이번에는 최근 본 상품 조회에 대한 고민과 결정 과정을 정리하겠습니다.
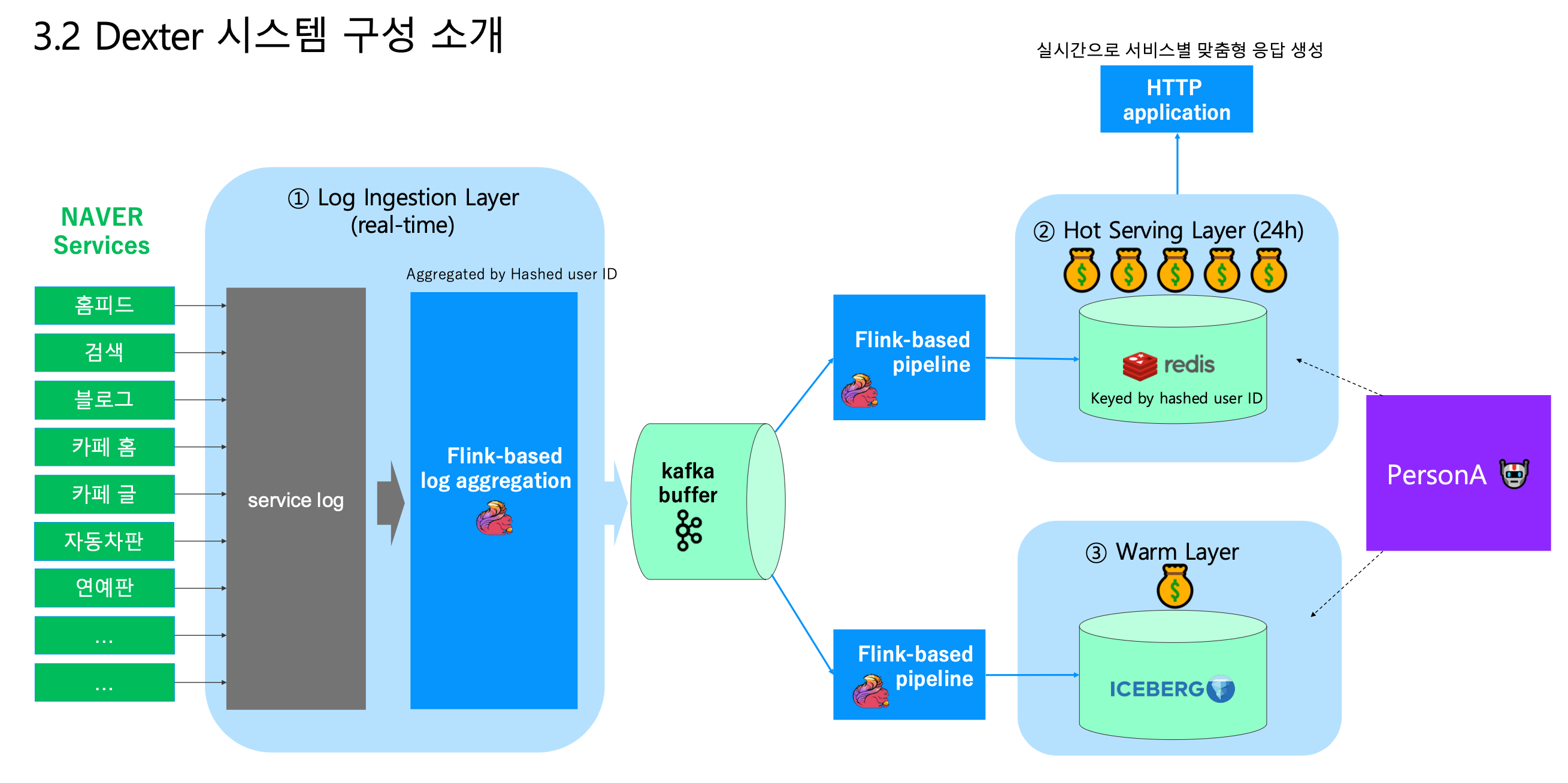
저희는 로그 수집 파이프라인을 설계할때 어떻게 추천 시스템까지 이어질까 고민이 되는 와중에, 네이버의 개인화 추천 서비스인 Dexture 시스템에서 소개된 개념을 참고했습니다.
[팀네이버 컨퍼런스 DAN25] 네이버 PersonA - 지금 나를 이해하는 AI (부제 : LLM 기반 사용자 메모리 구축과 실시간 사용자 로그 반영 시스템 구현)
이 시스템에서는, 서비스 로그의 활용을 두가지 레어어로 나눠서 적용을 합니다. 실시간으로 사용자의 관심사를 파악할 수 있게 redis에 저장하여, 맞춤형 응답을 생성하고, 이런 단기적인 관심사를 전부 iceberg에 적재하여 총체적인 사용자의 페르소나를 도출하는 파이프라인입니다.
1. 최근 본 상품 조회 기능 설계: 고민과 결정 과정
저희도 이 아키텍쳐를 참고해 로그 처리 구조를 크게 두가지 레이어로 나누어 생각했습니다.
- Hot Serving Layer: 실시간 서비스 운영에 필요한 처리
- Warm Layer: 적재 및 후처리, 배치 활용을 위한 처리
최근 본 상품 조회 기능은 이 중에서도 특히 실시간 응답성이 중요한 기능이었습니다. 사용자가 방금 본 상품을 곧바로 마이페이지나 추천 흐름에서 확인할 수 있어야 했기 때문입니다.
또한 저희는 최근 본 상품의 데이터를 단순히 사용자에게 보여주는 UI 기능으로 보지 않고 향후 LLM 추천에서 가중치로 활용할 수 있는 사용자 탐색 문맥으로도 의미가 있다 판단했습니다.
따라서 초기에는 다음 두가지 목적으로 동시에 만족시키는 구조를 고민했습니다.
- 프론트엔드에서 최근 본 상품을 빠르게 조회할 수 있어야 한다.
- 추천 시스템에서 최근 본 상품 및 태그 선호도를 사용자 context로 활용할 수 있어야 한다.
2. 초기 설계 : Redis를 활용한 실시간 처리
초기에는 실시간 처리를 위해 Redis를 사용하는 구조를 먼저 검토했습니다.
당시 아이디어는 다음과 같았습니다.
click_product_detail로그가 Kafka를 통해 들어오면- Kafka Consumer가 Redis를 업데이트하고
- 프론트는 Redis에서 최근 본 상품을 바로 읽어간다
- 동시에 추천 시스템에서는 Redis에 누적된 최근 본 상품 및 태그 점수를 활용한다
즉, Redis를 실시간 조회 저장소이자 추천용 context 저장소로 사용하는 방안이었습니다.
2.1 Redis 기반 설계안
초기 Redis 설계는 크게 두가지 자료구조로 나눠 구성했습니다.
1) 최근 본 상품 저장 (recent_views)
최근 본 상품 목록은 최신 순서 유지와 중복 제거가 중요했기 때문에, Redis의 ZSET(Sorted Set) 을 사용하려고 했습니다.
설계 의도
- 최신에 본 상품이 맨 위에 와야 한다
- 같은 상품을 여러 번 클릭해도 중복 저장되면 안 된다
- 프론트가 별도의 조합 없이 바로 렌더링할 수 있어야 한다
Key 구조
user:{member_id}:recent_views
예: user:user_sh_01:recent_views
자료구조
- ZSET
- score: 액션 타임스탬프
- value: 프론트 렌더링용 JSON 문자열
예를 들어 value는 아래처럼 설계했습니다.
{"product_id":"12345","product_name":"5G 요금제","target_url":"/product/detail/12345"}
즉, 최근 본 상품을 단순 ID 목록이 아니라 프론트가 바로 사용할 수 있는 형태로 저장하려고 했습니다.
최근 3개 또는 최근 N개 조회 방식
ZSET은 기본적으로 점수 오름차순으로 정렬되기 때문에, 가장 최근 본 상품을 가져오기 위해서는 역순 조회가 필요합니다.
예시 코드:
String redisKey = "user:" + userId + ":recent_views";
Set<String> recentProductIds = redisTemplate.opsForZSet().reverseRange(redisKey, 0, 2);
즉, reverseRange를 통해 가장 최근 점수가 높은 3개를 가져오는 방식이었습니다.
2) 태그 선호도 저장 (tag_scores)
두 번째로는 사용자가 자주 클릭한 상품의 태그를 누적하여, 최근 관심 태그 선호도를 추적하려고 했습니다.
이 또한 Redis의 ZSET을 사용하려고 했습니다.
설계 의도
- 어떤 태그를 많이 클릭했는지 누적 점수로 계산
- LLM 추천에서 “최근 관심 태그”로 활용
- 별도 집계 없이 빠르게 top tag를 조회
Key 구조
user:{member_id}:tag_scores
예: user:user_sh_01:tag_scores
자료구조
- ZSET
- value: tag 문자열
- score: 클릭 누적 횟수
예를 들어 로그에 아래 태그가 들어온다고 하면
"tags": ["영상OTT", "가족공유"]
Consumer는 이 배열을 순회하면서 각 태그의 점수를 1씩 올리는 구조를 생각했습니다.
예시 코드:
List<String> tags = event.getEvent_properties().getTags();
String tagScoreKey = "user:" + memberId + ":tag_scores";
if (tags != null && !tags.isEmpty()) {
for (String tag : tags) {
redisTemplate.opsForZSet().incrementScore(tagScoreKey, tag, 1.0);
}
}
이렇게 하면 같은 태그가 다시 등장할 때 자동으로 누적됩니다.
예를 들어
- 첫 번째 클릭:
["영상OTT", "가족공유"] - 두 번째 클릭:
["영상OTT", "가성비"]
이면 Redis 상태는 아래처럼 됩니다.
- 영상OTT: 2점
- 가족공유: 1점
- 가성비: 1점
즉, 사용자의 최근 탐색 문맥을 태그 점수로 쉽게 유지할 수 있다고 보았습니다.
2.2 Redis 기반 최근 본 상품 조회 흐름
초기 Redis 설계에서 최근 본 상품 조회 흐름은 다음과 같았습니다.
Write: Consumer 저장
상품 상세 조회 이벤트가 들어오면, Kafka Consumer가 Redis에 기록합니다.
설계 방향
- 최근 본 상품은 최신 순서 유지
- 동일 상품은 중복 저장 금지
- 최대 20개 또는 30개만 유지
- TTL은 7일 정도 유지
예시 로직:
String memberId = event.getMember_properties().getMember_id();
String productId = event.getEvent_properties().getProduct_id();
String redisValueJson = String.format(
"{\"product_id\":\"%s\", \"target_url\":\"/product/detail/%s\"}",
productId, productId
);
long currentTime = System.currentTimeMillis();
String redisKey = "user:" + memberId + ":recent_views";
redisTemplate.opsForZSet().add(redisKey, redisValueJson, currentTime);
redisTemplate.opsForZSet().removeRange(redisKey, 0, -21);
redisTemplate.expire(redisKey, Duration.ofDays(7));
Read: API 서버 조회
사용자가 마이페이지에서 최근 본 상품을 요청하면, API 서버는 DB를 보지 않고 Redis에서 바로 읽어 응답하는 구조였습니다.
예시 API
GET /api/v1/users/{member_id}/recent-views
예시 조회 코드
public List<String> getRecentViews(String memberId) {
String redisKey = "user:" + memberId + ":recent_views";
Set<String> recentViewJsons = redisTemplate.opsForZSet().reverseRange(redisKey, 0, 19);
return recentViewJsons != null ? new ArrayList<>(recentViewJsons) : Collections.emptyList();
}
즉, Redis에 저장된 JSON 문자열을 그대로 내려줘서 프론트가 바로 렌더링할 수 있도록 하는 구조였습니다.
2.4 초기 설계 당시 전체 흐름
초기 로그 서버 설계는 다음과 같은 형태였습니다.
[프론트/앱]
│ HTTP POST /v1/logs
▼
[API 서버]
│ kafkaTemplate.send("client-event-logs", memberId, payload)
▼
[MSK Kafka] client-event-logs 토픽
├──▶ [log-server]
│ - ZINCRBY tag_scores
│ - recent_views ZSET 갱신
│ - DLQ 처리
└──▶ [Kafka Connect]
- JSON → Parquet → S3
즉, 로그는 Kafka로 받고
- 한쪽은 실시간 처리를 위해 Redis 반영
- 한쪽은 분석을 위해 S3 적재
하는 구조를 생각했습니다.
하지만, Redis는 과하다고 판단했습니다. 그 이유와 최종 설계 확정을 다음 글에서 설명드리겠습니다.