앞에서는 어떤 로그를 어떻게 수집할 것인가에 대한 설계를 설명했습니다. 이제 다음 단계로 자연스럽게 이런 질문이 생겼습니다.
이렇게 수집한 로그를 어디에 저장해야 하는가?
저희 서비스의 초기 기획은 다음 두 가지 목표를 기반으로 했습니다.
- 사용자가 최근 본 상품을 다시 확인할 수 있도록 한다
- 사용자 행동 로그를 기반으로 고객 캐릭터 분류와 추천 시스템에 활용한다
즉, 단순히 로그를 저장하는 것이 아니라 추천 시스템과 고객 분석에 활용 가능한 데이터 파이프라인이 필요했습니다.
1. 기존 로그 적재 방식: DB (PostgreSQL)에 적재
초기에는 비교적 단순한 구조를 고려했습니다.
로그를 별도의 저장소로 보내기보다, **현재 사용 중인 운영 데이터베이스(PostgreSQL)** 에 바로 적재하는 방식이었습니다.
초기 구조는 다음과 같았습니다.
Client → Spring Server → Message Queue → PostgreSQL
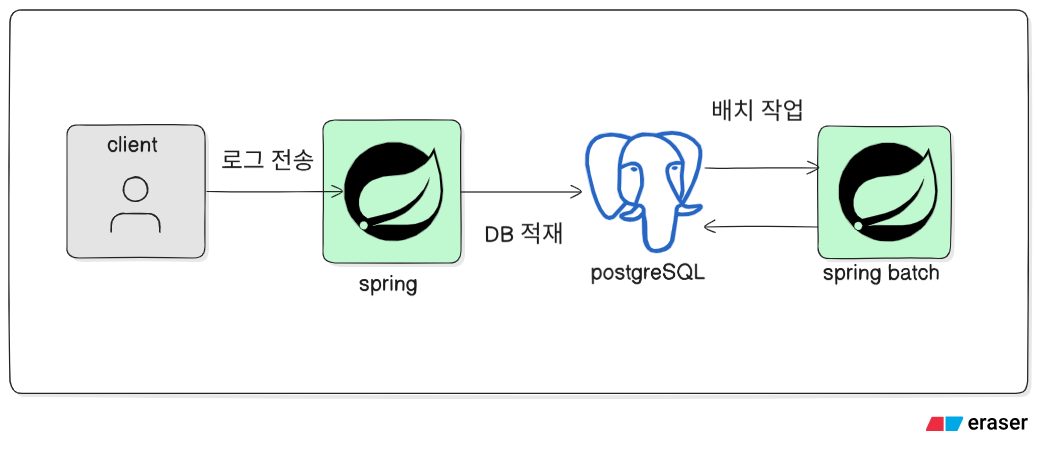
구체적인 흐름은 다음과 같습니다.
- 클라이언트가 로그 이벤트를 전송합니다.
- Spring 서버에서 로그를 검증합니다.
- 검증된 로그를 메시지 큐로 전달합니다.
- 메시지 큐에서 PostgreSQL에 로그를 적재합니다.
이 방식의 가장 큰 장점은 초기 구현이 매우 단순하다는 것이었습니다.
이미 운영 데이터베이스로 PostgreSQL을 사용하고 있었기 때문에
- 별도의 저장소를 구축할 필요가 없고
- 빠르게 개발을 시작할 수 있으며
- 데이터 접근도 쉬운 구조였습니다.
하지만 실제로 로그의 성격을 분석해 보면서, 이 구조에는 여러 문제가 있다는 것을 발견하게 되었습니다.
2. 운영 DB에 로그를 저장하려 했을 때 발생한 문제
이벤트 로그는 일반적인 서비스 데이터와 성격이 매우 달랐습니다.
회원 정보나 상품 정보처럼 정형 데이터 중심의 운영 데이터와 달리, 로그 데이터는 대량, 지속 누적, 반정형 데이터라는 특징을 가지고 있었습니다.
이 때문에 운영 DB에 직접 적재하는 방식은 여러 문제를 만들 수 있었습니다.
2-1. 로그 데이터는 양이 많고 지속적으로 누적되는 성격
클라이언트 이벤트 로그는 다음과 같은 사용자 행동에서 계속 발생합니다.
- 상품 클릭
- 상품 조회
- 비교하기 클릭
- 상품 상세 페이지 진입
- 위약금 페이지 조회
즉, 서비스 사용량이 증가할수록 로그 데이터는 계속해서 누적됩니다.
운영 DB에 그대로 저장할 경우 다음과 같은 문제가 발생할 수 있습니다.
- 스토리지 비용 증가
- 테이블 사이즈 증가
- 인덱스 관리 비용 증가
- 장기적으로 데이터 관리 복잡도 증가
2-2. 운영 DB 부하 가능성이 있다.
PostgreSQL은 다음과 같은 서비스 운영 데이터 처리에 최적화된 데이터베이스입니다.
- 회원 정보
- 상품 정보
- 가입 정보
- 결제 데이터
- 구독 정보
이러한 데이터는 정형 데이터이며 안정적인 트랜잭션 처리가 중요합니다.
하지만 여기에 대량의 로그 적재와 집계 쿼리까지 동시에 수행하면 다음 문제가 발생할 수 있습니다.
- INSERT 로그 처리 부하 증가
- 분석 쿼리로 인한 CPU 사용 증가
- 운영성 쿼리 성능 저하
즉, 운영 DB는 서비스 운영 데이터 처리에 집중하는 것이 더 적합하다고 판단했습니다.
2-3. 로그는 반정형 데이터 성격이 강하다.
이벤트 로그는 공통 컬럼외에도 이벤트별 속성이 달라질 수 있어 JSON 형태의 반정형 데이터가 많이 포함됩니다.
이처럼 JSON 기반 반정형 데이터가 많아지면
- 스키마 관리가 어려워지고
- 인덱스 관리가 복잡해지고
- 조회 성능이 떨어질 수 있습니다.
따라서 장기적으로는 운영 DB에 로그를 계속 쌓는 방식이 비효율적이라고 판단했습니다.
2-4 실제로 필요한 것은 “원본 로그”가 아니라 “집계 결과”
로그 저장 방식을 고민하면서 가장 중요한 사실을 발견했습니다.
서비스에서 실제로 필요한 것은 원본 로그 전체가 아니라, 로그를 가공한 결과 데이터였습니다.
예를 들어 서비스에서 사용하는 데이터는 다음과 같습니다.
- 최근 7일 클릭 수
- 상품 상세 조회 수
- 비교하기 클릭 여부
- 사용자별 행동 feature
- 추천 시스템 입력 feature
- 캐릭터 분류 지표
- 이탈 위험도 계산 지표
즉, 추천 시스템이나 캐릭터 모델이 사용하는 데이터는 원본 이벤트 로그가 아니라, 로그를 집계한 결과 데이터였습니다.
따라서 다음과 같은 결론에 도달했습니다.
원본 로그는 별도의 저장소에 보관하고 필요한 집계 결과만 운영 DB에 적재하는 구조가 더 적합하다.
3. S3, RDS 비용 구조 비교
저희는 로그 저장소 후보로 Amazon S3와 **Amazon RDS(PostgreSQL)** 를 비교했습니다.
gpt와 AWS 공식문서를 참고 한 결과 비용 구조에서도 S3가 월등히 높다는것을 보여주고 있습니다.
출처 : https://aws.amazon.com/ko/s3/pricing/
| 비교 항목 | Amazon S3 (+ Athena) | Amazon RDS (PostgreSQL) |
|---|---|---|
| 기본 과금 체계 | Serverless (사용한 만큼만) | Provisioned (인스턴스 고정비) |
| 저장 비용 (Storage) | 매우 저렴 (약 $0.023/GB) | 상대적으로 비쌈 (약 $0.115/GB, EBS) |
| 컴퓨팅 비용 | 없음 (Athena 조회 시에만 발생) | DB 인스턴스 가동 시간당 비용 발생 |
| 조회(Query) 비용 | 데이터 스캔량 비례 ($5/TB) | 인스턴스 사양(CPU/RAM)에 포함 |
| 확장성 | 무제한 (성능 저하 없음) | 로그 증가 시 스토리지/인스턴스 업그레이드 필요 |
| 유지보수 | 인덱스 관리 불필요 (파티셔닝 필요) | 인덱스 관리, Vacuum, 백업 비용 발생 |
이 비교를 통해 로그 저장소로는 S3가 훨씬 적합하다고 판단했습니다.
특히 다음 장점이 컸습니다.
- 대량 로그 저장에 적합
- 스토리지 비용이 매우 저렴
- 확장성 문제 없음
- 서버 관리 부담 없음
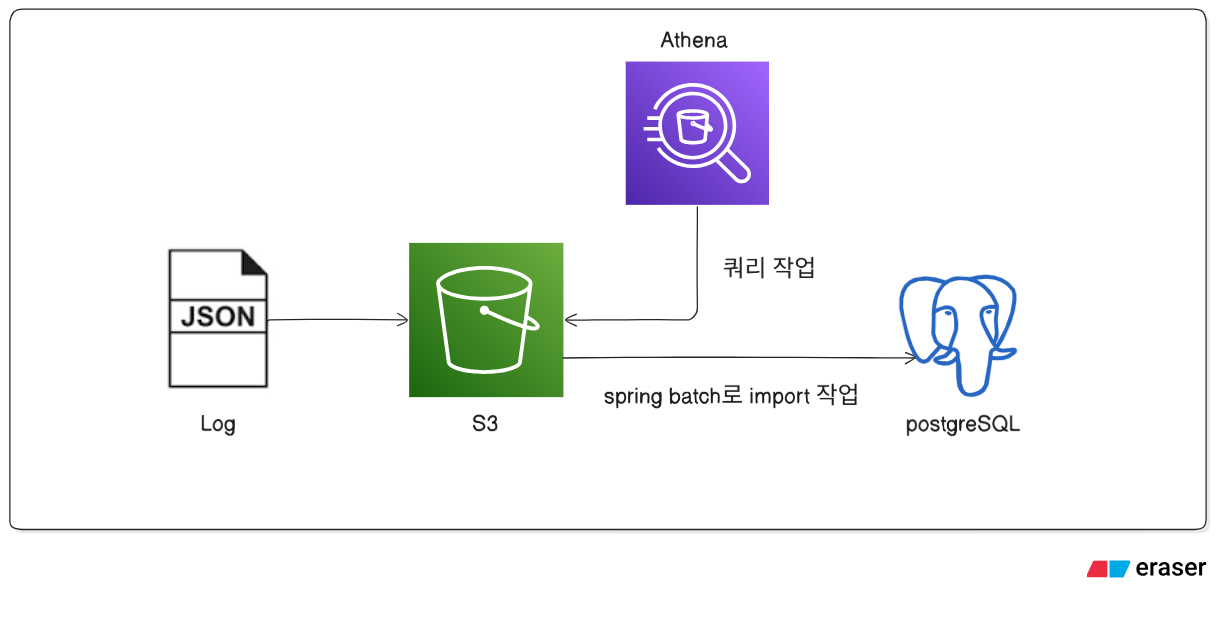
4. 최종 구조: 로그 저장소와 운영 DB 부리
이러한 이유로 로그 저장소와 서비스 운영 DB의 역할을 분리하기로 했습니다.
최종 구조는 다음과 같습니다.
- 원본 이벤트 로그 → S3 저장
- 로그 집계 → Athena SQL
- 집계 결과 처리 → Spring Batch
- 최종 서비스 데이터 → RDS(PostgreSQL)
즉 전체 구조는 다음과 같이 변경되었습니다.
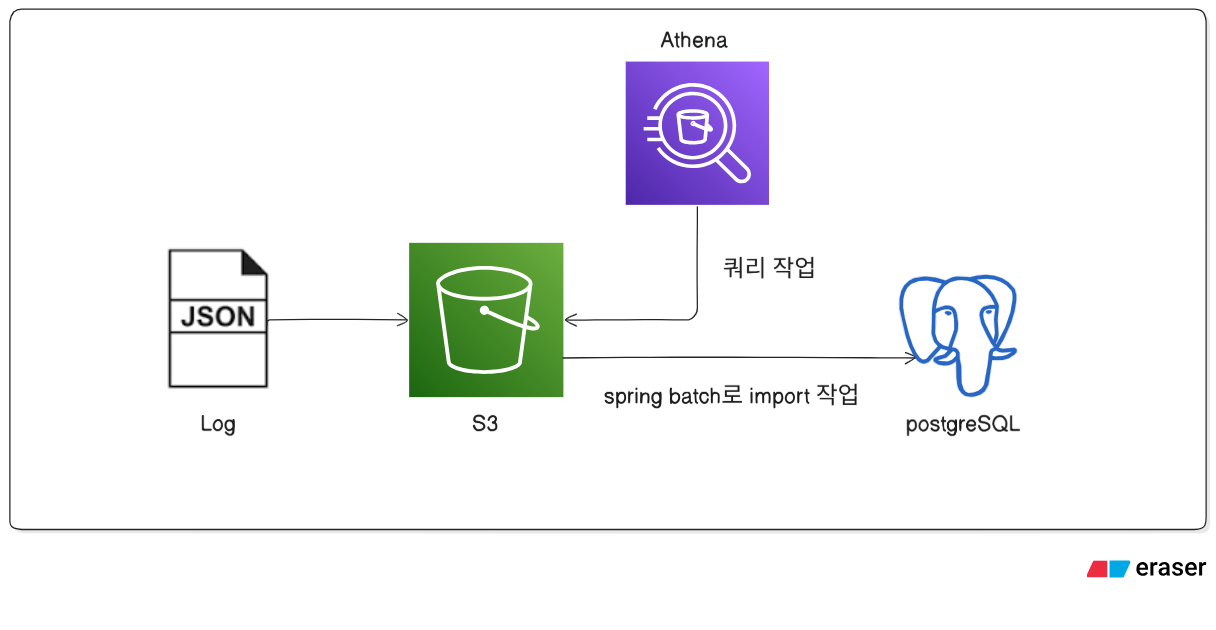
이 구조를 통해 다음과 같은 장점을 얻을 수 있었습니다.
- 운영 DB 부하 감소
- 로그 저장 비용 절감
- 대량 로그 처리 확장성 확보
- 추천 시스템에 필요한 Feature만 관리 가능
원본 로그 저장소(Data Lake)와 서비스 데이터베이스(Operational DB)를 분리하는 구조를 채택했습니다.
다음 섹션에서는 “최근 본 상품 조회” 에 대한 고민과 결정 과정을 이어서 정리하겠습니다.