1. 평가 모델 후보군 (NSMC 파인튜닝 완료 버전)
초기 리서치에서는 BERT, ELECTRA, RoBERTa 등 다양한 트랜스포머(Transformer) 기반 딥러닝 아키텍처를 폭넓게 검토하였으나, 7주라는 한정된 프로젝트 기간과 실시간 파이프라인의 효율성을 고려하여 가장 목적에 부합하는 핵심 모델 3가지로 압축하여 벤치마킹을 진행하였다.
[참고] 공통 베이스라인: NSMC Finetuned
선정된 3가지 모델은 모두 **NSMC(Naver Sentiment Movie Corpus) 데이터로 파인튜닝(추가 학습)을 마친 버전이다. NSMC는 네이버 영화 리뷰 20만 건을 긍정(1)/부정(0)으로 분류해 둔 한국어 자연어 처리 분야의 표준 감정 분석 데이터셋이다. 본 프로젝트의 1차 파이프라인 목표가 고객 상담 텍스트 내의 '부정적 감정(불만, 항의 등)'을 1차적으로 필터링**하는 것이므로, 이미 한국어 감정 분류(긍정 1 / 부정 0)에 최적화된 NSMC 모델들을 기본 베이스라인으로 채택하였다.
선정된 후보군 및 사유
1) KoELECTRA-base (NSMC Finetuned)
34GB의 방대한 한국어 텍스트(뉴스, 위키 등)로 학습된 모델을 기반으로, 긍정/부정 감정 분석에 완벽하게 적응하도록 튜닝된 모델이다. 통신사 고객센터의 특성상 고객이 화를 내더라도 ‘기본적인 존댓말과 정제된 어휘’를 사용하는 경우가 많은데, KoELECTRA는 표준어와 정제된 텍스트 환경에서 문맥의 미묘한 차이를 잡아내는 데 탁월한 성능을 보인다.
2) KLUE-RoBERTa-base (NSMC Finetuned)
한국어 NLP의 표준 벤치마크(KLUE) 모델을 감정 분석용으로 학습시킨 버전이다. 범용적이고 정제된 텍스트 이해도를 갖추고 있어, KoELECTRA의 도메인(구어체) 특화 성능을 객관적으로 비교하기 위한 대조군으로 사용한다.
3) KoELECTRA-small (NSMC Finetuned) ✅
DB 폴링 기반의 준실시간 파이프라인 구조상, 한정된 서버 메모리와 CPU 자원 제약을 대비한 경량화 대안 모델(Fallback)이다. Base 모델 대비 파라미터를 대폭 줄였을 때 불만 고객을 찾아내는 재현율(Recall)이 얼마나 방어되는지, 그리고 처리 속도(Throughput)는 얼마나 빨라지는지 확인하여 실시간 응답성과 인프라 비용 최적화의 기준점을 찾기 위해 선정했다.
[참고] KcBERT / KcELECTRA 및 KOTE 모델 벤치마크 제외 사유
감정 분석 리서치 과정에서 자주 언급되는 모델들에 대해서도 검토를 진행했으나, 비즈니스 도메인(통신사 상담)과의 적합성 및 아키텍처 효율성을 고려하여 최종 후보군에서 제외하였다.
1) KcBERT & KcELECTRA (Korean comments BERT/ELECTRA)
이준범(Beomi) 님이 네이버 뉴스 ‘댓글’을 수집해 만든 모델로, 신조어, 오타, 띄어쓰기 파괴, 욕설 등 노이즈가 심한 인터넷 구어체 처리에 강력한 모델이다.
- 제외 사유: 도메인 불일치 통신사 고객센터 상담 로그는 신조어나 반말 형태의 댓글(Comment)이 아니라, 상담원과의 대화로 이루어진 비교적 정중하고 정제된 대화록(Transcript)이다. 따라서 극단적인 인터넷 구어체에 편향된 Kc 시리즈보다는, 표준어와 뉴스/위키 기반으로 균형 잡힌 학습을 거친 KoELECTRA 시리즈가 우리 도메인에 훨씬 적합하다고 판단하였다.
2) KOTE (Korean Online Text Emotion)
스마일게이트 AI(Smilegate AI)에서 구축한 한국어 감정 데이터셋(또는 이를 학습한 모델)으로, 인간의 감정을 단순히 긍정/부정이 아니라 분노, 슬픔, 당황, 기쁨, 혐오 등 43가지의 매우 디테일한 심리 상태로 세분화하여 분류한다.
- 제외 사유: 우리의 1차 목적은 ‘디테일한 심리 분석’이 아닌 명확한 ‘부정(불만) 감정 필터링’이다 본 프로젝트의 감지 로직은 **[1단계: 모델을 통한 부정적 감정 필터링] + [2단계: 키워드 추출기를 통한 비즈니스 이탈 의도 매핑]** 형태의 하이브리드 파이프라인으로 설계되었다. KOTE는 사용자의 복잡한 ‘심리’를 파악하는 데는 훌륭하지만, 우리의 1단계 파이프라인이 요구하는 것은 “고객이 현재 불만/짜증(부정) 상태인가, 아닌가?”를 가르는 빠르고 명확한 **이진 분류(Binary Classification)**다. 43개의 감정으로 데이터를 쪼갠 뒤 이를 다시 긍정/부정으로 그룹핑하여 파이프라인에 태우는 것은 시스템 리소스 대비 심각한 오버엔지니어링(Over-engineering)이다. 따라서 아키텍처의 직관성과 효율성을 고려하여, 처음부터 긍정(1)/부정(0)을 명확히 제공하는 NSMC 기반 모델을 사용하는 것이 타당하다고 판단하였다.
Java vs Python
본 프로젝트는 메인 비즈니스 서버인 Java(Spring Boot) 내부에 딥러닝 모델을 직접 통합(Monolithic)하는 대신, 무거운 AI 연산을 전담하는 Python(FastAPI) 기반의 독립된 서버를 구성하는 MSA 아키텍처를 채택하였다.
초기 설계 단계에서 Java 환경 내에 딥러닝 모델을 내장하는 방안도 검토하였으나, 실시간 서비스의 안정성과 유지보수성을 위해 최종적으로 분리 구조를 선택했으며 그 사유는 다음과 같다.
Java 내부에서 딥러닝 모델을 구동하지 않는 4가지 핵심 이유
1) 전처리(Tokenizer) 오픈소스 생태계의 부재
최신 한국어 딥러닝 모델(KoELECTRA 등)은 텍스트를 수학적으로 분해하는 ‘서브워드 토크나이저(Subword Tokenizer)’ 전처리가 필수적이다. 전 세계 AI 생태계의 표준인 Python(HuggingFace)에서는 단 1줄의 코드로 전처리가 가능하지만, Java 생태계에는 이를 완벽히 지원하는 공식 라이브러리가 부재하다. 무리하게 Java로 모델을 포팅할 경우, 이 복잡한 전처리 로직을 밑바닥부터 재구현해야 하는 심각한 유지보수 비용(바퀴의 재발명)이 발생한다.
2) JVM 가비지 컬렉터(GC)로 인한 실시간 장애 리스크 (Stop-The-World)
딥러닝 추론은 내부적으로 대규모 행렬(Tensor) 객체를 메모리에 쉴 새 없이 생성하고 폐기한다. 이를 Java JVM 환경에서 구동할 경우, 가비지 컬렉터(GC)가 이 거대한 메모리 쓰레기를 치우기 위해 시스템 전체를 일시 정지시키는 **‘Stop-The-World’** 현상이 빈번하게 발생한다. 이는 실시간 API 서버에서 치명적인 응답 지연(Timeout)을 유발하는 핵심 원인이 된다.
3) JNI 통신 병목 및 처리 속도 저하
딥러닝의 실제 수학 연산은 Python이나 Java가 아닌, 하단에 있는 초고속 C++ 엔진이 수행한다. Python은 이 C++ 엔진과 네이티브하게 결합되어 있어 연산 속도가 매우 빠르지만, Java에서 이를 호출하려면 ONNX 포맷 변환 및 JNI(Java Native Interface)라는 무거운 다리를 건너야 한다. 이 과정에서 발생하는 데이터 직렬화/역직렬화 병목 현상으로 인해 처리 속도(Throughput)가 현저히 떨어지게 된다.
4) 완벽한 관심사의 분리 (장애 격리)
AI 추론은 CPU와 메모리를 극도로 소모하는 작업이다. 이를 비즈니스 로직과 한 서버에 두면, 트래픽 피크 타임에 AI 연산 부하로 인해 고객 정보 조회 같은 핵심 비즈니스 로직까지 함께 다운되는(Cascading Failure) 위험이 존재한다. 메인 서버는 안정적인 Java(Spring)가 전담하고, 무거운 연산은 Python API 서버로 완전히 분리(Decoupling)함으로써 AI 서버에 장애가 나더라도 메인 서비스는 100% 안전하게 구동되는 탄탄한 인프라를 구축하였다.
2. 테스트 데이터셋 준비
벤치마크 테스트를 위해서는 모델이 정답을 맞혔는지 채점할 ‘Golden Test Set’이 필수적이다.
1) 데이터 볼륨: 50건 진행 사유
머신러닝 벤치마크에는 통상 1,000건 이상의 데이터가 권장되나, 현재 확보된 실제 정제 상담 데이터 50건을 우선 활용하여 1차 타당성 검토(Feasibility Test)를 진행한다.
- 더미 텍스트를 무의미하게 섞어 양을 늘리는 것보다, 실제 발화 패턴이 담긴 50건으로 ‘진짜 성능’의 경향성을 파악하는 것이 타당하다.
- 이 결과(F1-Score)를 보고 모델 채택 여부를 결정한 뒤, 필요시 파인튜닝(Fine-tuning) 전략을 세우는 것이 애자일한 접근이다.
2) 라벨링 기준 (이탈 방지 목적)
단순한 감정(기쁨/슬픔)이 아닌, 비즈니스 핵심인 **‘이탈 위험 감지’**에 초점을 맞추어 0과 1로 라벨링(이진 분류)을 수행한다.
- **
0(부정/이탈 징후): **해지, 타사 비교, 강한 불만, 위약금 문의 등 1(긍정/중립): 단순 요금 조회, 부가서비스 가입, 정보 문의 등
3) 라벨링 수행 방식: LLM Prompting
50건이라는 볼륨은 파이썬 자동화 스크립트를 짜는 공수보다, LLM 웹 인터페이스(ChatGPT, Claude 등)를 활용해 직접 프롬프팅하는 것이 훨씬 효율적이다. 아래 프롬프트에 10~20건씩 나누어 상담 내용을 복붙하여 정답(Label) JSON을 획득한다.
LLM 라벨링 요청 프롬프트
당신은 통신사(LG U+) 고객 센터의 상담 내용을 분석하는 AI 전문가입니다. 아래 제공되는 JSON 배열 형태의 상담 데이터(id, 상담내용)를 읽고, 각 상담의 이탈 위험도를 판단하여 label 과 reason 필드를 추가한 새로운 JSON 배열을 출력해 주세요.
[라벨링 기준]
- label 0 (부정/이탈 징후): 해지 문의, 불만, 타사 비교 등 이탈 위험이 있는 상담
- label 1 (긍정/중립): 단순 조회, 요금 문의, 부가서비스 가입 등 이탈 위험이 없는 평범한 상담
[출력 형식]
반드시 아래 JSON 배열 형식으로만 응답하고, 다른 부연 설명은 절대 하지 마세요.
[
{
"id": "원본의 id",
"상담내용": "원본 상담내용",
"label": 0 또는 1,
"reason": "왜 이 라벨을 부여했는지에 대한 1~2줄의 짧은 사유"
}
]
[입력 데이터]
(여기에 10~20개의 JSON 객체를 복붙하여 입력)
3. 테스트 환경 구축
벤치마크의 객관성과 재현성을 확보하기 위해, 실제 운영 환경과 유사한 자원 제약 조건을 가진 독립된 가상 환경을 구축하여 테스트를 진행했다.
1) 테스트 데이터셋
실제 고객 센터 상담 내역 중 50건을 추출하여, LLM을 통해 본 프로젝트의 초기 목적이었던 **‘이탈 징후(0) / 긍정 및 중립(1)’**을 기준으로 1차 라벨링을 완료한 정답지 데이터.
2) 자원 제약 및 인프라 환경 (Docker)
실제 DB 폴링 기반 준실시간 AI 추론 서버가 운영될 환경의 한정된 리소스를 시뮬레이션하기 위해, Docker Compose를 활용하여 컨테이너에 엄격한 자원 제한을 걸고 테스트를 수행했다. 이는 상담 이벤트가 몰렸을 때 AI 서버가 OOM(Out of Memory)이나 타임아웃 없이 안정적으로 응답할 수 있는지 검증하기 위함이다.
services:
sentiment-bench:
build: ./sentiment-bench
volumes:
- ./data:/app/data
- ./sentiment-bench:/app/sentiment-bench
deploy:
resources:
limits:
cpus: "1.0"
memory: 2G
- CPU : 1.0vCPU 사용 제한
- Memory : 2GB 사용 제한
3) 평가 공정성 및 격리
여러 모델을 동시에 띄울 경우 발생하는 메모리 간섭이나 CPU 스레드 경합을 방지하기 위해, 파이썬 스크립트(benchmark.py) 내에서 순차적 독립 실행 로직을 구현했다.
- A 모델 로드 → 50건 추론 → 소요 시간 및
tracemalloc을 통한 Peak Memory 기록 → A 모델 메모리에서 완전 해제(Cache Clear) → B 모델 로드 - 이를 통해 각 모델이 온전히 자신만의 2GB 샌드박스 환경에서 평가받도록 하여 측정 지표의 신뢰도를 높였다.
4. 1차 테스트 결과(이탈 징후 라벨링 기준)
- 평가 지표 용어 설명 (부정 감정 기준)
이번 벤치마크의 모든 정확도 지표는 우리의 핵심 타겟인 **‘부정/불만 감정(0)’**을 얼마나 잘 잡아내는지를 기준으로 측정되었습니다.
- Accuracy (전체 정확도)
- 전체 50건의 상담 데이터 중, AI가 긍정(1)과 부정(0)을 올바르게 맞춘 종합 비율
- AI가 전체적으로 얼마나 똑똑하게 정답을 맞혔는가? (예: 0.88 = 88점)
- Precision(0) (정밀도)
- AI가 “이 고객 화났어요!(0)”라고 지목한 상담 중에서, 실제로 화난 고객이 얼마나 있는지를 나타내는 비율
- AI가 화났다고 경고했을 때, 그 말이 얼마나 믿을 만한가? (이 수치가 낮으면 AI가 너무 예민해서 평범한 고객도 화났다고 오해하는 것(오탐지)
- Recall(0) (재현율) ⭐️ 1차 필터링 핵심 지표
- 정답지에 있는 실제 화난 전체 고객 중에서, AI가 놓치지 않고 찾아낸 고객의 비율
- 진짜 숨어있는 불만 고객을 얼마나 샅샅이 찾아냈는가? (이 수치가 높아야 진짜 위험한 고객이 필터링을 빠져나가는 사고(미탐지)를 막을 수 있음
- F1-Score(0) (종합 점수)
- 정밀도(Precision)와 재현율(Recall)의 조화평균(균형값)
- 한쪽으로 치우치지 않고 얼마나 밸런스 있게 잘 작동하는지 보여주는 종합 점수
- Accuracy (전체 정확도)
1) 정확도 지표
| Model | Accuracy | Precision(0) | Recall(0) | F1-Score(0) |
|---|---|---|---|---|
| KoELECTRA-base | 0.6800 | 0.2222 | 0.1818 | 0.2000 |
| KLUE-RoBERTa-base | 0.7400 | 0.4000 | 0.3636 | 0.3810 |
| KoELECTRA-small | 0.7400 | 0.3750 | 0.2727 | 0.3158 |
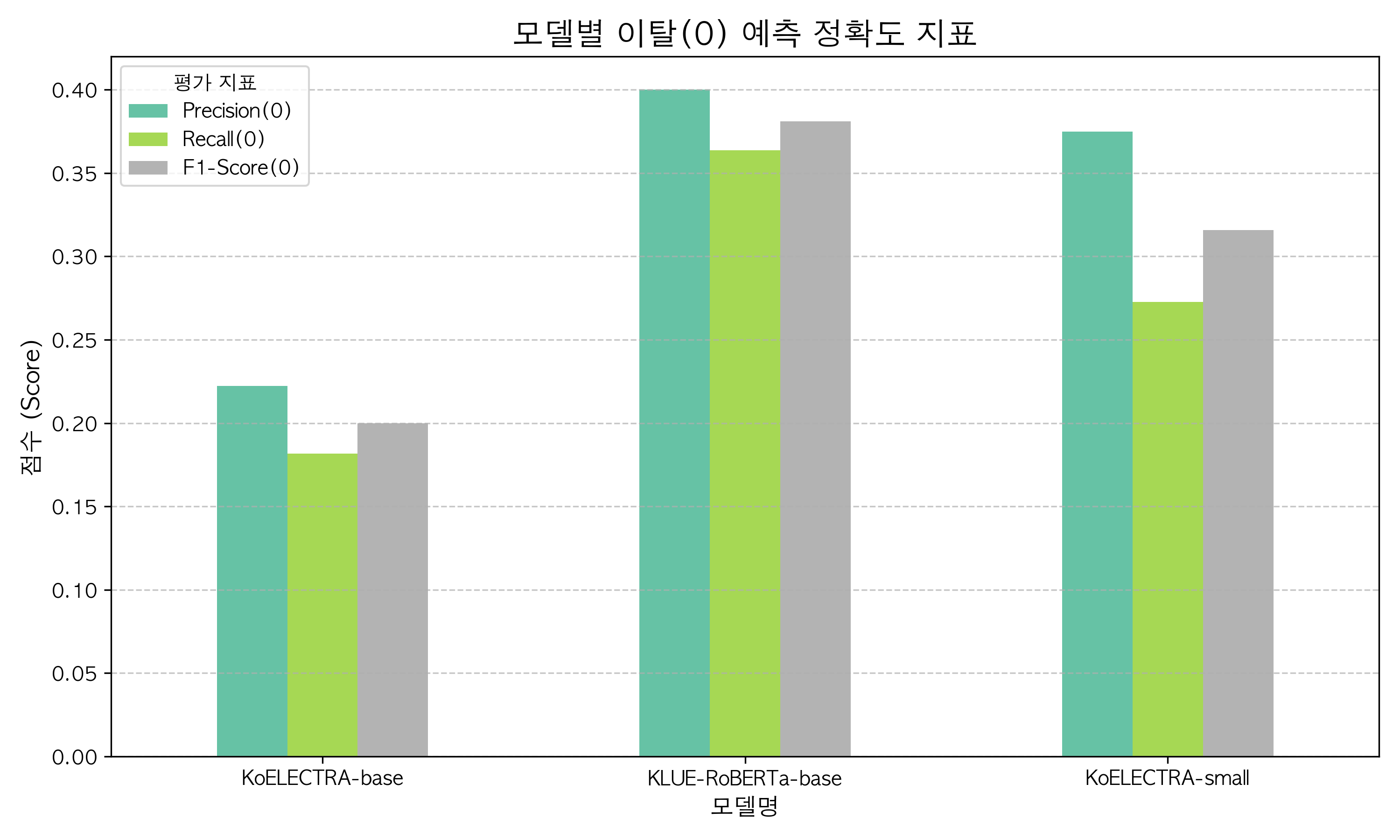
[정확도 해석]
정확도(Accuracy) 자체는 0.68 ~ 0.74로 준수해 보이나, 우리의 핵심 타겟인 이탈/부정(0) 클래스에 대한 예측력(F1-Score)은 세 모델 모두 0.2 ~ 0.38 수준으로 매우 저조하게 측정되었다. 가장 범용적인 성능을 자랑하는 대조군 모델인 KLUE-RoBERTa-base가 0.3810으로 그나마 가장 높은 수치를 기록했으나, 도입하기에는 턱없이 부족한 성능이다.
이는 단순한 AI 모델의 성능 부족이나 파라미터 크기의 문제가 아니다. NSMC 데이터로 파인튜닝된 모델들은 고객의 **‘순수 감정(화남, 짜증)’**을 잡도록 학습되었으나, 현재 테스트 데이터 정답지는 **‘이탈 의도(정중한 해지 문의 등)’**를 기준으로 라벨링 되어 있다. 즉, 모델이 학습한 도메인과 예측 타겟 간의 치명적인 **의미론적 갭(Semantic Gap)**이 존재하여 모델이 혼란을 겪고 있음을 명확히 보여주는 결과다.
2) 성능 지표
메모리 지표
| Model | Process Mem (MB) | Peak Mem (MB) | Python Heap Peak (MB) |
|---|---|---|---|
| KoELECTRA-base | 963.29 | 1229.02 | 40.55 |
| KLUE-RoBERTa-base | 1276.01 | 1782.29 | 9.08 |
| KoELECTRA-small | 1182.96 | 1782.29 | 12.02 |
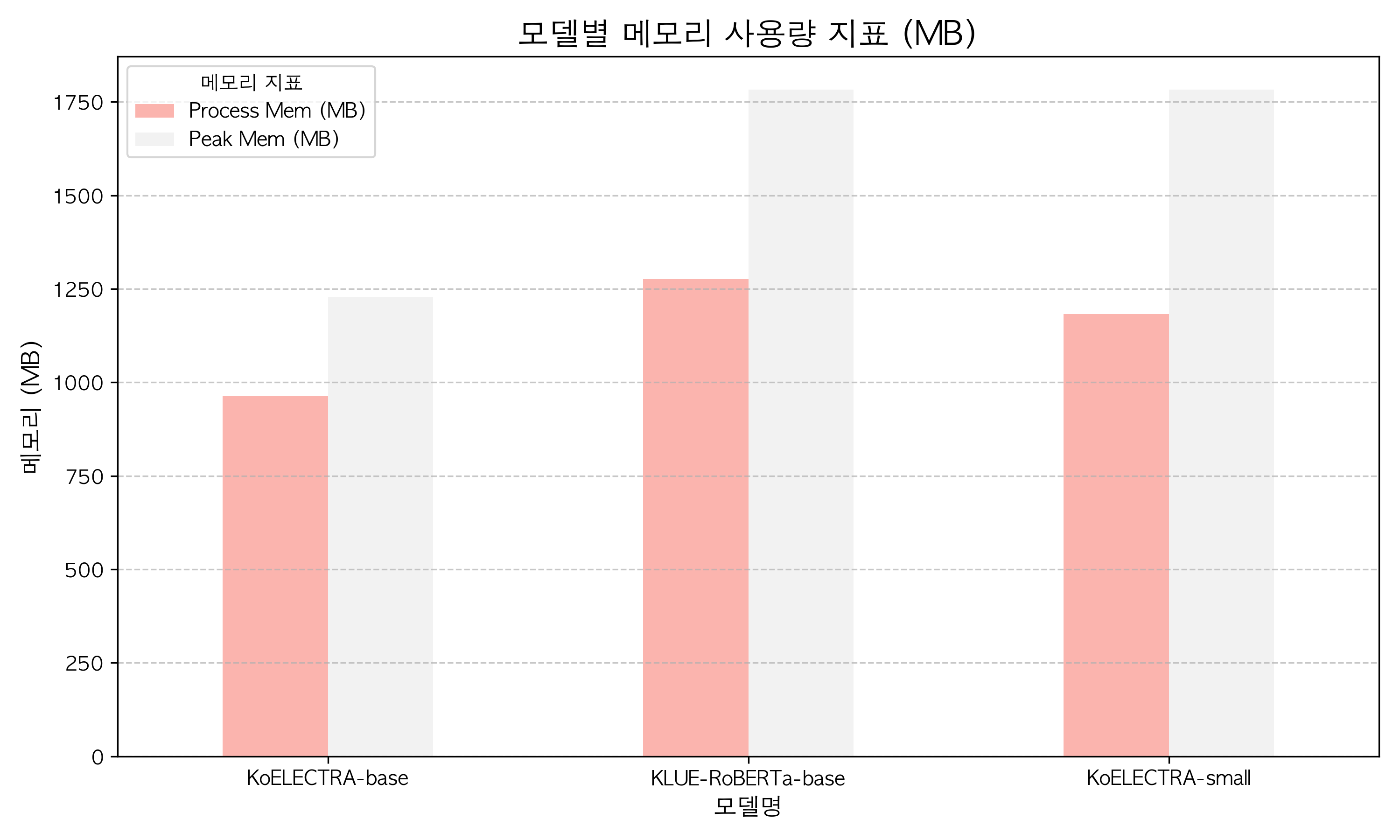
[메모리 지표 해석]
도커 환경 기준, AI 모델이 예측을 수행하는 과정에서 OS 레벨의 최대 물리 메모리(Peak Mem)가 어느 정도까지 치솟는지 확인했다. 세 모델 모두 파이썬 자체 메모리(Python Heap)는 10~40MB 수준으로 미미했으나, 실제 C/C++ 기반 연산 엔진이 차지하는 전체 Peak 메모리는 1.2GB ~ 1.78GB에 달했다. 특히 KLUE-RoBERTa-base 와 KoELECTRA-small 은 컨테이너 할당 한계치인 2GB에 근접하는 1.78GB를 기록했다. 이는 한정된 자원의 AI 서버가 짧은 주기로 DB를 폴링하며 동시다발적인 추론 요청(Concurrent Requests)을 처리할 때 Out Of Memory(OOM)가 발생할 잠재적 위험성을 시사하므로, 운영 환경 배포 시 API Request Queue 제한이나 스케일 아웃(Scale-out) 등 안정적인 메모리 제어 전략이 필수적이다.
CPU 및 속도 지표
| Model | Runtime (s) | Throughput (ops/s) | CPU User (s) | CPU System (s) | CPU Total (s) |
|---|---|---|---|---|---|
| KoELECTRA-base | 764.32 | 0.07 | 665.41 | 88.13 | 753.54 |
| KLUE-RoBERTa-base | 1085.81 | 0.05 | 669.66 | 95.38 | 765.04 |
| KoELECTRA-small | 266.20 | 0.19 | 225.80 | 35.65 | 261.45 |
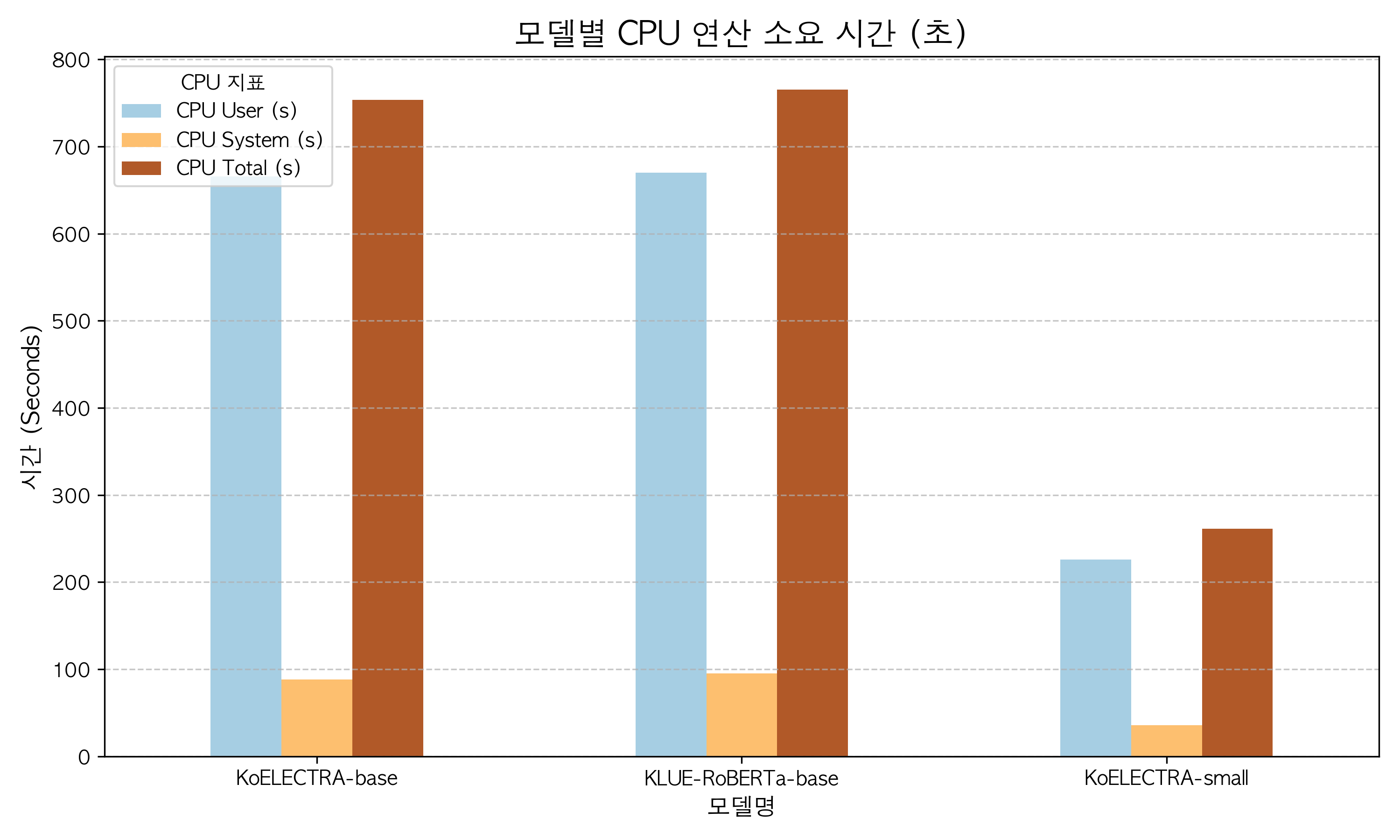
[CPU 및 속도 지표 해석]
자원 효율만 놓고 보면 **KoELECTRA-small의 압도적인 성능 우위**가 확인되었다. Base 모델들이 700~1000초 대의 런타임과 750초 이상의 CPU 총 점유 시간을 기록한 반면, Small 모델은 파라미터를 경량화한 덕분에 약 3~4배 빠른 처리 속도(0.19 ops/s, 런타임 266초)를 보여주었다. DB 폴링(Polling) 기반의 준실시간 파이프라인 구조에서는 짧은 폴링 주기 내에 새로 유입된 데이터를 병목 없이 즉각적으로 쳐내는 **연산 속도(Low Latency)**와 Throughput이 서비스 품질 및 인프라 비용과 직결된다. 따라서 Small 모델은 CPU 점유 시간을 대폭 아껴주어 비용 최적화 측면에서 가장 유리한 대안임을 입증했다.
3) 1차 벤치마크 종합 결론
1차 테스트 결과, 자원 효율과 인프라 비용 최적화 관점에서는 약 3~4배 빠른 처리 속도를 보여준 KoELECTRA-small이 가장 이상적인 대안(Fallback)으로 확인되었다.
하지만 **정확도 측면(한계 확인)에서는 세 모델 모두 이탈 징후(0)를 잡아내는 핵심 지표인 F1-Score가 0.2 ~ 0.38 수준으로 매우 낮게 측정되며 뚜렷한 한계를 보였다. 이는 단순한 모델의 성능(파라미터 수 등) 부족이 아니라, 모델이 학습한 도메인(순수 감정)과 예측 타겟(이탈 의도) 간의 의미론적 차이(Semantic Gap)** 때문으로 분석된다. 즉, NSMC 데이터로 파인튜닝된 감정 분석 모델 하나만으로는 ‘정중한 어조의 해지 문의’와 같은 비즈니스적 이탈 의도를 잡아내는 데 근본적인 무리가 있음이 입증된 것이다.
따라서 무거운 AI 모델은 본연의 임무이자 가장 잘할 수 있는 영역인 ‘순수 부정 감정(불만, 항의 등)’을 1차적으로 필터링하는 데만 집중하도록 역할을 축소하는 것이 타당하다. 그리고 AI가 놓치는 ‘정중한 해지/이탈 의도’는 별도의 비즈니스 키워드 추출기가 담당하는 하이브리드 아키텍처로 파이프라인 설계를 변경하기로 결정했다.
이러한 가설과 새로운 아키텍처의 효용성을 검증하기 위해, 기존 데이터의 라벨링 기준을 ‘이탈 의도’에서 **‘순수 감정’**으로 전면 재조정하여 2차 벤치마크를 이어서 진행한다.
5. 1차 벤치마크 결과 리뷰 및 파이프라인 전략 수정
1) 인사이트: 이탈 징후는 ‘감정(Emotion)’이 아니라 ‘의도(Intent)’다
테스트 결과, NSMC(네이버 영화 리뷰)로 학습된 모델은 문장의 ‘긍정/부정’을 분류하는 데는 특화되어 있으나, 실제 통신사 상담의 이탈 징후와는 일치하지 않는 경우가 많았다.
- **유형 A (감정 부정 / 의도 유지):** ”인터넷이 너무 느려요! 빨리 고쳐주세요!” (분노하지만 이탈 의사 없음)
- **유형 B (감정 중립 / 의도 이탈): **“수고 많으십니다. 약정 만료인데 위약금 조회 좀 해주세요.” (정중하지만 명백한 이탈 징후)
초기 라벨링에서는 유형 B를 ‘이탈(0)’로 채점했으나, 모델은 정중한 말투로 인해 ‘중립/긍정(1)’으로 예측하여 점수가 하락했다. 여기서 감정 분석 모델에게 복잡한 ‘이탈 징후’까지 억지로 학습시키는 것은 리소스 및 유지보수 측면에서 비효율적이라 판단했다.
2) 해결 방안: 관심사의 분리(Separation of Concerns)를 통한 하이브리드 아키텍처 도입
AI 모델 하나에 모든 책임을 지우는 대신, 딥러닝 감정 분석 + 룰베이스(규칙 기반) 비즈니스 키워드 추출이라는 두 가지 파이프라인을 분리하여 병렬로 운영하는 전략으로 수정한다.
- **감정 분석 모델(AI):** 본연의 임무인 **‘순수 부정 감정(짜증, 불만)’**을 필터링하는 데만 집중한다.
- **비즈니스 키워드 추출기(Rule-based):** 별도로 개발된 키워드 추출 로직을 통해 ‘해지’, ‘위약금’, ‘타사 이동’ 등의 단어가 매핑되면, 고객의 감정과 무관하게 즉시 **‘이탈 징후’**로 판별한다.
이러한 하이브리드 구조는 향후 새로운 이탈 정책 단어를 추가 요청할 때, 무거운 딥러닝 모델을 재학습할 필요 없이 키워드 사전만 업데이트하면 되므로 확장성과 유지보수성 면에서 압도적으로 유리하다. 이를 검증하기 위해, 데이터 라벨링 기준을 ‘순수 감정’으로 변경하여 2차 벤치마크 테스트를 진행할 예정이다.
3) 2차 벤치마크를 위한 데이터 재라벨링 (순수 감정 기준)
기존 ‘이탈 징후’ 기준으로 작성되었던 50건의 정답지(Golden Set)를 **‘순수 감정(Sentiment)’** 기준으로 전면 재라벨링했다. 기존 파일(golden_test_set_50.json)은 히스토리 관리를 위해 보존하고, 신규 데이터셋은 sentiment_test_set_50.json으로 명명하여 테스트를 격리했다.
라벨링 기준 변경점
- **기존 (이탈 의도):** 정중하게 해지를 문의해도 이탈이므로 0(부정/이탈)으로 처리.
- **변경 (순수 감정):** 정중하게 해지를 문의하면 감정적 동요가 없으므로 1(중립/긍정)로 처리. 오직 불만, 화, 짜증 등 ‘부정적 감정’이 드러난 경우에만 0(부정)으로 처리. (해지 의도는 별도 키워드 추출기가 담당)
LLM 라벨링 요청 프롬프트
- 효율적이고 일관된 라벨링을 위해 아래 프롬프트를 활용하여 50건의 데이터를 재가공했다.
당신은 통신사(LG U+) 고객 센터의 상담 내용을 분석하는 AI 감정 분석 전문가입니다. 아래 제공되는 JSON 배열 형태의 상담 데이터(id, 상담내용)를 읽고, 고객의 **‘순수한 감정 상태’**만을 판단하여 label 과 reason 필드를 추가한 새로운 JSON 배열을 출력해 주세요.
[라벨링 기준]
- **label 0 (부정): **상담 내용에 불만, 짜증, 화냄, 항의 등 부정적인 감정 뉘앙스가 명확히 섞여 있는 경우
- label 1 (긍정/중립): 단순 정보 조회, 요금 수납, 친절한 문의, 부가서비스 신청 등 감정적 동요가 없는 평범한 상담 (⚠️핵심 주의사항: 대화 내용이 ‘해지, 타사 이동, 위약금 문의’이더라도 고객이 화를 내지 않고 평온하고 정중하게 묻는다면 무조건 1(중립)로 분류하세요. 이탈 여부는 감정이 아니므로 다른 시스템에서 처리합니다.)
[출력 형식]
반드시 아래 JSON 배열 형식으로만 응답하고, 다른 부연 설명은 절대 하지 마세요.
[
{
"id": "원본의 id",
"상담내용": "원본 상담내용",
"label": 0 또는 1,
"reason": "왜 이 감정 라벨을 부여했는지에 대한 1~2줄의 짧은 사유"
}
]
6. 2차 테스트 결과(순수 감정 라벨링 기준)
sentiment_benchmark_results.csv
1) 정확도 지표
| Model | Accuracy | Precision(0) | Recall(0) | F1-Score(0) |
|---|---|---|---|---|
| KoELECTRA-base | 0.7800 | 0.1111 | 0.2500 | 0.1538 |
| KLUE-RoBERTa-base | 0.8400 | 0.3000 | 0.7500 | 0.4286 |
| KoELECTRA-small | 0.8800 | 0.3750 | 0.7500 | 0.5000 |
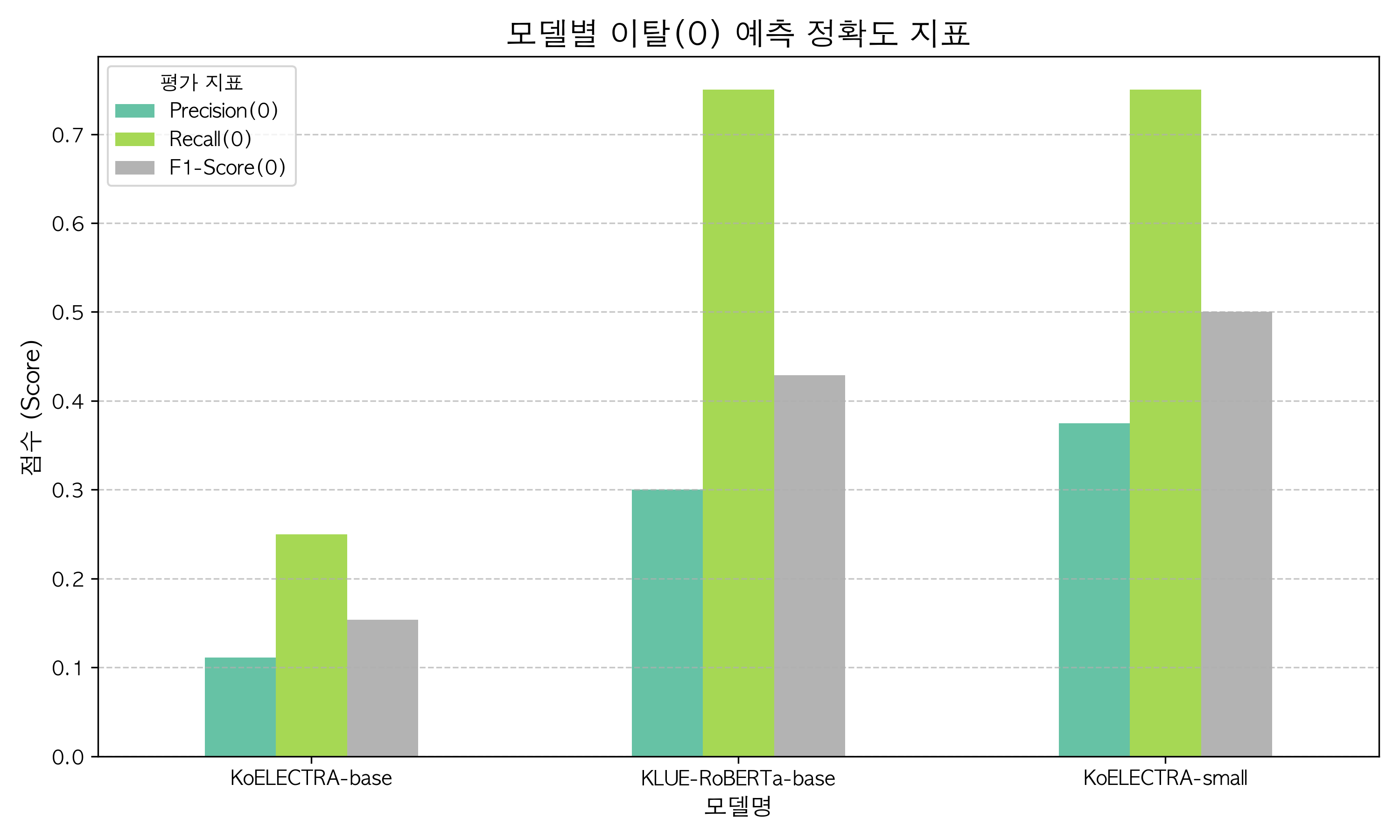
[정확도 해석]
- **의미론적 갭(Semantic Gap) 해소:** 라벨링 기준을 ‘이탈 의도’에서 ‘순수 감정’으로 변경하자,
KoELECTRA-small의 전체 정확도(Accuracy)가 1차 테스트(0.74) 대비 **0.88(88%)**로 유의미한 상승폭을 기록했다. 이는 감정 분석 전용으로 파인튜닝된 모델에게 본연의 도메인(순수 감정)을 판별하게 함으로써 모델이 혼란을 벗어나 제 성능을 발휘하기 시작했음을 의미한다. - **1차 필터링 목적 달성 (재현율 0.75):** 이번 하이브리드 아키텍처에서 AI 모델의 핵심 임무는 “화를 내거나 불만을 가진 고객을 최대한 놓치지 않고 1차로 걸러내는 것”이다. 타겟 클래스(부정/0)에 대한 **재현율(Recall)이 0.75(75%)**로 1차 테스트(0.27) 대비 폭발적으로 상승하여, 도입 시 충분히 유의미한 불만 고객 포착 능력을 입증했다.
- **클래스 불균형에 의한 F1-Score 현상: 높은 재현율에도 불구하고 F1-Score가 0.50에 머무른 이유는 데이터의 극심한 불균형(Class Imbalance)** 때문이다. 정답지에 실제 화를 낸 고객(0)의 비율이 극소수로 줄어들면서, AI가 선의의 평범한 고객을 조금만 부정으로 오탐지(False Positive)해도 정밀도(Precision)가 크게 깎이는 통계적 착시가 발생했다. 하지만 이는 2차 파이프라인(키워드 추출)에서 교차 검증되므로 시스템 전체의 치명적인 결함이 아니다.
2) 성능 지표
메모리 지표
| Model | Process Mem (MB) | Peak Mem (MB) | Python Heap Peak (MB) |
|---|---|---|---|
| KoELECTRA-base | 987.66 | 1247.82 | 40.55 |
| KLUE-RoBERTa-base | 1287.46 | 1789.46 | 9.08 |
| KoELECTRA-small | 1194.32 | 1789.46 | 12.02 |
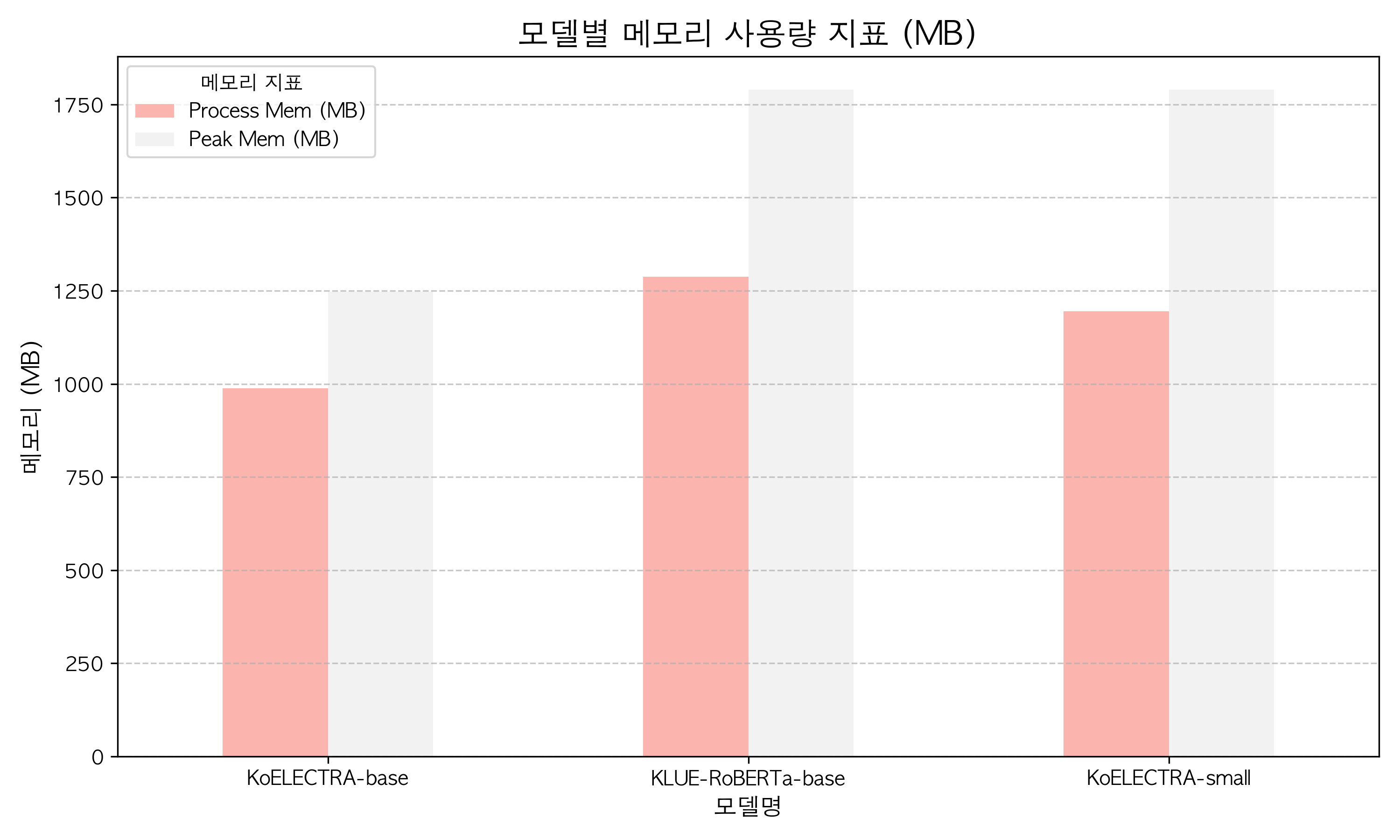
[메모리 지표 해석]
KLUE-RoBERTa-base와KoELECTRA-small모두 도커 컨테이너의 할당 한계치인 2GB를 넘지 않는 1.78GB 선에서 구동됨을 확인했다.
CPU 및 속도 지표
| Model | Runtime (s) | Throughput (ops/s) | CPU User (s) | CPU System (s) | CPU Total (s) |
|---|---|---|---|---|---|
| KoELECTRA-base | 830.79 | 0.06 | 721.00 | 100.66 | 821.66 |
| KLUE-RoBERTa-base | 883.07 | 0.06 | 757.31 | 113.42 | 870.73 |
| KoELECTRA-small | 302.30 | 0.17 | 255.99 | 42.00 | 297.99 |
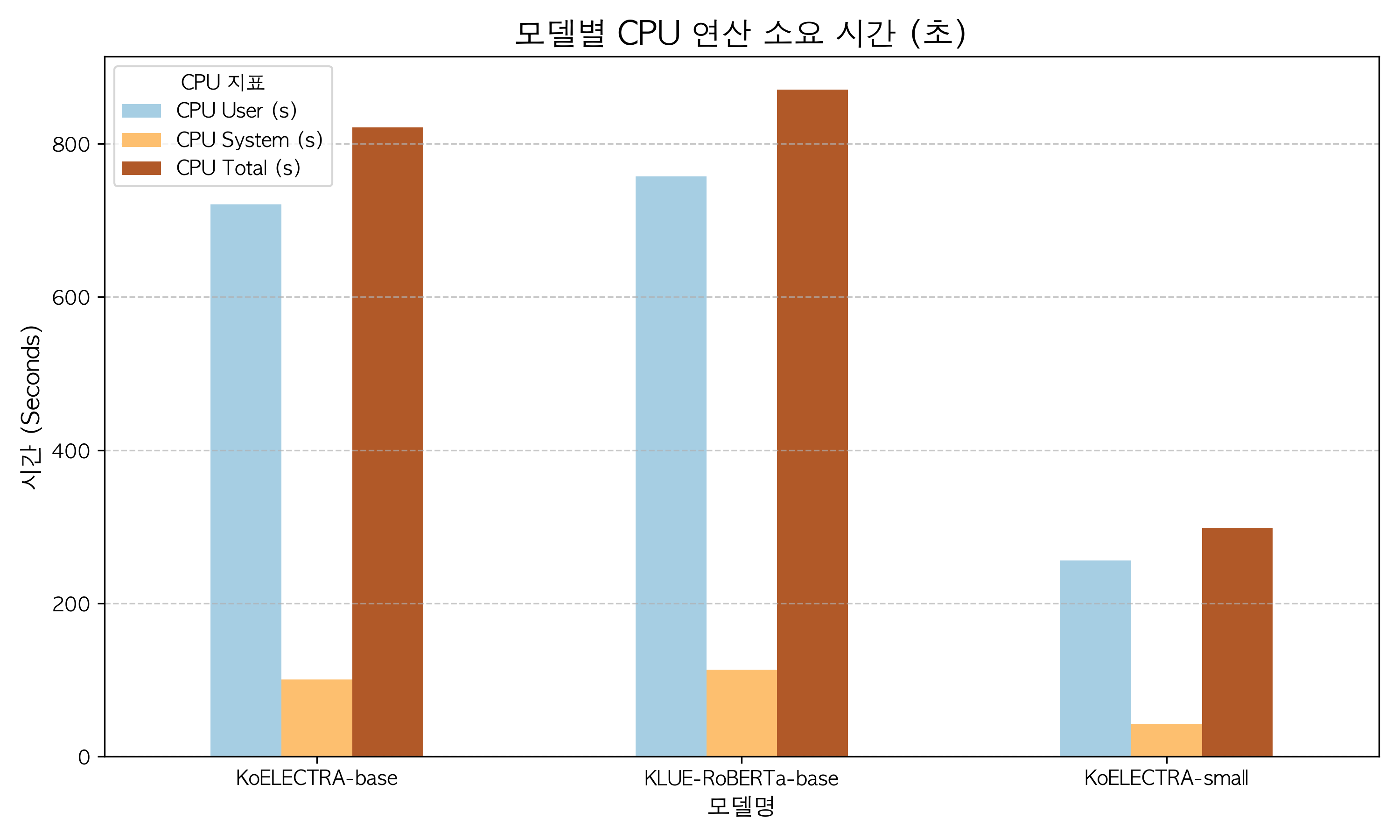
[CPU 및 속도 지표 해석]
- 압도적인 연산 속도 (Throughput): 파라미터가 경량화된
KoELECTRA-small의 진가가 발휘된 지표다. Base 모델들이 800초대의 런타임을 기록한 반면, Small 모델은 단 302.30초 만에 처리를 완료하여 **약 2.7~3배 빠른 초당 처리 속도(0.17 ops/s)**를 기록했다.
3) 지표 심층 분석
[Precision(0) 정체 현상에 대한 해석]
2차 테스트에서 Precision(0)이 1차와 유사한 수준(0.37)에 머무른 것은 모델의 한계가 아니다. 라벨링 기준 변경으로 타겟 데이터(실제 부정 감정)가 극소수로 줄어든 **극심한 클래스 불균형(Class Imbalance)** 환경에서, 모델의 미세한 오탐지(False Positive)가 정밀도 수치 하락에 치명적으로 작용한 수학적 착시 현상이다.
[Base 모델 성능 저하 원인 분석]
파라미터가 더 큰
KoELECTRA-base의 정확도(Acc 0.78, Recall 0.25)가 Small 모델(Acc 0.88, Recall 0.75)보다 현저히 떨어진 이유는 **‘도메인 과적합(Domain Overfitting)’ 및 ‘일반화(Generalization) 성능의 차이’**로 분석된다. 통상적으로 파라미터가 클수록 언어 이해력이 높지만, NSMC 파인튜닝 과정에서 Base 모델은 영화 리뷰 특유의 어휘 패턴(배우, 연출 등)에 과도하게 최적화된 반면, Small 모델은 상대적으로 적은 용량으로 인해 세부 어휘보다는 ‘부정적 뉘앙스’ 자체를 범용적으로 학습(일반화)하게 되었다. 그 결과, 영화 관련 어휘가 전혀 등장하지 않는 ‘통신사 상담’이라는 낯선 도메인(Cross-Domain) 환경에서는 유연성이 높은 Small 모델이 압도적인 성능을 낸 것이다. 이는 **‘도메인이 전환되는 실무 환경에서는 모델의 크기(Capacity)가 클수록 오히려 과적합의 함정에 빠지기 쉽다’**는 MLOps의 실무적 교훈을 재확인시켜 준다.
7. 최종 모델 선정 및 근거
최종적으로 1차 필터링(순수 감정 분석) 단계에 적용할 AI 모델로 **Python 기반의 KoELECTRA-small (NSMC Finetuned)**을 선정하였다.
이번 벤치마크에서 입증된 최종 선정 근거는 다음과 같다.
첫째, 1차 필터링의 핵심 요구사항인 ‘높은 재현율(Recall)’을 가장 안정적으로 충족한다.
새롭게 도입된 하이브리드 파이프라인에서 AI 모델의 역할은 이탈 여부를 최종 확정 짓는 것이 아니라, “조금이라도 부정적인 감정 뉘앙스를 띠는 고객을 1차로 모두 걸러내는 것”이다. KoELECTRA-small은 불만 고객을 찾아내는 재현율(Recall) 지표에서 가장 우수한 0.75를 기록했다. 일부 평범한 고객을 부정으로 오탐지(낮은 Precision)하더라도, 이는 2차 파이프라인인 ‘비즈니스 룰베이스 추출기’를 통해 충분히 교차 검증 및 보완이 가능하므로 하이브리드 구조에 가장 최적화된 성능이다.
둘째, DB 폴링 기반의 준실시간 환경에 필수적인 ‘빠른 응답 속도(Low Latency)’를 보장한다.
본 서비스는 주기적으로 도는 배치가 아니라, 상담 이벤트 발생 시 DB에 적재된 신규 데이터를 가져와 판별해야 하는 폴링 구조이다. 이러한 환경에서는 대기 시간(병목) 없이 즉각적인 AI 추론 결과를 반환하는 것이 가장 중요하다. KoELECTRA-small은 Base 모델 대비 약 3배 빠른 연산 속도와 1/3 수준의 CPU 점유율을 기록하여, 트래픽이 쏟아지는 피크(Peak) 타임에도 지연 없는 안정적인 응답을 제공할 수 있음을 증명했다.
셋째, 제한된 컨테이너 환경(1.0 vCPU, 2GB Memory Limit)에서의 운영 안정성 및 비용 효율성이다.
도커(Docker) 기반의 제한된 자원 할당 테스트 결과, KoELECTRA-small은 컨테이너 한계치(2GB)를 초과하지 않는 선(Peak Memory 1.78GB)에서 Out Of Memory(OOM) 없이 안정적으로 구동됨을 확인했다. 연산 과정에서 일시적인 메모리 점유는 Base 모델과 유사하지만, 처리를 3배 빠르게 끝마치고 자원을 반납하기 때문에 동시 접속자가 몰리는 실시간 피크(Peak) 타임에도 서버가 뻗지 않고 유연하게 버틸 수 있는 최적의 대안이다.
**결론적으로, **이번 감정 분석 모델 선정은 단순히 파라미터가 큰 무거운 모델을 고집하는 대신, ‘비즈니스 목적에 부합하는 불만 고객 포착력(High Recall)’**과 **‘실시간 서비스에 최적화된 빠른 응답성(Low Latency)’의 완벽한 균형점을 찾는 과정이었으며, 그 기준에서 KoELECTRA-small이 가장 합리적이고 뛰어난 아키텍처적 선택이라고 판단하였다.