1. 개요
실제 U+ 또는 통신사의 상담 문의 내역을 직접 스크랩 또는 크롤링 할 수 없어 AI Hub의 민간 민원 상담 LLM 사전학습 및 Instruction Tuning 데이터를 이용하여 정답 라벨을 생성하고 이에 맞게 값이 생성 되었는지를 비교 분석 및 성능 측정을 진행했다.
데이터 도메인별 분포도는 아래와 같다.
| 총 상담 데이터 건수 | 12,303건 | ||
|---|---|---|---|
| 총 어절 수 | 총 3,580,857어절 | ||
| 수집 출처 | 수집처 | 건수 | 비율 |
| 하나카드 | 76,804 | 58.01% | |
| 엘지유플러스 | 43,920 | 33.17% | |
| 액티벤처 | 11,677 | 8.82% | |
| 합계 | 132,401 | 100% | |
| 상담데이터 1건당 평균 Instruction tuning data 수 | 평균 10.76건(가공데이터 132,401건 / 원천데이터 12,303건) |
이 중 엘지유플러스의 실제 데이터 모델만을 추출하여 사용하였다.
데이터셋 통계 수집 방식
| Key | Description | Type | Child Type |
|---|---|---|---|
| source | 원천대상 | string | 수집기관명 |
| source_id | 원천데이터 일련번호 | string | 1 |
| consulting_date | 상담일시 | string | 20231005 |
| consulting_category | 수집기관별 업무 유형 | string | 유형명 |
| client_gender | 상담자 유형 | string | 남, 여 |
| client_age | 상담자 연령대 | string | 30대 |
| consulting_time | 상담시간 | string | 초 |
| consulting_content | 상담내용 | string | |
| consulting_turns | 대화턴 수 | string | |
| consulting_length | 상담 내용 길이 | string | 어절 수 |
| tuning_type | 분류, 요약, 질의응답 | string | |
| instructions.instruction_id | 지시문 아이디 | number | 1, 2, 3… |
| instructions.task | 분류, 요약, 질의응답 | string | |
| instructions.task_category | 태스크 하위 카테고리 | string | 가공 유형명 |
| instruction_length | 지시문 길이(어절 수) | string | |
| input_length | input 데이터 길이(어절 수) | string | |
| output_length | output 데이터 길이(어절 수) | string | |
| instructions.instruction | 지시문, 질문 | string | |
| instructions.input | 원천데이터 상담 내용 전체 또는 일부 | string | |
| instructions.output | 분류명, 요약문, 답변 | string |
0) 키워드 추출 라이브러리 후보 선정
- spaCy 한국어 모델
- KOMORAN
- Python
- Java
- OKT
- Python
- Java
⇒ 설명 자세하게 적기!
1) 데이터 정제
- 전체 상담 데이터 중 실제 키워드 추출 라이브러리를 선정하기 위해서는 **상담 내용(consultion_content)**만 필요하기 때문에 상담 내용, 상담 id만 추출하여 1차적으로 데이터를 정제하였다.
{
"id": "44017",
"상담내용":
"상담사: 일상의 즐거운 변화 LGU+ <NAME>입니다.
고객: 아 예, 휴대폰 분실 파손 보험 그거를 없애려고 하는데 그거는 전화로만 되나요?
상담사: 네, 네. 맞습니다. 아무래도 보험이라서 삭제를 하면 복구가 되지가 않아 가지고 전화상으로 삭제를 해드리고 있거든요.
고객: 근데 그게 만약에 삭제를 해도 다시 나중에 할 순 있죠?
상담사: 아니요, 고객님. 삭제를 하시면은 복구되지 않으셔서 보험 청구도 안 되세요.
고객: 보험 청구가 안 되는데 다시 보험을 들 수는 없어요?
상담사: 네, 맞습니다. 삭제를 하시면 다시 보험을 들 수가 없어요. 그래서 전화상으로 저희가 삭제를 해드리고 있거든요.
고객: 아 근데 그 프리미엄 약정 요금제는 뭐예요?
상담사: 아 프리미엄 약정 할인이요?
고객: 네.
상담사: 바로 한번 확인해 드리겠습니다. 연락 주신 저희 <NAME> 고객님 본인 맞으십니까?
고객: 예.
상담사: 네, 저희가 지금 요금제 기준으로 <CHARGE>짜리 이상 요금제 쓰시는 분들에 한해서 이 프리미엄 약정 할인을 이 요금제를 쓰는 조건으로 2년 동안 매월 <CHARGE>씩 할인을 받을 수가 있는 약정 할인인데요.
고객: 예, 예.
상담사: 저희 고객님 같은 경우에도 <CHARGE>짜리 요금제 사용하셔 가지고 약정 할인을 등록하시면 2년 동안 이 요금제를 쓰는 조건인데 만약에 이 요금제에서 고객님이 다른 낮은 요금제로 바꿔버리신다고 하면은 위약금이 나오게 될 수가 있고요.
고객: 예, 예. 근데 휴대폰 분실 파손 보험 그게 유료 서비스로 들어가 있던데 만약에 기기 변경을 하게 되면 거기에 적용되는 건가요?
상담사: 아 아니요, 고객님. 해당 보험료는 지금 쓰고 계신 기기에 대한 보험이라서 만약에 기기 변경을 하시면 새로 바꾼 기기에서도 고객님이 다시 보험을 들어야 제공이 됩니다.
고객: 아 예, 예.
상담사: 왜냐면 휴대폰을 가입하시고 나서 보험 가입이 최대 60일 이내로 하셔야 등록할 수가 있어요. 고객님이 기기를 만약에 바꾸시면 그 기기에 보험을 다시 들으셔야 나중에 보상을 받으실 수가 있습니다. 그리고 이전 보험은 자동으로 해지가 되고요.
고객: 아 네, 또 궁금한 게 휴대폰 상담하려면 통신사 가야 되죠?
상담사: 저희 전화상으로도 본사에 담당 부서가 따로 있는데 상담 원하시면 연결해 드릴까요?
고객: 아 본사 혜택이랑 대리점이랑 다르잖아요.
상담사: 대리점에서 안내되는 혜택이 있을 수가 있고 본사에서도 방문하시기 어려우신 분들을 위해서 전화로 따로 상담 가능하세요. 혜택은 똑같습니다.
고객: 아 일단 알겠습니다.
상담사: 혹시라도 상담 원하시면 나중에 고객님이 직접 문의하실 수 있게 전화번호 문자로 챙겨드릴까요?
고객: 아니요, 제가 나중에 필요하면 다시 전화 할게요.
상담사: 네, 알겠습니다. 더 궁금하신 건 없으시고요?
고객: 예.
상담사: 네, 감사합니다. 이번 주에도 좋은 일들만 가득하세요.
고객: 예.
"
}
- 50개의 상담 내역만 필요하다고 판단하여 2차적으로 50개의 상담 내용을 1개의 Json 파일로 생성했다.
[
{
"id": "44017",
"상담내용": "상담사: 일상의 즐거운 변화 LGU+ <NAME>입니다.\n고객: 아 예, 휴대폰 분실 파손 보험 그거를 없애려고 하는데 그거는 전화로만 되나요?\n상담사: 네, 네. 맞습니다. 아무래도 보험이라서 삭제를 하면 복구가 되지가 않아 가지고 전화상으로 삭제를 해드리고 있거든요.\n고객: 근데 그게 만약에 삭제를 해도 다시 나중에 할 순 있죠?\n상담사: 아니요, 고객님. 삭제를 하시면은 복구되지 않으셔서 보험 청구도 안 되세요.\n고객: 보험 청구가 안 되는데 다시 보험을 들 수는 없어요?\n상담사: 네, 맞습니다. 삭제를 하시면 다시 보험을 들 수가 없어요. 그래서 전화상으로 저희가 삭제를 해드리고 있거든요.\n고객: 아 근데 그 프리미엄 약정 요금제는 뭐예요?\n상담사: 아 프리미엄 약정 할인이요?\n고객: 네.\n상담사: 바로 한번 확인해 드리겠습니다. 연락 주신 저희 <NAME> 고객님 본인 맞으십니까?\n고객: 예.\n상담사: 네, 저희가 지금 요금제 기준으로 <CHARGE>짜리 이상 요금제 쓰시는 분들에 한해서 이 프리미엄 약정 할인을 이 요금제를 쓰는 조건으로 2년 동안 매월 <CHARGE>씩 할인을 받을 수가 있는 약정 할인인데요.\n고객: 예, 예.\n상담사: 저희 고객님 같은 경우에도 <CHARGE>짜리 요금제 사용하셔 가지고 약정 할인을 등록하시면 2년 동안 이 요금제를 쓰는 조건인데 만약에 이 요금제에서 고객님이 다른 낮은 요금제로 바꿔버리신다고 하면은 위약금이 나오게 될 수가 있고요.\n고객: 예, 예. 근데 휴대폰 분실 파손 보험 그게 유료 서비스로 들어가 있던데 만약에 기기 변경을 하게 되면 거기에 적용되는 건가요?\n상담사: 아 아니요, 고객님. 해당 보험료는 지금 쓰고 계신 기기에 대한 보험이라서 만약에 기기 변경을 하시면 새로 바꾼 기기에서도 고객님이 다시 보험을 들어야 제공이 됩니다.\n고객: 아 예, 예.\n상담사: 왜냐면 휴대폰을 가입하시고 나서 보험 가입이 최대 60일 이내로 하셔야 등록할 수가 있어요. 고객님이 기기를 만약에 바꾸시면 그 기기에 보험을 다시 들으셔야 나중에 보상을 받으실 수가 있습니다. 그리고 이전 보험은 자동으로 해지가 되고요.\n고객: 아 네, 또 궁금한 게 휴대폰 상담하려면 통신사 가야 되죠?\n상담사: 저희 전화상으로도 본사에 담당 부서가 따로 있는데 상담 원하시면 연결해 드릴까요?\n고객: 아 본사 혜택이랑 대리점이랑 다르잖아요.\n상담사: 대리점에서 안내되는 혜택이 있을 수가 있고 본사에서도 방문하시기 어려우신 분들을 위해서 전화로 따로 상담 가능하세요. 혜택은 똑같습니다.\n고객: 아 일단 알겠습니다.\n상담사: 혹시라도 상담 원하시면 나중에 고객님이 직접 문의하실 수 있게 전화번호 문자로 챙겨드릴까요?\n고객: 아니요, 제가 나중에 필요하면 다시 전화 할게요.\n상담사: 네, 알겠습니다. 더 궁금하신 건 없으시고요?\n고객: 예.\n상담사: 네, 감사합니다. 이번 주에도 좋은 일들만 가득하세요.\n고객: 예."
},
...
{
"id": "44066",
"상담내용": "일상의 즐거운 변화 입니다 네 안녕하세요 저 부가서비스 좀 해지하려고요 아 네 바로 한번 확인해 보겠습니다 저희 문의주신 번호 명의자분 고객님 본인 맞습니까 네 네 확인 감사드립니다 현재 유료로 되어 있는 부가 서비스는 통화연결음 서비스 한 가지인데 이 서비스 해지 원하시는 것 맞으세요 아 이거 말고 잠시만요 네 영화월정액 프리미엄 번호 나가고 있는데요 이요 잠시만 기다려 주시겠어요 네 아 고객님 영화월정액 프리미엄 서비스는 자로 매장 측에서 해지가 된 것으로 확인되시거든요 네 네 이게 에 해지가 되다 보니까 사용하셨던 게 청구되는 거잖아요 그때까지는 나오셨던 거고 이번 청구 요금에는 등록되어 있던 일수만큼 요금이 나오실 거예요 네 현재는 해지되어 있는 상태 맞으세요 고객님 아 그럼 부터는 나오지 않겠네요 청구서에는 나오시죠 에 사용료가 에 나오시는 거니까 자에 삭제가 되다 보니 일수만큼은 나오시고 이제 청구 요금부터는 발생되지 않습니다 네 그거 제가 이용을 하면 혹시 어떤 건지 알 수 있을까요 음 이거 저희 모바일 앱 내에서 영화 보시는 월정액 서비스입니다 아 네 알겠습니다 다른 문의 사항은 혹시 있으세요 없습니다 아 네 어렵게 연락해 주셨는데 추가적으로 보니까 핸드폰은 잘 이용 중이셔서 혹시 인터넷과 같이 결합하시면 그 사용하시는 요금제에 따라 인터넷 쪽은 월 지 모바일 쪽은 까지 결합할인 혜택받아 보실 수 있거든요 그러면 간단하게 상담 도와드릴까요 아 근데 저희가 가족분들같이 쓰고 있어서요 아 알겠습니다 결합은 안 될 거 같아요 언제든 궁금한 사항 있으시면 연락 부탁드릴게요 네 감사합니다 감사합니다 고객님 항상 건강 유의하세요 네 감사합니다 네 감사합니다 고객님"
]
- 원문 데이터에 존재하는 특수 기호, 줄 바꿈 기호, “고객”, “상담사”와 같이 키워드 추출과 직접적 상관없는 단위들을 제거했다.
{
"상담_id": "44017",
"상담내용": "일상의 즐거운 변화 LGU NAME 입니다 아 예 휴대폰 분실 파손 보험 그거를 없애려고 하는데 그거는 전화로만 되나요 네 네 맞습니다 아무래도 보험이라서 삭제를 하면 복구가 되지가 않아 가지고 전화상으로 삭제를 해드리고 있거든요 근데 그게 만약에 삭제를 해도 다시 나중에 할 순 있죠 아니요 고객님 삭제를 하시면은 복구되지 않으셔서 보험 청구도 안 되세요 보험 청구가 안 되는데 다시 보험을 들 수는 없어요 네 맞습니다 삭제를 하시면 다시 보험을 들 수가 없어요 그래서 전화상으로 저희가 삭제를 해드리고 있거든요 아 근데 그 프리미엄 약정 요금제는 뭐예요 아 프리미엄 약정 할인이요 네 바로 한번 확인해 드리겠습니다 연락 주신 저희 NAME 고객님 본인 맞으십니까 예 네 저희가 지금 요금제 기준으로 CHARGE 짜리 이상 요금제 쓰시는 분들에 한해서 이 프리미엄 약정 할인을 이 요금제를 쓰는 조건으로 2년 동안 매월 CHARGE 씩 할인을 받을 수가 있는 약정 할인인데요 예 예 저희 고객님 같은 경우에도 CHARGE 짜리 요금제 사용하셔 가지고 약정 할인을 등록하시면 2년 동안 이 요금제를 쓰는 조건인데 만약에 이 요금제에서 고객님이 다른 낮은 요금제로 바꿔버리신다고 하면은 위약금이 나오게 될 수가 있고요 예 예 근데 휴대폰 분실 파손 보험 그게 유료 서비스로 들어가 있던데 만약에 기기 변경을 하게 되면 거기에 적용되는 건가요 아 아니요 고객님 해당 보험료는 지금 쓰고 계신 기기에 대한 보험이라서 만약에 기기 변경을 하시면 새로 바꾼 기기에서도 고객님이 다시 보험을 들어야 제공이 됩니다 아 예 예 왜냐면 휴대폰을 가입하시고 나서 보험 가입이 최대 60일 이내로 하셔야 등록할 수가 있어요 고객님이 기기를 만약에 바꾸시면 그 기기에 보험을 다시 들으셔야 나중에 보상을 받으실 수가 있습니다 그리고 이전 보험은 자동으로 해지가 되고요 아 네 또 궁금한 게 휴대폰 상담하려면 통신사 가야 되죠 저희 전화상으로도 본사에 담당 부서가 따로 있는데 상담 원하시면 연결해 드릴까요 아 본사 혜택이랑 대리점이랑 다르잖아요 대리점에서 안내되는 혜택이 있을 수가 있고 본사에서도 방문하시기 어려우신 분들을 위해서 전화로 따로 상담 가능하세요 혜택은 똑같습니다 아 일단 알겠습니다 혹시라도 상담 원하시면 나중에 고객님이 직접 문의하실 수 있게 전화번호 문자로 챙겨드릴까요 아니요 제가 나중에 필요하면 다시 전화 할게요 네 알겠습니다 더 궁금하신 건 없으시고요 예 네 감사합니다 이번 주에도 좋은 일들만 가득하세요 예"
}
2) 정답 라벨 생성
우리의 비즈니스 키워드와의 매핑을 위해서는 명사, 명사+명사 형태의 키워드 추출이 필요하여 50개의 상담 내용에서 키워드별 빈도 수를 추출하여 정답 라벨을 선정하였다.
{
"records": [
{
"id": 1,
"상담내용": "일상의 즐거운 변화 입니다 예 수고하십니다 제가 지금 중고폰 무슨 보상 그거 해서 휴대폰을 10년 전에 샀는데요 네 그게 제가 지금 만료일이 인가 제가 알고 있는데 네 맞으세요 이거 반납을 그럼 언제까지 해야 돼요 그 이전에 해야 되는 거예요 지나서 해야 되는 거예요 확인해 드릴 텐데 본인이십니까 예 맞습니다 네 중고폰 반납은 그 부터 가능한 거구요 네 그 전자가 핸드폰 만드는 사업을 종료했기 때문에 저희가 이제 그 기변 가능한 모델은 전자로 제한시킨 게 아니고 삼성전자랑 아이폰 쪽에서도 중고폰 보장을 받을 수 있게끔 지금 발표가 났구요 네 뭐 그건 알고 있구요 아 네 그래서 그 기기 반납하시고 기기 기기변경이 부터 가능하세요 네 부터에서 언제까지 해야 된다는 것도 있나요 그달 안으로 하셔야 혜택이 제일 크세요 아 그 안으로 해야 되는 거네요 저 같은 경우는 아 그러면 이거 만약에 예를 들면 삼성 것을 한다 그러면 삼성 것을 사서 계속 가입자 유지를 해야 되는 거죠 네 맞습니다 그 새롭게 약정을 들어가는 거라고 보셔야 되세요 그러면 이거 그러면 새로 사면서 또 뭐 이런 이상한 약정이 걸리는 건 아니죠 지금은 중고폰 보장 프로그램이 폴드나 플립 같은 경우에는 나올 예정인데 21은 올해 초에 나왔기 때문에 지금은 가입 가능한 기간이 지나셨어요 예 아 그래요 만약에 21로 하시면 가입 자체가 안 되실 거고 그 쯤에 중순쯤에 폴드는 이 나올 거잖아요 예 아니 그거는 관계없고 이거 만약에 제가 기계를 새로 사게 되면 요금제는 어떻게 되는 거예요 제가 요금제 지금 인가 뭐 그런 거 쓰고 있는데요 네 그거는 고객님께서 새롭게 아예 모든 것을 변경하시는 것이기 때문에 공시지원금으로 기기변경하실지 선택약정으로 기기변경하실지는 고객님의 선택이시구요 네 원하시는 기기에 대해서 지원금을 조회해 보신 다음에 지원금하고 할인 혜택을 비교를 해 보시고 더 혜택이 큰 쪽으로 선택을 하시면 되는 거세요 근데 문자로 제가 보니까 선택약정 하라고 하는 계속 문자 온 것 같은데 그건 뭐예요 선택약정은 그거는 기기변경을 안 하실 때 연장하시면 되는 거라서 고객님은 반납하시고 기기변경하실 거니까 신경 쓰실 필요 없으신데 문제는 할인이 끝나세요 네 그래서 쯤에 기기변경하실 거면 약정을 연장하시는 게 좋으신 거구요 네 아 그럼 까지요 전에 기기변경하실 거면 하실 필요 없으세요 까지 기기변경을 안 하면 요금이 올라가는 거예요 할인을 못 받으시니까요 그 요금 올라가는 거네요 네 어쨌든 뭐 며칠 이용을 조금 더 하시기 하겠지만 그래도 기본 요금 할인 안 들어가시니까요 아아 그럼 에 무조건 바꿔야 되는 거네요 네 그게 나으세요 어차피 약정 두 개 하실 필요 없으시니까요 네 바로 기기변경하시는 게 나으세요 아 혹시 그러면 이거 제가 이거 다시 가입했던 대리점이 너무 작아서 고객센터 쪽에서 기기변경 관련된 지원 사항이나 이런 건 따로 뭐 없나요 네 저희 온라인숍으로도 요즘 에그 택배로 반납하시고 기기변경도 이루어지고 있기 때문에 상담받으실 수 있게 연결을 좀 해 드리면 어떠세요 네 지금 바로 연결됩니까 네 바로 됩니다 예 부탁드리겠습니다 네 바로 유샵이라는 대로 연결되시는 거구요 네 제가 직통 전화번호 문자 남겨드릴 테니까 나중에 필요하시면 그쪽으로 바로 전화하시면 되세요 아 예 알겠습니다 네 오늘 좋은 대화 이어가세요 감사합니다 감사합니다",
"명사": [
{
"keyword": "기기변경",
"count": 5
},
{
"keyword": "중고폰",
"count": 4
},
{
"keyword": "약정",
"count": 4
},
{
"keyword": "할인",
"count": 4
},
....
]
}
]
}
3) 테스트 환경 구축
한글 상담 데이터에서 키워드를 안정적으로 추출하기 위해, Python 및 Java 기반의 주요 형태소 분석 라이브러리를 후보군으로 선정하였다.
이번 테스트의 목적은 단순히 “동작 여부”를 확인하는 것이 아니라, 실제 서비스에 적용했을 때 어떤 라이브러리가 가장 정확하고 안정적으로 키워드를 추출할 수 있는지를 검증하는 데 있다.
이를 위해 평가는 크게 두 축으로 나누어 진행하였다.
- 정확도 지표: 추출된 키워드가 정답과 얼마나 일치하는지 평가
- 성능 지표: 실행 시간, 메모리, CPU 사용량 등 실제 운영 시 자원 효율 평가
정확도 평가는 아래 지표를 기준으로 측정하였다.
| 지표 | 의미 | 무엇을 보는가 | 계산식 |
|---|---|---|---|
| Precision | 정밀도 | 예측한 것 중 실제 정답 비율 | TP / (TP + FP) |
| Recall | 재현율 | 실제 정답 중 찾아낸 비율 | TP / (TP + FN) |
| F1 Score | F1 점수 | Precision과 Recall의 균형 | 2 × (Precision × Recall) / (Precision + Recall) |
특히 본 테스트에서는 단순히 키워드를 많이 뽑는 것보다, 실제 정답과의 일치율을 높이는 것이 중요하므로 Precision, Recall, 그리고 두 지표의 균형을 반영하는 F1 Score를 핵심 지표로 사용하였다.
또한, 라이브러리별 자원 사용량과 처리 효율을 비교하기 위해 아래 성능 지표를 함께 측정하였다.
| 지표 | 의미 | 무엇을 보는가 | 계산식 |
|---|---|---|---|
| Elapsed Seconds | 총 처리 시간 | 전체 데이터 처리에 걸린 총 시간 | 작업 종료 시각 - 작업 시작 시각 |
| Throughput | 초당 처리량 | 1초 동안 처리한 문서 수 | 처리 문서 수 / Elapsed Seconds |
| Memory MB | 현재 메모리 사용량 | 측정 시점의 프로세스 메모리 사용량 | 프로세스 점유 메모리(MB) |
| Peak MB | 최대 메모리 사용량 | 실행 중 가장 많이 사용한 메모리 | 실행 구간 내 최대 메모리(MB) |
| CPU Total Seconds | CPU 누적 시간 | 프로세스가 실제로 사용한 CPU 시간의 누적합 | User CPU Time + System CPU Time |
| CPU Util (single core) | CPU 사용률(단일 코어 기준) | 단일 코어를 기준으로 본 CPU 점유율 | (CPU Total Seconds / Elapsed Seconds) × 100 |
| CPU Util (all cores) | CPU 사용률(전체 코어 환산) | 전체 논리 코어 수를 기준으로 환산한 CPU 사용률 | (CPU Total Seconds / (Elapsed Seconds × 코어 수)) × 100 |
| CPU Sample Avg (process) | 평균 프로세스 CPU 사용률 | 샘플링 구간 동안 프로세스 CPU 사용률의 평균 | 각 샘플 시점의 프로세스 CPU% 평균 |
| CPU Sample Avg (system) | 평균 시스템 CPU 사용률 | 샘플링 구간 동안 전체 시스템 CPU 사용률의 평균 | 각 샘플 시점의 시스템 CPU% 평균 |
추가로, 라이브러리 간 캐시, 메모리 점유, 런타임 상태 공유 등으로 인해 테스트 결과가 왜곡되는 것을 방지하기 위해, 각 후보군은 서로 독립된 Docker 컨테이너 환경에서 실행하였다.
이를 통해 각 라이브러리가 동일한 입력 데이터와 동일한 자원 제한 조건에서 실행되도록 구성하여, 비교의 공정성을 높였다.
services:
python-bench:
build: ./python-bench
volumes:
- ./python-bench:/app
- ./data:/app/data
deploy:
resources:
limits:
cpus: "0.5"
memory: 1G
java-bench:
build: ./java-bench
volumes:
- ./data:/app/data
deploy:
resources:
limits:
cpus: "0.5"
memory: 1G
- CPU : 0.5vCPU 사용 제한
- Memory : 1GB 사용 제한
즉, 이번 실험은 동일 데이터셋, 동일 자원 제약, 독립 실행 환경이라는 조건에서 수행되었으며, 이를 통해 각 라이브러리의 정확도와 성능을 보다 객관적으로 비교할 수 있도록 설계하였다.
2. 테스트 결과
1) 정확도 지표
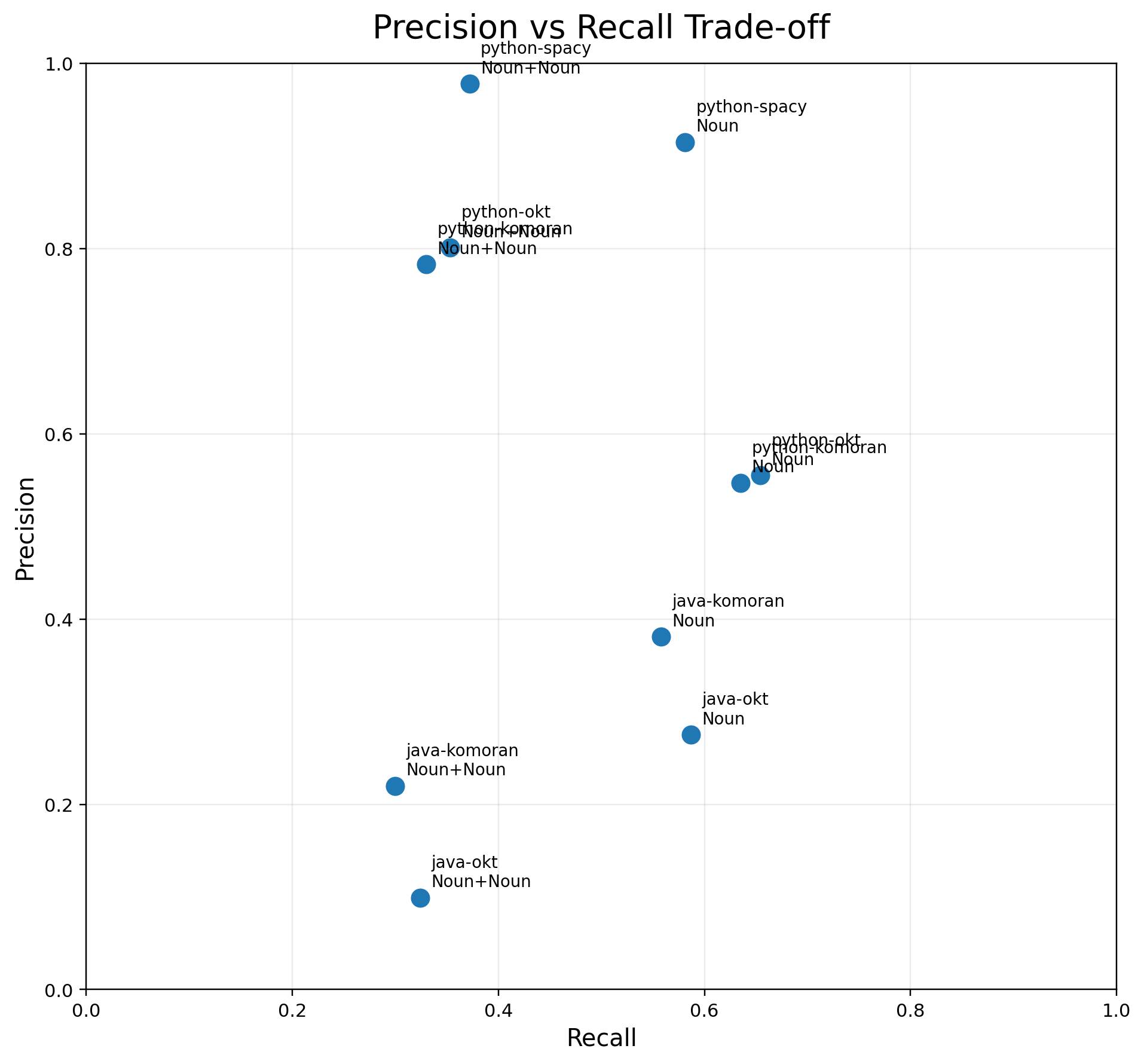
| algorithm | category | precision | recall | f1 |
|---|---|---|---|---|
| python-okt | 명사 | 0.555 | 0.654 | 0.600 |
| python-okt | 명사+명사 | 0.801 | 0.353 | 0.490 |
| python-komoran | 명사 | 0.547 | 0.635 | 0.588 |
| python-komoran | 명사+명사 | 0.783 | 0.330 | 0.464 |
| python-spacy | 명사 | 0.915 | 0.581 | 0.710 |
| python-spacy | 명사+명사 | 0.978 | 0.372 | 0.538 |
| java-okt | 명사 | 0.275 | 0.587 | 0.375 |
| java-okt | 명사+명사 | 0.099 | 0.324 | 0.152 |
| java-komoran | 명사 | 0.381 | 0.558 | 0.453 |
| java-komoran | 명사+명사 | 0.220 | 0.300 | 0.254 |
실제 성능 출력 값
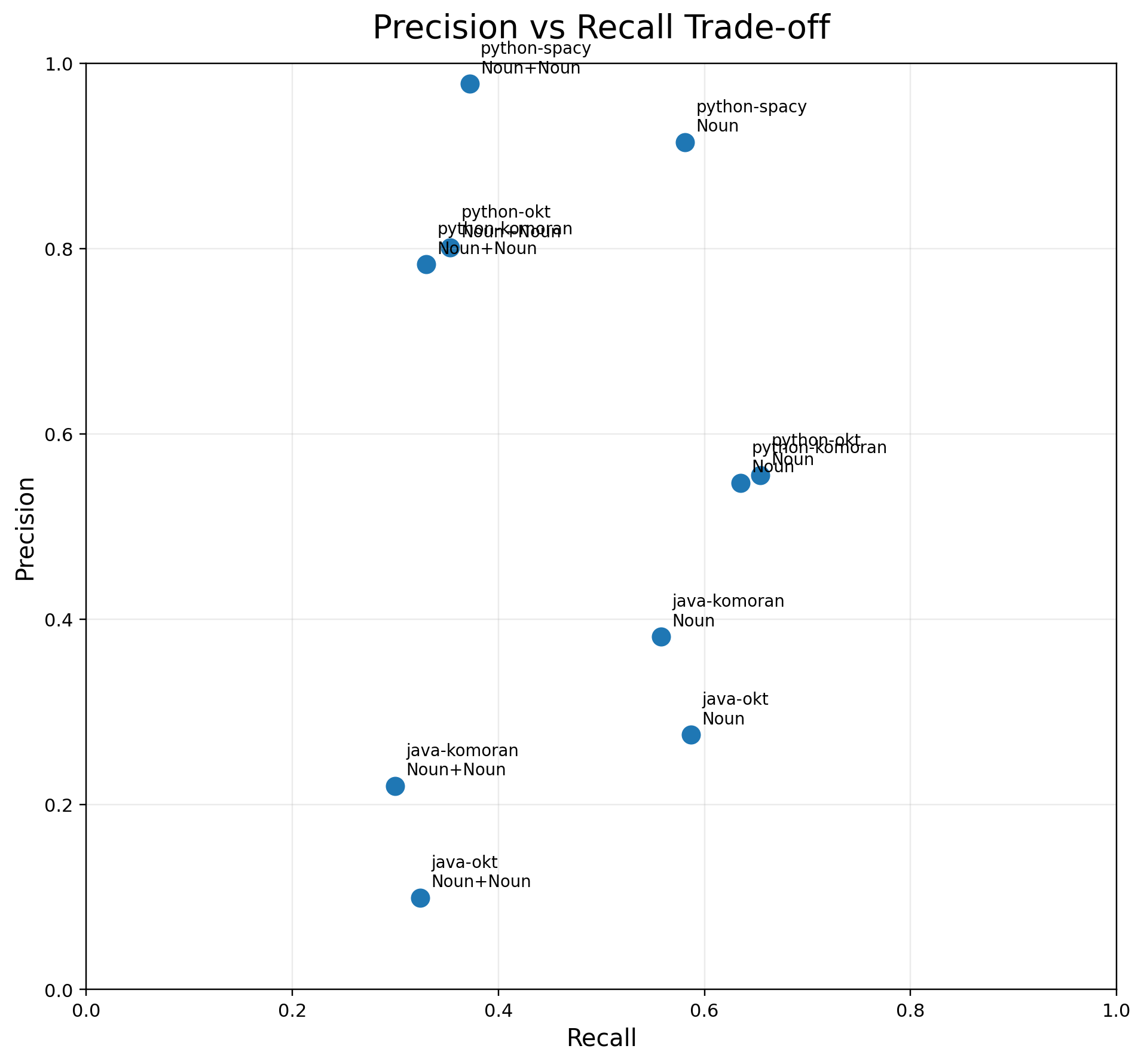
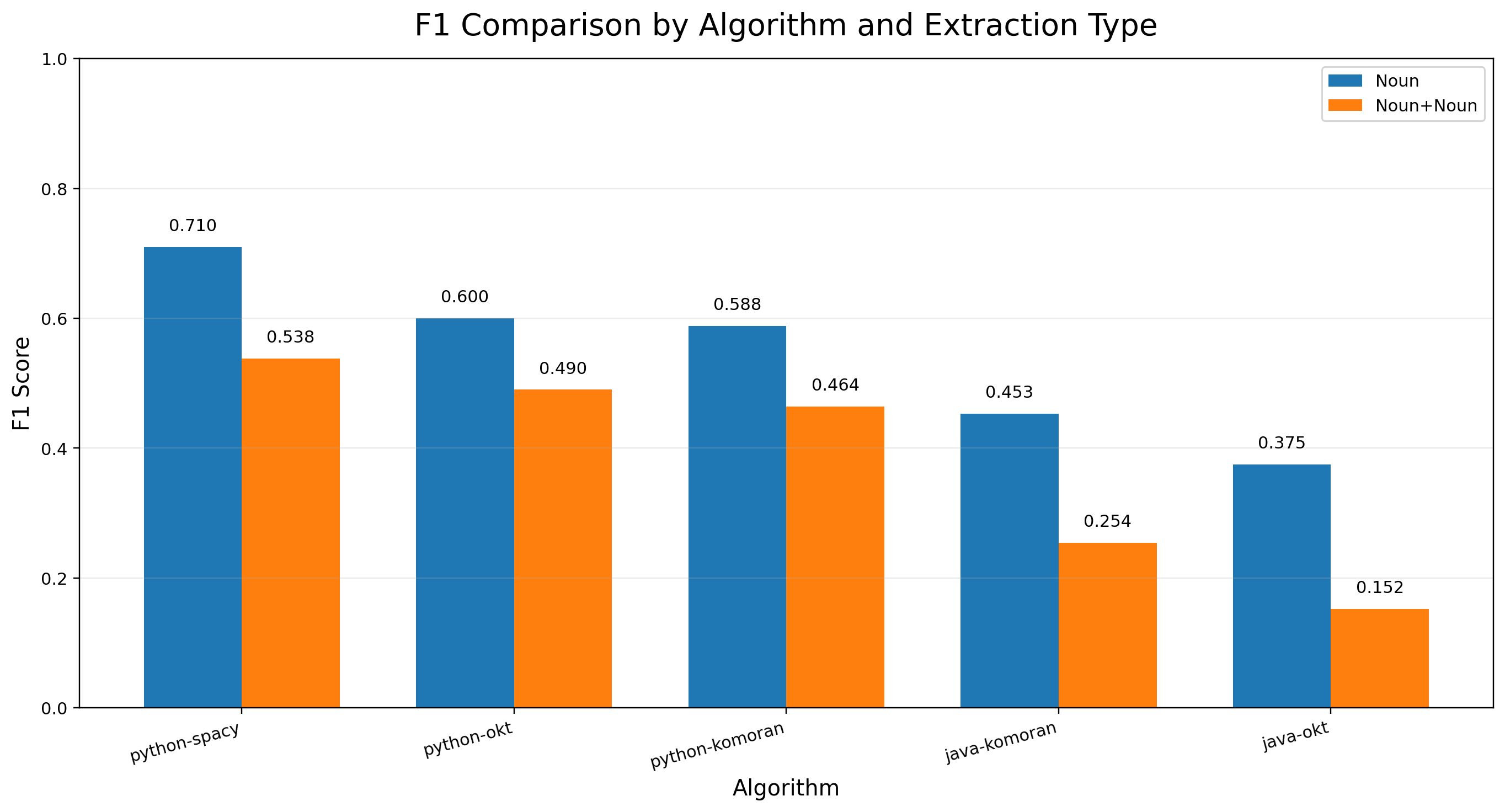
정확도 비교 결과, Python 계열 라이브러리들이 전반적으로 Java 계열보다 더 높은 성능을 보였다.
특히 python-spacy는 핵심 비교 대상인명사, 명사+명사 카테고리에서 모두 가장 우수한 결과를 기록하였다.이는 python-spacy가 단순히 많은 키워드를 추출하는 것이 아니라, 불필요한 키워드를 상대적으로 적게 포함하면서도 핵심 키워드를 안정적으로 추출했음을 의미한다.
반면, 명사+명사 계열은 대부분의 라이브러리에서 Precision은 높게 나타났지만 Recall은 낮은 경향을 보였다.즉, 복합 키워드는 비교적 정확하게 추출되지만, 실제 정답을 충분히 포착하지 못해 누락이 발생하는 경향이 있음을 확인할 수 있었다. 따라서 이번 실험에서는 단순 정밀도만이 아니라, Precision과 Recall의 균형을 반영하는 F1 Score를 중심으로 성능을 해석하였다.
2) 성능 지표
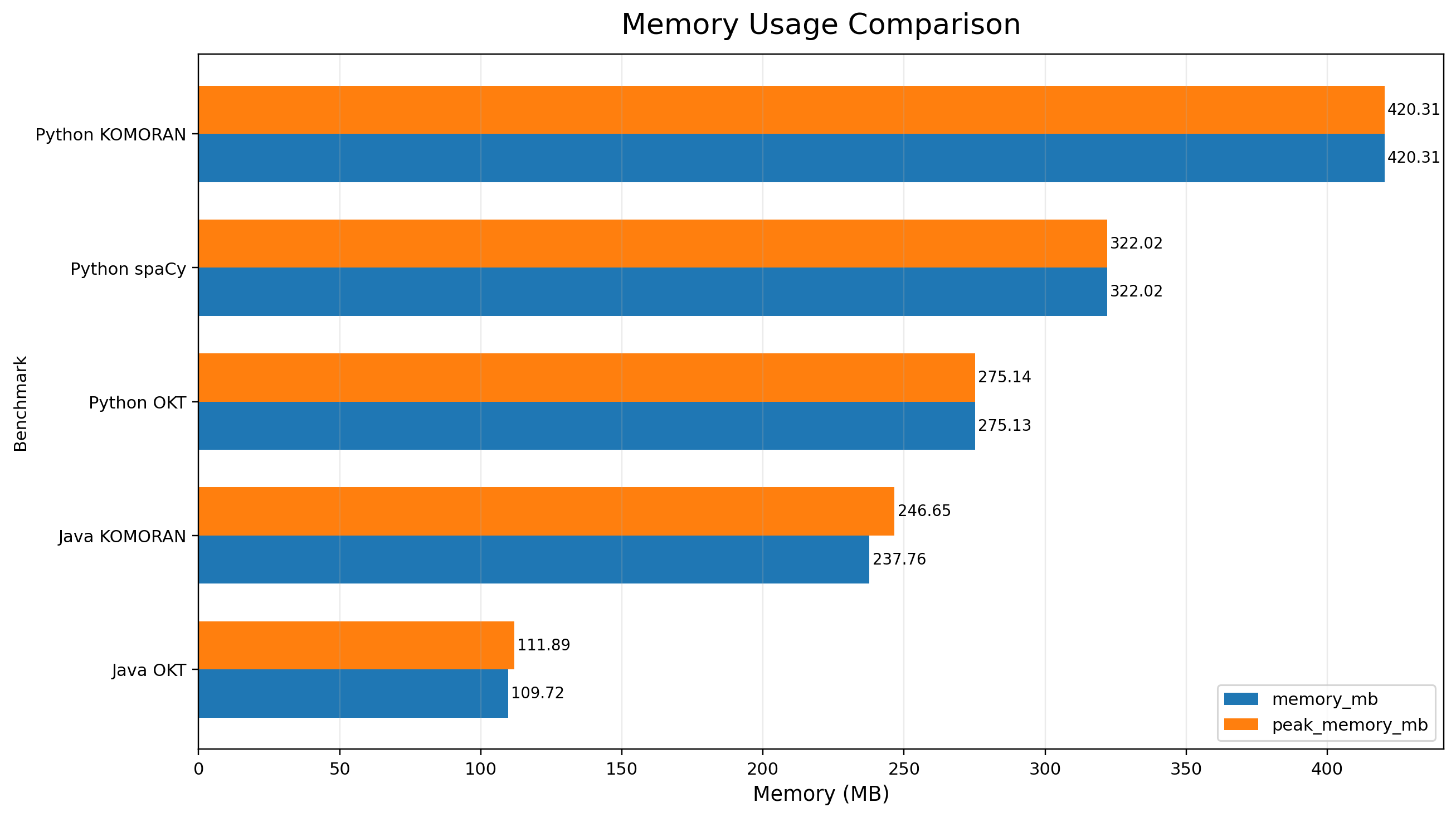
메모리 지표
| 알고리즘 | 런타임 | 메모리 사용량 (MB) | 피크 메모리 (MB) | Python Heap 피크 (MB) |
|---|---|---|---|---|
| KOMORAN | Python | 420.31 | 420.31 | 0.78 |
| OKT | Python | 275.13 | 275.14 | 0.69 |
| spaCy | Python | 322.02 | 322.02 | 99.78 |
| OKT | Java | 109.72 | 111.89 | - |
| KOMORAN | Java | 237.76 | 246.65 | - |
CPU 지표
| 알고리즘 | 런타임 | CPU User Time (s) | CPU System Time (s) | CPU Total / Process Time (s) |
|---|---|---|---|---|
| KOMORAN | Python | 4.49 | 0.15 | 4.64 |
| OKT | Python | 7.06 | 0.20 | 7.26 |
| spaCy | Python | 3.04 | 0.14 | 3.18 |
| OKT | Java | - | - | 7.85 |
| KOMORAN | Java | - | - | 10.14 |
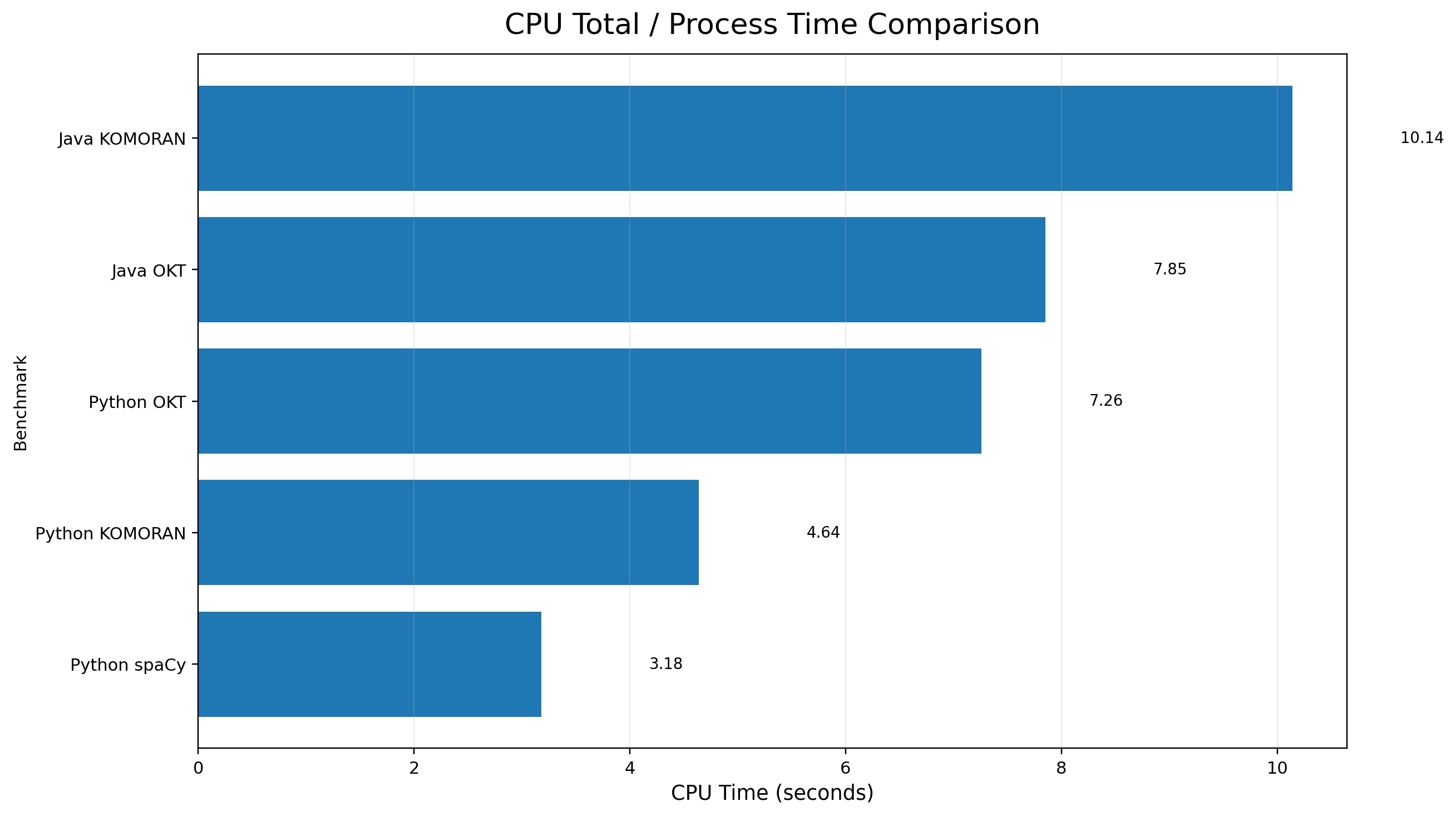
즉, 자원 효율만 놓고 보면 Java 계열이 일부 항목에서 유리한 면이 있었지만,이번 테스트의 핵심은 상담 키워드의 품질 확보이며, 단순 자원 절감만으로 라이브러리를 선택하기에는 정확도 차이가 분명했다.
또한 python-spacy의 경우 메모리 사용량이 Java OKT보다 높긴 하지만, 1GB 제한 내에서 충분히 동작 가능했고, 배치성 워커 환경에서 운영하기에 부담이 큰 수준은 아니었다.
따라서 실제 운영 관점에서도 python-spacy는 정확도 대비 수용 가능한 자원 사용량을 보여주었다고 판단하였다.
3. 라이브러리 선정
최종적으로 Python - spaCy를 형태소 분석 라이브러리로 선정하였다.
선정 이유는 다음과 같다.
- 이번 서비스의 키워드 추출 작업은 실시간 사용자 응답 경로가 아니라, 배치 또는 워커 기반으로 주기적으로 수행되는 후처리 작업에 가깝다. 따라서 수 밀리초 단위의 응답 속도 최적화보다, 키워드 품질과 정확도 확보가 더 중요한 요구사항이다.
python-spacy는 핵심 평가 지표인 F1 Score 기준으로 가장 우수한 성능을 보였다. 특히 명사, 명사+명사 추출 모두에서 가장 높은 정확도를 기록하여,실제 상담 데이터에서 의미 있는 키워드를 안정적으로 추출할 가능성이 가장 높다고 판단하였다.- 자원 사용량 측면에서도 절대적으로 가장 가벼운 라이브러리는 아니었지만, 이번 테스트 환경의 제한 범위(0.5 vCPU, 1GB Memory) 내에서 충분히 실행 가능했으며, CPU 누적 시간 또한 Python 계열 중 가장 우수하여 운영 가능성과 정확도의 균형이 가장 적절했다.
결론적으로, 이번 라이브러리 선정의 기준은 속도 최우선이 아니라 정확도 최우선이며,그 기준에서 python-spacy가 가장 적합한 후보라고 판단하여 최종 선정하였다.