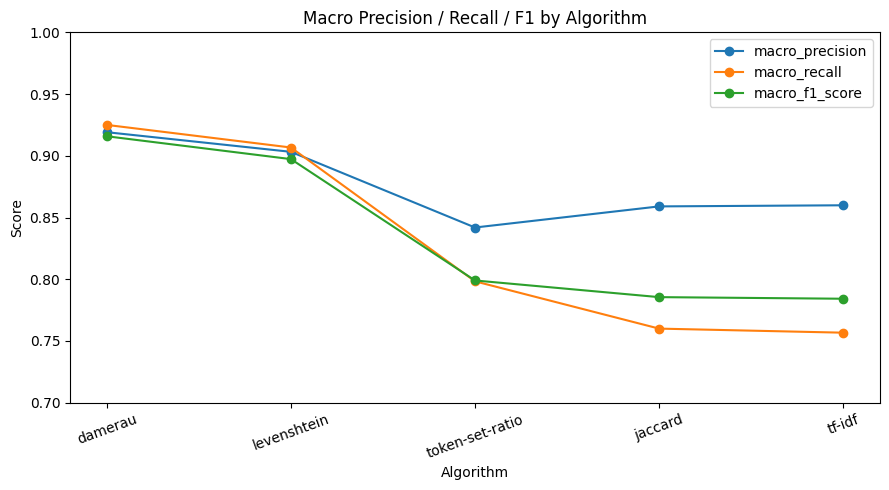
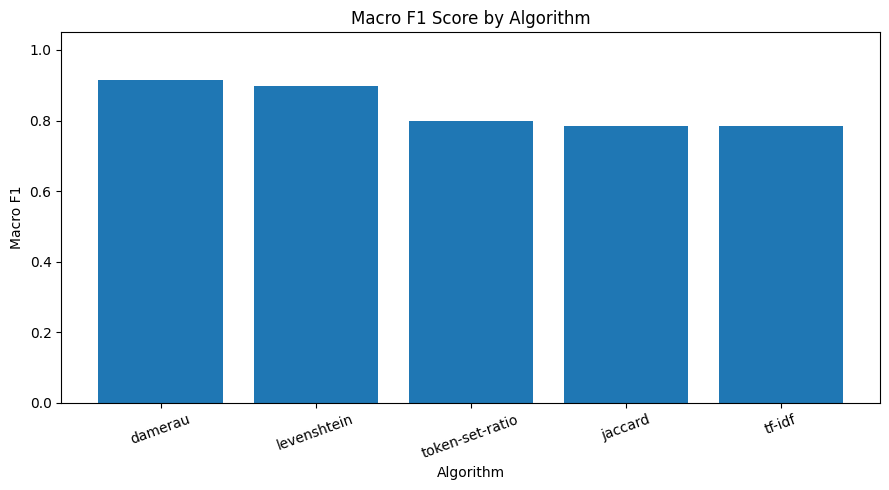
전체적으로 보면, 편집 거리 기반 알고리즘(Damerau, Levenshtein)이 다른 방식보다 확실히 높은 정확도를 기록했다. 이는 본 문제의 핵심이 문장 의미 이해보다는 짧은 키워드의 오타, 띄어쓰기 차이, 철자 변형 대응에 있기 때문이다. 특히 Damerau는 일반 Levenshtein보다 전치 오류까지 처리할 수 있어, 실제 상담 입력에서 자주 발생하는 오타 패턴을 더 잘 흡수한 것으로 해석할 수 있다.
반면 Jaccard와 TF-IDF는 처리 속도는 빠르지만, 철자 단위의 미세한 변형을 세밀하게 잡아내기 어려워 정확도 측면에서는 상대적으로 낮은 성능을 보였다.Token-Set-Ratio는 토큰 재배열에는 강점이 있지만, 이번처럼 짧고 명확한 카테고리 키워드 매핑 문제에서는 기대보다 낮은 성능을 기록했다.
2) 성능 지표
| tool | elapsed_seconds | throughput_docs_per_sec | memory_peak_mb | cpu_total_seconds |
|---|---|---|---|---|
| damerau | 4.8329 | 124.1485 | 16.4219 | 4.7998 |
| levenshtein | 2.7309 | 219.7087 | 16.5469 | 2.5605 |
| token-set-ratio | 3.7656 | 159.3379 | 16.7031 | 3.7437 |
| jaccard | 0.9031 | 664.3753 | 16.5 | 0.8981 |
| tf-idf | 1.1246 | 533.5421 | 16.6562 | 1.1187 |
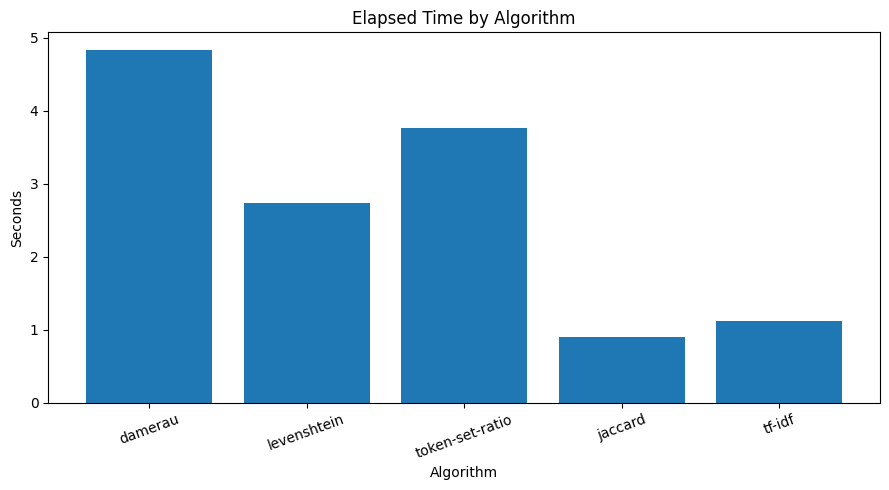
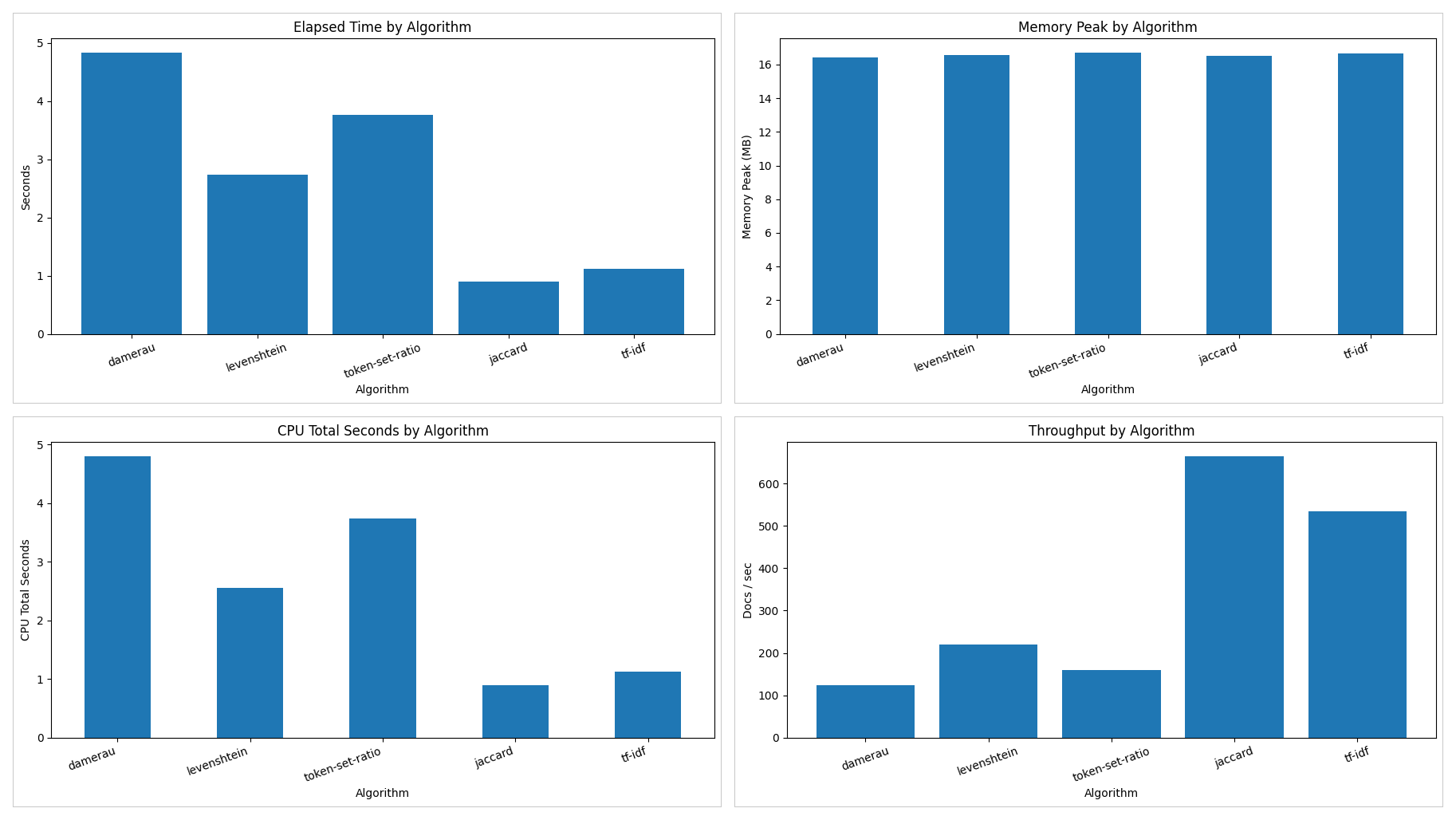
성능 측면에서는 Jaccard가 가장 빠른 처리 속도를 보였다. 즉, 속도만 놓고 보면 Jaccard와 TF-IDF가 가장 우수했다. 반면 정확도가 가장 높았던 Damerau는 가장 느린 처리 성능을 보였다.
다만 메모리 사용량은 모든 알고리즘이 약 16.4MB ~ 16.7MB 수준으로 큰 차이가 없었기 때문에, 이번 비교에서 핵심적인 성능 차이는 메모리보다는 CPU 시간과 **처리량(throughput)**에서 발생했다고 볼 수 있다. CPU 사용 시간 역시 Jaccard와 TF-IDF가 가장 낮았고, Damerau와 Token-Set-Ratio가 상대적으로 높았다. 즉, 본 테스트 환경에서는 정확도가 높을수록 처리 비용이 증가하는 경향이 비교적 분명하게 나타났다.
3. 알고리즘 선택
하지만 이번 프로젝트의 목적은 단순 검색이 아니라, 상담 키워드를 비즈니스 분류 체계에 안정적으로 매핑하는 것이다. 잘못된 매핑은 이후 통계 집계, VOC 분석, 이탈 위험 탐지 등 후속 로직 전체에 영향을 줄 수 있기 때문에, 단순 처리 속도보다 초기 매핑 정확도가 더 중요하다.
이 관점에서 보면, 선정 후보로는 Damerau-Levenshtein Distance가 가장 적합하다. 정확도 지표에서 가장 높은 수치를 기록했고, 사용자 입력에서 자주 발생하는 인접 문자 전치 오타까지 처리할 수 있기 때문이다.