안녕하세요.
저희 프로젝트는 크게 두 축으로 구성되어 있습니다. 하나는 고객에게 맞춤형 상품을 추천하는 CRM 기능, 다른 하나는 고객의 이탈 징후를 감지하고 대시보드에서 관리할 수 있도록 하는 CDP 기능입니다.
즉, 단순히 “상품을 추천하는 서비스”에서 끝나는 것이 아니라, 고객이 떠나기 전에 위험 신호를 감지하고, 그에 맞는 오퍼를 제안해 실제 이탈을 줄이는 구조를 목표로 기획했습니다.
0. 문제 의식 및 문제 정의
왜 우리는 이탈률에 집중했는가
통신 산업에서 고객 이탈은 단순한 해지 지표가 아니라, 매출과 고객 생애가치, 마케팅 비용, 장기 성장성까지 동시에 흔드는 핵심 경영 지표입니다. 공개 산업 자료에 따르면 통신 업계의 연간 churn은 시장과 지역, 상품 구조에 따라 대략 15~25%, 혹은 일부 자료에서는 **20~50%** 수준으로 제시되며, 이는 다른 산업과 비교해도 높은 편입니다. 예를 들어 CustomerGauge 자료에서는 통신이 높은 churn 산업군으로 언급되고, Tridens의 telecom churn 아티클도 2024년 CustomerGauge를 인용해 연간 20~50% 범위를 제시합니다.
또한 IBM Telco 계열 공개 데이터셋과 최근 churn 연구들을 보면, 통신사의 고객 이탈은 주로 계약 상태, 가격/요금, 서비스 품질, 고객 지원 경험, 사용 패턴, 경쟁 환경과 연결됩니다. 특히 계약 기간과 요금, 서비스 속성, 고객 지원 경험은 churn 예측에서 반복적으로 중요한 feature로 다뤄집니다.
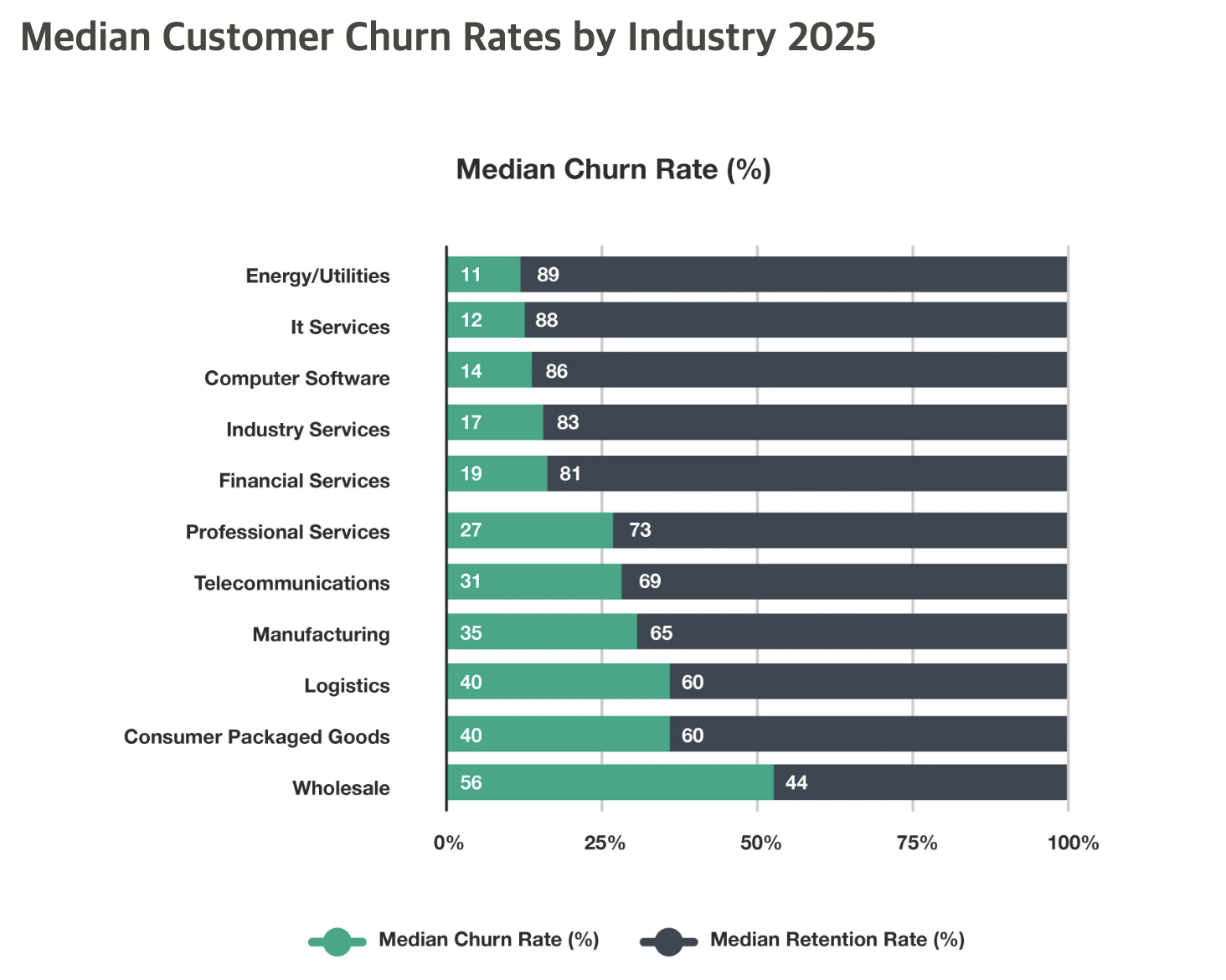
What’s the Average Churn Rate by Industry? 2025 Update
Customer retention and churn prediction in the telecommunication industry: a case study on a Danish university
A predictive analytics approach to improve telecom’s customer retention
###
이탈은 단순히 월 구독료 한 달을 잃는 문제가 아닙니다. 한 고객이 떠난다는 것은 앞으로 회수할 수 있었던 장기 수익, 업셀링 가능성, 충성 고객으로 전환될 잠재력까지 함께 잃는다는 뜻입니다. 실제 산업 자료에서도 churn은 수익성, 유지 비용, 고객 생애가치에 직접적인 영향을 주는 문제로 설명됩니다.
그래서 저희는 고객 이탈을 사후 분석 대상이 아니라, 사전 감지와 개입이 필요한 핵심 문제로 보았습니다. 고객이 떠난 뒤 원인을 해석하는 것이 아니라, 떠나기 전에 위험 신호를 포착하고 CDP에서 관리하며, CRM을 통해 적절한 상품이나 혜택을 제안하는 구조가 더 중요하다고 판단했습니다.
이탈률에 영향을 주는 요소는 다음과 같다고 합니다.
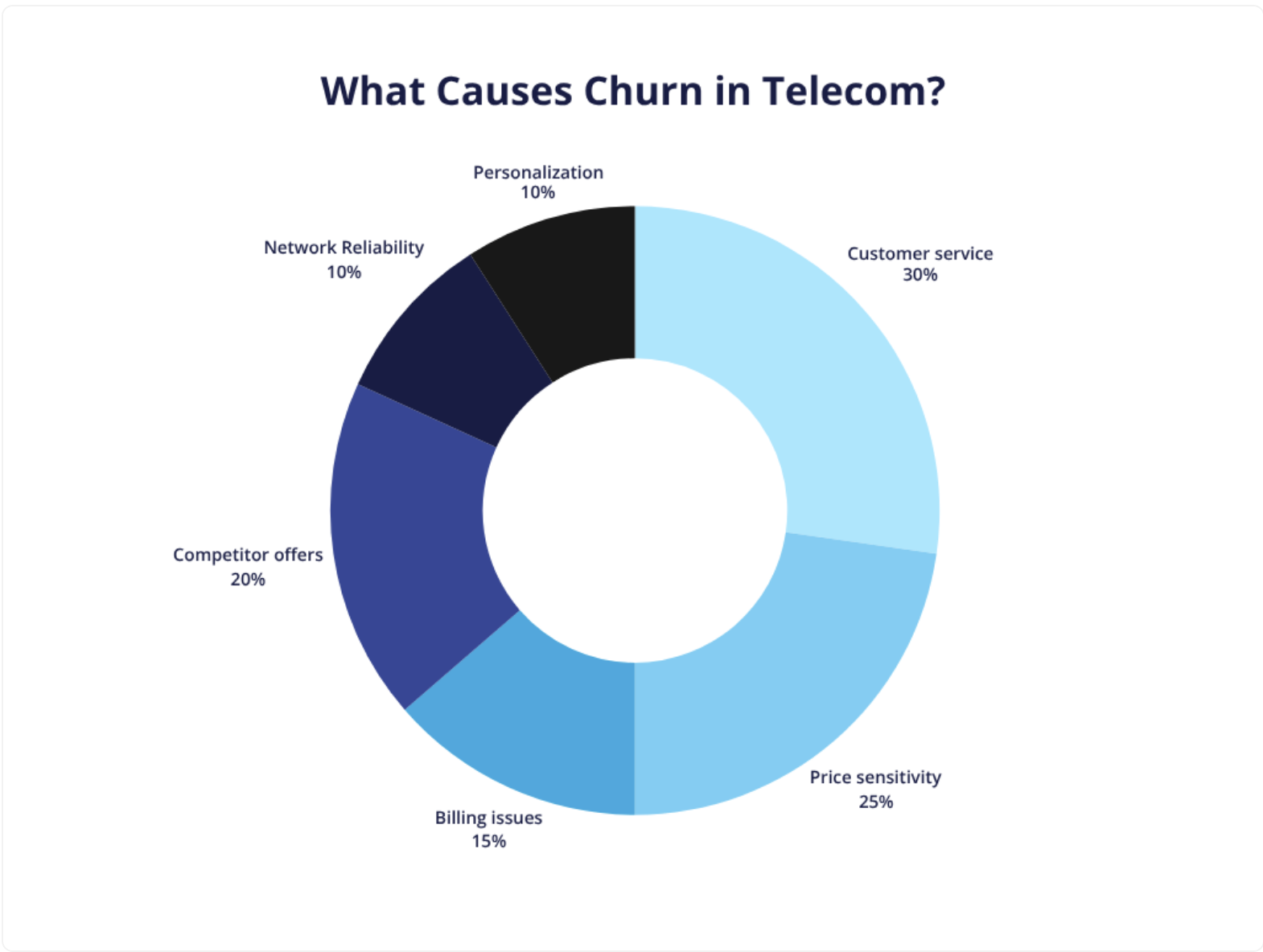
- **가격 민감도(25%):** 고객은 특히 다음과 같은 경우 더 낮은 가격이나 더 나은 가치를 제공하는 경쟁업체로 전환하는 경우가 많습니다. 프로모션 할인.
- 고객 서비스 문제(30%): 긴 대기 시간이나 해결되지 않은 쿼리 등 열악한 지원은 주요 고객 이탈 요인입니다.
- 청구 문제(15%): 복잡하거나 잘못된 청구서는 고객을 실망시켜 취소로 이어집니다. 2023년 Plecto 기사 는 후불 요금제에서 예상치 못한 요금이 부과되어 고객 이탈을 유발한 사례를 강조합니다.
- 경쟁사 오퍼(20%): 무료 스트리밍 구독이나 더 많은 데이터 허용량과 같은 매력적인 프로모션은 고객을 유인합니다.
- 네트워크 안정성(10%): 통화 끊김과 같은 서비스 중단 또는 느린 인터넷충격 유지.
- 개인화 부족(10%): 일반적인 요금제는 개인의 요구를 충족시키지 못해 충성도를 떨어뜨립니다. 개인 맞춤형 서비스를 제공하면 고객 유지율을 크게 높일 수 있습니다.
출처: https://tridenstechnology.com/ko/%ED%86%B5%EC%8B%A0%EC%82%AC-%EC%9D%B4%ED%83%88/
통신사 갈아탈래” 이탈자 급증…SKT ‘점유율 40%’ 무너지나
경쟁이 치열한 통신 환경에서 고객 이탈을 해결하는 것은 선택이 아닌 전략적 우선순위입니다. 저희는 고객의 이탈 징후를 미리 포착하고(CDP), 적절한 오퍼를 던져(CRM) 이 손실을 막는 시스템을 기획하게 되었습니다.
따라서 이탈 가능성이 높은 고객을 미리 식별하고 사전에 개입하는 방식을 중요하게 봤습니다.
따라서, 이탈 예측 분석과 AI를 사용해 통신사가 고객 이탈을 예측하고 방지 할 수 있도록 지원하는 것으로 관리를 할 수 있음을 의미합니다. 2024년 맥킨지 보고서는, AI는 이탈을 15%까지 줄일 수 있다고 합니다.
다음과 같은 프로세스로 연구가 되었습니다.
- 데이터 수집: 통신사는 사용 패턴(데이터 소비, 통화 빈도), 인구 통계(연령, 위치), 청구 내역, 지원 상호 작용 등 포괄적인 데이터를 수집합니다. 이러한 데이터는 CRM과 네트워크 데이터를 통합하여 전체적인 인사이트를 얻을 수 있도록 도와줍니다.
- 분석 모델: 랜덤 포레스트 또는 신경망과 같은 머신 러닝 알고리즘은 데이터를 분석하여 이탈 패턴을 식별합니다. 2024년 연구에 따르면 랜덤 포레스트를 사용한 통신사 이탈 예측 정확도 91.66%를 통해 위험에 처한 고객을 정확하게 타겟팅할 수 있습니다.
- 사전 예방적 개입: 인사이트를 통해 맞춤형 제안(예: 데이터 요금제 할인), 우선 지원 또는 네트워크 업그레이드와 같은 조치를 취할 수 있습니다. 예를 들어, 한 유럽 통신사는 통화 끊김 데이터를 분석하여 영향을 받은 고객에게 무료 데이터를 제공함으로써 2023년 라이프사이클 소프트웨어 문서에 따르면 10%의 고객 이탈을 줄였습니다.
1. 프로젝트 적용의 문제점
실제 해지 데이터가 없는데, 어떻게 이탈률을 측정할 것인가
저희의 주요 기능은 CDP를 통해 이탈 위험 고객을 대시보드에서 관리하고, CRM 기능을 통해 맞춤형 상품을 추천하여 이탈을 방지하는 것입니다. 하지만 구현단계에서 이 문제에 부딪혔습니다.
실제 해지 데이터(label)가 없는데, 어떻게 유의미한 churn 모델을 만들 수 있을까?
즉, 현재는 누가 실제로 타 통신사로 번호이동했는지, 누가 실제로 요금제를 해지했는지에 대한 정답 데이터가 아직 축적되어 있지 않습니다. 이 상황에서 바로 Random Forest나 XGBoost 같은 모델을 학습시키는 것은 기술적으로도 무리가 있고, 설명 측면에서도 설득력이 약하다고 판단했습니다.
그래서 저희는 방향을 바꾸었습니다. 핵심은 **“ML을 포기하는 것”이 아니라, “ML이 가능한 구조를 먼저 설계하는 것”**이었습니다.
즉, 지금 단계에서는 연구와 공개 데이터셋에서 중요하게 제시된 요인들을 바탕으로 Rule-based churn risk scoring을 먼저 설계하고, 동시에 향후 실제 해지 데이터가 쌓였을 때 이를 그대로 학습 데이터셋으로 전환할 수 있도록 feature store와 labeling 구조를 함께 설계하는 방향으로 접근했습니다. 최근 churn prediction 연구들도 공통적으로 전처리 → feature selection → 예측 모델 → 해석 및 활용의 흐름을 강조하며, 어떤 feature를 어떻게 설계하는지가 성능과 설명 가능성 모두에 중요하다고 봅니다
https://pmc.ncbi.nlm.nih.gov/articles/PMC12426120/?utm_source=chatgpt.com
2. 이탈률 설계 철학
ML-Ready Feature Engineering
저희는 단순히 감으로 규칙을 정하지 않았습니다. 통신사 churn 연구와 IBM Telco 계열 공개 데이터셋을 참고하여, 현재는 Rule 기반으로 운영하되 향후 ML로 자연스럽게 확장할 수 있는 구조를 목표로 설계했습니다.
통신사 churn prediction은 보통 다음과 같은 단계로 발전한다고 보았습니다.
1단계. Rule 기반 CRM Scoring
도메인 지식을 바탕으로 위험 고객을 식별하는 단계입니다.
2단계. Logistic / Score 기반 모델
선형 결합 구조를 바탕으로 가중치를 최적화하는 단계입니다.
3단계. ML 기반 예측 모델
Random Forest, XGBoost 같은 모델로 비선형 패턴과 feature interaction까지 포착하는 단계입니다. 최근 2025년 telecom churn predictive analytics 연구도 여러 ML 알고리즘을 적용해 churn 예측 성능과 해석 가능성을 비교하고 있습니다.
현재 저희는 1단계에 있지만, 설계 자체는 2단계와 3단계로 확장 가능하도록 구성했습니다. 즉, 지금은 Rule 기반이지만, 구조적으로는 ML을 위한 준비가 되어 있는 상태를 만드는 것이 목표였습니다.
3. 근거 있는 설계
연구 결과와 IBM Dataset을 왜 참고 했는가?
통신사 churn 연구를 종합해 보면, 변수 이름은 조금씩 달라도 반복적으로 등장하는 핵심 변수가 있습니다. 대표적으로 계약 기간, 가격/요금, 서비스 품질, 고객 만족/상담 경험, 전환 비용, 사용 패턴이 주요 요인으로 제시됩니다. 2023년 Danish telecom 사례 연구는 service quality, customer satisfaction, subscription plan upgrades, network coverage 등을 중요한 churn 요소로 설명하고 있습니다
또한 IBM Telco Customer Churn 데이터셋은 churn prediction 입문과 비교 실험에서 가장 널리 쓰이는 공개 데이터 중 하나로, 약 7,043명의 고객 데이터와 churn 타깃을 포함하고 있습니다. 이 데이터셋은 고객 계약 정보, 월 요금, 서비스 가입 정보, 결제 방식, demographic 정보 등을 함께 제공하며, churn 예측에서 어떤 종류의 feature를 준비해야 하는지에 대한 좋은 기준점이 됩니다.
즉, 저희는 단순히 “이 feature가 중요할 것 같다”라고 추측한 것이 아니라, 기존 연구와 공개 데이터셋에서 반복적으로 중요하게 검증된 범주를 현재 서비스 구조에 맞게 재해석한 것입니다.
##
4. 우리 프로젝트에서 정의한 churn feature
우리 Dataset을 기반으로 다섯가지 범주로 나눠 feature를 설계하였습니다.
4-1. 계약 기반 feature
첫 번째는 계약 자체와 관련된 feature입니다.
연구에서 가장 안정적으로 반복되는 churn 변수는 contract, tenure 계열입니다. 계약 종료가 가까워질수록 전환 장벽이 낮아지고, 가입 초기 고객은 아직 서비스에 충분히 정착하지 않았기 때문에 churn 가능성이 높아질 수 있습니다. 이는 IBM Telco 계열 데이터셋과 기존 churn 연구 모두에서 공통적으로 확인됩니다.
그래서 저희는 다음 두 가지를 현재 운영 점수에 직접 반영하기로 했습니다.
- 약정 종료까지 남은 기간이 3개월 이내인지
- 가입 초기 고객인지, 예를 들어 가입 1개월 이내인지
이 두 변수는 설명 가능성이 높습니다. “왜 이 고객이 이탈 위험이 높은가?”를 물었을 때, 약정 종료 임박과 가입 초기라는 상태는 누구나 이해할 수 있고, 실제 retention action과도 연결하기 쉽습니다.
4-2. 가격 대비 사용량 feature
두 번째는 고객이 내고 있는 요금 대비 실제로 얼마나 쓰고 있는가입니다. 이건 단순히 월 요금이 비싸냐의 문제가 아니라, 고객이 체감하는 서비스 가치와 지불 비용이 얼마나 일치하는가의 문제입니다. Danish 사례 연구와 최근 churn 연구들은 서비스 가치, subscription plan, 만족도와 churn 간 관계를 강조합니다
예를 들어 제공 데이터 대비 실제 사용량이 지나치게 낮다면, 고객은 “내가 굳이 이 요금제를 유지할 이유가 있나?”라고 느낄 수 있습니다. 그래서 저희는 요금제 대비 데이터 사용량이 30% 이하인 경우를 overpay risk로 보고, churn risk를 높이는 요인으로 반영했습니다.
이 feature의 장점은 분명합니다. 단순히 “비싼 요금제를 쓴다”가 아니라, **“고객이 현재 서비스 가격을 정당화하지 못할 가능성”**을 보는 것이기 때문에 훨씬 설득력 있습니다.
4-3. 고객 불만 feature
세 번째는 고객센터와 불만 경험입니다. 고객 불만은 churn 연구에서 매우 자주 등장하는 축입니다. 서비스 품질과 만족도는 retention의 핵심 요인이고, 상담 경험은 그 만족도를 가장 직접적으로 드러내는 접점 중 하나입니다. Danish 연구 역시 customer satisfaction과 service quality를 주요 churn 요인으로 다룹니다
우리는 이 영역을 단순 상담 건수로만 보지 않고, 조금 더 구조화해서 가져가려고 한다.
- 불만 상담 횟수
- 상담 만족도 평균
- 상담 텍스트에서 추출한 해지 관련 비즈니스 키워드
- 감정 분석을 통한 부정 상담 횟수
저희는 이 영역을 단순 상담 건수로만 보지 않고, 조금 더 구조화해 가져가고자 했습니다.
- 불만 상담 횟수
- 상담 만족도 평균
- 상담 텍스트에서 추출한 해지 관련 비즈니스 키워드
- 감정 분석을 통한 부정 상담 횟수
즉, 상담 유입 API로 들어온 데이터를 FastAPI에서 분석하고, 거기서 “해지”, “속도 문제”, “요금 불만”, “품질 불만” 같은 키워드를 추출해 정형 feature로 바꾸는 구조입니다.
이 접근의 장점은 분명합니다. 상담 텍스트를 단순히 저장하는 데서 끝나지 않고, 실제 모델이나 점수 계산에 활용할 수 있는 structured feature로 전환할 수 있기 때문입니다.
4-4. 행동 기반 feature
네 번째는 가장 직접적인 영역입니다. 저희는 churn 의도를 가장 강하게 드러내는 신호가 행동 로그라고 보았습니다.
예를 들어 다음과 같은 행동은 매우 직관적입니다.
- 요금제 탐색
- 요금제 비교
- 요금제 변경 시도
- 위약금 조회
특히 위약금 조회는 고객이 단순히 정보를 본 수준을 넘어, “지금 계약을 끊었을 때 비용이 얼마나 드는가”를 구체적으로 따져보는 행동이기 때문에 더 강한 intent signal로 볼 수 있습니다. 최근 churn prediction 및 retention 관련 연구도 예측 결과를 행동 개입으로 연결하려면 이런 직접적인 행동 신호를 잘 포착하는 것이 중요하다고 봅니다.
또한 최근 3개월 내 연체 횟수나 미납 발생 여부도 함께 반영할 수 있습니다. 이건 단순 결제 정보가 아니라, 서비스 유지 의지와 지불 상태를 동시에 보여주는 신호이기 때문입니다.
(4-5. 사용 패턴 feature) -> 아직 확정 아님
다섯 번째는 usage trend입니다. 고객이 최근 3개월 동안 서비스를 어떻게 쓰고 있는지, 사용량이 유지되는지 줄어드는지를 보면 서비스 disengagement를 추적할 수 있습니다. usage 변화는 churn 연구에서 꾸준히 중요한 feature 그룹으로 다뤄집니다.
그래서 저희는 usage_monthly를 기반으로 최근 3개월 usage snapshot을 만들고,
직전월 대비 감소율이나 최근 3개월 평균 사용률 같은 파생 변수를 만들도록 설계했습니다.
즉, 단순 사용량 원본이 아니라 감소 추세 자체를 feature화하는 방향입니다.
5. 현재의 churn score는 확률이 아니라 위험 점수다
여기서 가장 중요한 구분이 하나 있습니다. 현재 계산하는 값은 실제 churn probability가 아닙니다. 이건 Rule 기반 risk score, 즉 위험 신호를 누적한 점수입니다.
따라서 80점을 받았다고 해서 “80% 확률로 해지한다”는 뜻은 아닙니다. 대신 저희는 다음처럼 해석합니다.
- 0~30: Low Risk
- 30~70: Medium Risk
- 70~100: High Risk
즉, 지금의 점수는 실제 확률이 아니라 운영 등급을 위한 상대적 위험도입니다. 현재는 실제 라벨이 없기 때문에 확률처럼 말하는 것보다, **“이탈과 관련된 강한 신호를 점수화했다”**라고 설명하는 것이 훨씬 정직하고 설득력 있다고 판단했습니다.
6. 가중치는 어떻게 정하는가 ?
가중치는 세 가지 근거를 바탕으로 정했습니다.
첫째, 연구 기반 중요도입니다. 계약, tenure, 서비스 품질, 고객 만족, 사용 패턴 등은 문헌에서 반복적으로 등장하는 핵심 축입니다.
둘째, CRM 관점의 signal strength입니다. 예를 들어 위약금 조회는 해지 의도와 매우 가깝고, 단순 사용량 감소는 그보다 간접적입니다. 즉 같은 feature라도 실제 churn intent와 얼마나 가까운가에 따라 가중치를 다르게 부여할 수 있습니다
셋째, 향후 logistic scoring 구조를 염두에 둔 선형 결합 형태입니다. 지금은 사람이 정한 비즈니스 가중치지만, 구조 자체는 나중에 logistic regression으로 자연스럽게 바뀔 수 있도록 선형 결합 형태를 유지하는 것입니다.
현재 단계의 개념식은 다음과 같습니다.
risk_score = Σ(feature_value × business_weight)
예를 들면 다음과 같은 형태입니다.
risk_score =
35 * penalty_check
+ 25 * contract_expiring
+ 20 * negative_support
+ 15 * plan_compare
+ 10 * usage_drop
이때 가중치는 연구 + 도메인 해석 + signal strength를 기준으로 사람이 정한 값입니다. 이 구조는 logistic regression의 선형 결합 구조와 유사하며, 향후 실제 churn label이 축적되면 동일한 feature store를 기반으로 logistic regression이나 tree-based model을 학습시켜 데이터 기반 확률 예측 구조로 전환할 수 있습니다.
7. 향후 feature store 구축
현재 운영 점수에는 계약, 행동, 불만, 사용량처럼 직접적인 churn signal만 반영하는 것이 맞다고 보았습니다. 하지만 feature store에는 더 넓은 범위를 함께 저장해두는 것이 필요합니다.
이유는 간단합니다. 지금 우리가 중요하다고 생각한 feature만이 미래에도 진짜 중요한 변수라는 보장이 없기 때문입니다. 실제 문헌고찰에서는 age, gender, satisfaction, switching costs, service quality 등도 반복적으로 중요한 결정요인으로 등장합니다. 그래서 저희는 운영 단계에서는 보수적으로 가되, 학습 확장을 위해 feature는 넓게 저장하는 전략을 택했습니다.
현재 점수에 직접 넣는 feature
- 약정 종료 임박
- 가입 초기
- 위약금 조회
- 요금제 비교/변경 시도
- 부정 상담 / 낮은 상담 만족도
- 최근 사용량 급감
- 가격 대비 사용량 낮음
- 최근 연체 또는 미납 발생 여부
지금은 저장만 하고, 추후 ML에서 검증할 feature
- 나이대
- 성별
- 멤버십 등급
- 가족 결합 여부
- 지역
- 페르소나 / 지수 스냅샷
- 디바이스 / 가구 관련 파생 지표
이 구조의 장점은 분명합니다. 운영 점수는 설명 가능성과 직접성에 집중하고, feature store는 미래 확장성과 학습 가능성에 집중할 수 있기 때문입니다.
-
8. 그래서 feature store는 어떻게 설계하는가
저희는 고객-시점 단위 snapshot 구조를 기준으로 갑니다.
예를 들어 churn_feature_snapshot 같은 테이블을 둘 수 있습니다.
대표 컬럼은 아래와 같습니다.
snapshot_datemember_idtenure_monthsdays_to_contract_endis_new_customer_30dmonthly_feeusage_ratio_3mnegative_support_count_30davg_support_rating_90dtermination_keyword_count_30dpenalty_check_count_7dplan_compare_count_7dplan_change_click_count_7dusage_drop_rate_3mage_groupgenderfamily_group_nummembership_gradepersona_typeraw_rule_scorerule_tier
이 테이블의 역할은 단순 저장이 아닙니다. 이건 나중에 training mart가 됩니다. 즉, 지금은 운영용 snapshot이지만, 라벨이 붙는 순간 학습 데이터셋의 feature 영역으로 그대로 전환될 수 있는 구조입니다.
9. 라벨은 어떻게 붙이는가
ML로 가기 위해 가장 중요한 것은 결국 라벨입니다. 저희는 라벨을 “고객이 언젠가 해지했다”가 아니라, 시점 기준으로 정의된 churn event로 봐야 한다고 판단했습니다.
예를 들어 churn_label 테이블은 다음과 같은 구조를 가질 수 있습니다.
member_idlabel_datelabel_windowis_churnchurn_type(PLAN_CANCEL,PORT_OUT)observed_at
그리고 라벨 기준은 다음처럼 가져갈 수 있습니다.
snapshot_date이후 30일 내 실제 해지가 발생하면is_churn = 1- 그렇지 않으면
0
이렇게 해야 시점 기반 supervised learning dataset이 됩니다. 현재 시점의 feature로 미래 30일 내 churn을 맞히는 구조가 되어야 운영적으로도 의미가 있습니다.
10. 배치와 실시간을 함께 보는 하이브리드 구조
이번 설계에서 꼭 강조하고 싶은 부분은, churn 시스템이 무조건 배치만으로 끝나지 않는다는 점입니다.
저희는 기본적으로 하루 1회 혹은 주기적으로 feature를 집계하고, churn_score_snapshot에 저장하는 배치 기반 구조를 생각하고 있습니다.
하지만 churn은 어느 순간 갑자기 강한 의도로 표면화되기도 합니다.
예를 들어, 어제까지만 해도 medium risk였던 고객이 오늘 앱에서 위약금 조회를 했다면, 이건 다음 배치를 기다릴 일이 아닙니다. 그 순간 바로 실시간 위험도 상승이 필요합니다.
즉 설계는 다음과 같습니다.
- 기본 점수는 배치로 계산
- 강한 intent signal은 이벤트 발생 시 실시간 반영
이런 Batch + Real-time hybrid churn detection 구조는 기술적으로도 자연스럽고, 현업 관점에서도 훨씬 설득력 있습니다.
11. 향후 ML 확장 로드맵
이 구조는 세 단계로 정리할 수 있습니다.
1단계. 지금
Rule 기반 scoring으로 churn risk를 계산하고, 운영 가능한 위험 등급 체계를 만듭니다.
2단계. 데이터 축적
실제 해지, 번호이동, 요금제 해지 등의 이벤트를 라벨로 축적합니다. 동시에 snapshot feature를 계속 쌓습니다.
3단계. 학습
같은 feature store를 training set으로 전환하고, baseline으로는 Logistic Regression을 먼저 적용합니다. 이후 비선형 관계나 feature interaction을 더 잘 포착하기 위해 Random Forest, XGBoost 같은 모델로 확장합니다. 최근 연구들 역시 churn 예측에서 이런 모델들을 널리 비교하고 있습니다.
그리고 서빙 구조는 크게 바꿀 필요가 없습니다.
지금은 RULE 타입의 점수를 저장하고, 나중에는 LOGIT, XGBOOST 점수도 같은 구조에 함께 담으면 됩니다.
예를 들면:
score_type = RULE | LOGIT | XGBOOSTscore_valuetop_factorsJSON
이렇게 가면 시스템은 점진적으로 고도화되지만, 운영 계층은 깨지지 않습니다.
12. 정리하며
이번 프로젝트의 핵심은 단순히 “이탈률을 계산했다”가 아닙니다. 진짜 핵심은 라벨이 없는 상황에서도 통신사 churn 시스템을 어디서부터 어떻게 설계해야 하는지에 대한 구조를 만들었다는 것입니다.
저희는 연구에서 반복적으로 중요하게 제시되는 계약, 요금, 사용량, 고객 불만, 서비스 품질, 전환 비용, 행동 로그를 바탕으로 현재 운영 가능한 Rule 기반 churn score를 설계했습니다. 동시에 지금 중요해 보이는 변수만 사용하는 데서 멈추지 않고, demographic·contract·billing·support·event-log 계열의 다양한 후보 feature를 함께 적재하는 feature store 구조를 마련했습니다. 그리고 실제 해지/번호이동 라벨이 확보되면 동일한 구조를 training set으로 전환해 Logistic Regression, Random Forest, XGBoost로 확장할 수 있도록 설계했습니다.
결국 이번 설계는 **“지금 당장 운영 가능한 위험 점수”**와 **“나중에 데이터 기반 예측 모델로 확장 가능한 구조”**를 동시에 잡는 데 초점을 두고 있습니다.
참고한 자료
- Why Telecom Customers Churn and How to Measure it?
- 이탈률 분석
- Omari et al., A predictive analytics approach to improve telecom’s customer retention (2025, PMC)
- Saleh & Saha, Customer retention and churn prediction in the telecommunication industry: a case study on a Danish university (2023, PMC)
- Kaggle / IBM Telco Customer Churn 공개 설명 및 관련 공개 리포지토리
- Tridens, Why Telecom Customers Churn and How to Measure It? 산업 참고 자료.
- CustomerGauge, 산업별 churn benchmark 참고.
- 현재 프로젝트 DB 스키마