1. 문제 발생
최근 변경된 On-Demand 워크플로우를 구현하며 운영환경에서 배포 이후, 실행 과정(KST 기준: 2026년 3월 14일 11시 2분 15.769초)에서 예상하지 못한 장애를 직면했다.
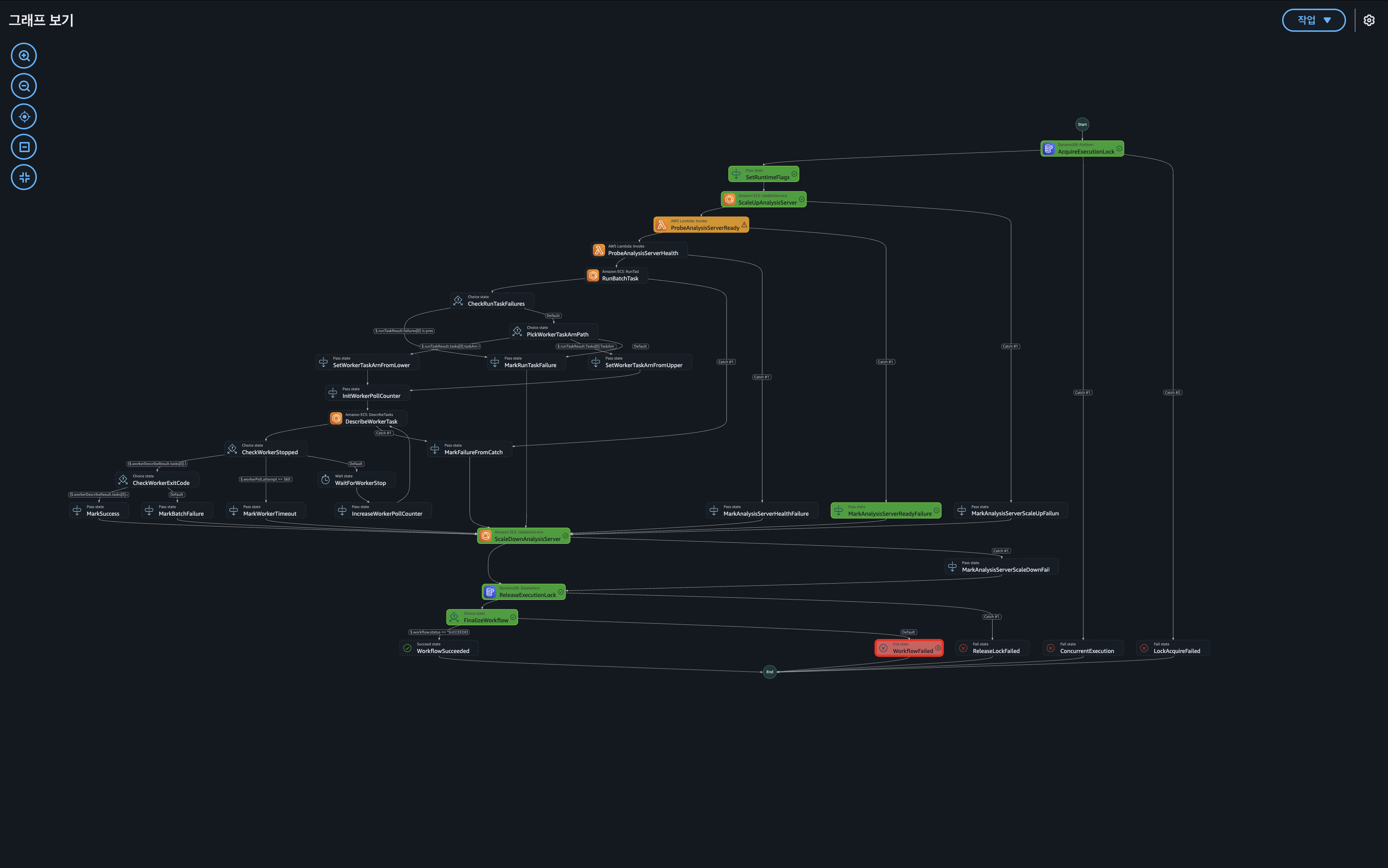
해당 워크플로우는 EventBridge에서 시작되어 Step Functions, Lambda(Readiness Probe), ECS RunTask, DynamoDB Lock으로 이어지는 구조를 가진다. 워크플로우의 핵심 목적은 본격적인 배치 작업 실행 전에 대상 시스템인 analysis-server가 실제로 준비되었는지 /ready 및 /health 엔드포인트를 통해 확인하고, 검증이 완료된 후 후속 작업을 수행하는 것이다.
실패한 내역은 아래와 같다.
- 상태 머신: AnalysisBatchWorkflow
- 실행 시각: 2026-03-14 11:02:15 KST
- 종료 시각: 2026-03-14 11:06:56 KST
- 최종 상태: FAILED
2. 가설 세우기
장애가 발생한 워크플로우는 AWS CDK in Java로 작성하였으며 OnDemandWorkflowStack.java에 정의되어 있다. 특히, Readiness Probe 역할을 수행하는 Lamda 함수는 어플리케이션 내부 로직이 아닌, CDK를 통해 주입받은 VPC, Subnet, Security Group(SG) 설정에 의해 네트워크 통신 경로가 결정된다.

장애 발생 지점은 파악을 했으므로 해당 단계에서 발생할 수 있는 4가지 가설을 세웠다.
- analysis-server의 기동이 지연되어 /ready 응답에서의 timeout이 발생했을 가능성.
- 응답은 정상적으로 수신했으나 릴리스 태그나 계약 조건이 불일치할 가능성
- Lamda가 analysis-server로의 네트워크 연결 자체를 못하는 가능성
- AWS CDK 의 코드 내용과 실제 AWS 인프라 환경의 배포 상태가 다를 가능성
3. 가설 검증 및 원인 추적
1) Step Functions에서 실패 지점 파악
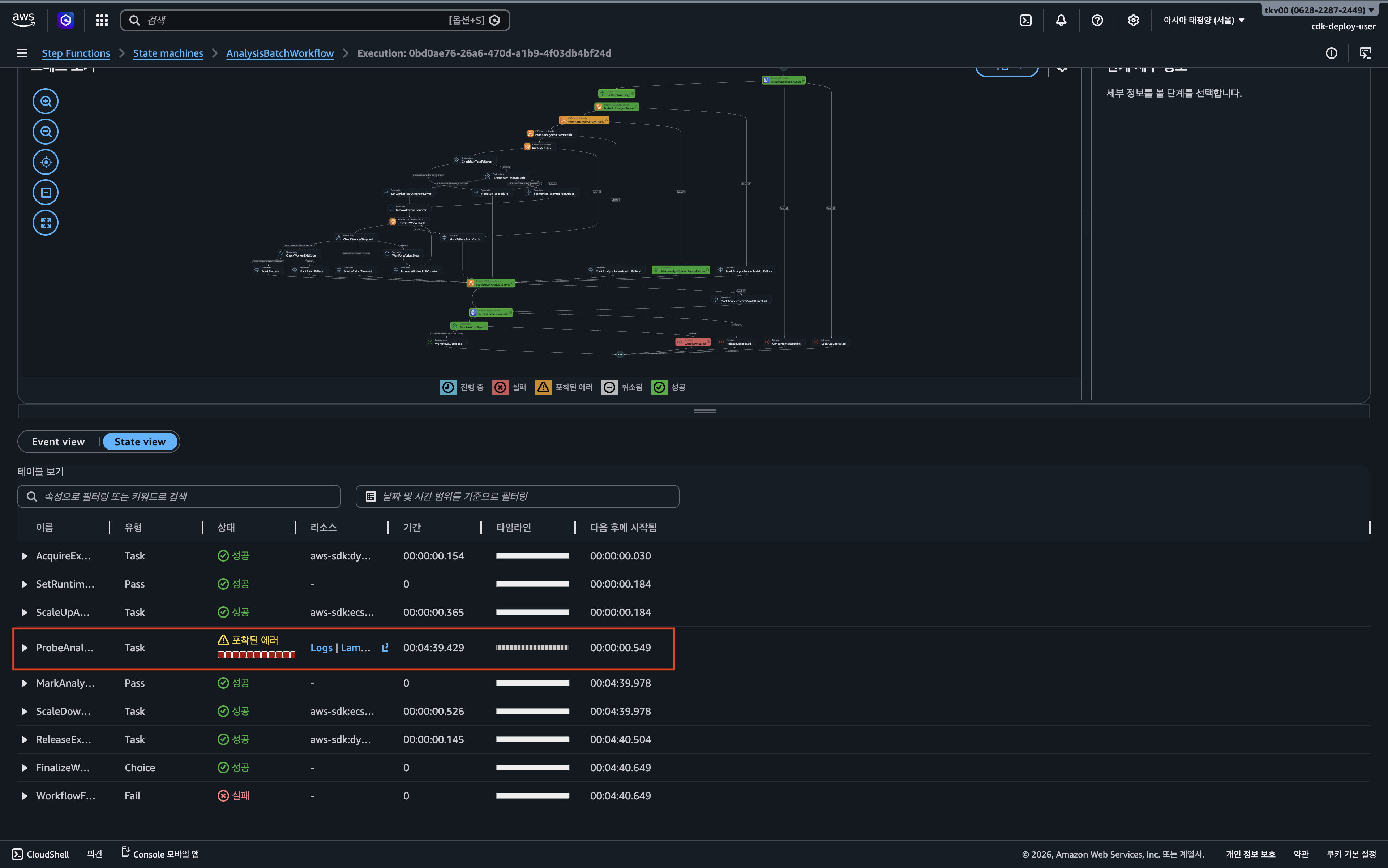
가장 먼저 AWS console - Step Functions 에서 실행 이력을 분석하여 실패 지점을 좁혔다. 전체 워크 플로우 중 배치 실행 단계가 아니라 준비 상태를 확인하는 ProbeAnalysisServerReady 단계에서 에러가 발생했음을 확인했다.
해당 단계에서는probeIntervalSeconds와 probeMaxAttempts 설정에 따라 지정된 횟수만큼 재시도를 수행하도록 설계되어 있었으며, 설정된 재시도를 모두 소진한 후 최종 실패로 처리되고 있다.
2) Lamda 로그에서 timeout 패턴 확인
다음으로 정확한 실패 사유를 분석하기 위해 Readiness Probe Lamda 실행 로그를 분석했다. Lamda의 Python-urllib를 이용하여 대상 서버에 GET 요청을 보내고 HTTP 상태 코드 및 Payload의 정합성을 검증하도록 작성했다.

로그 분석 결과, HTTP 500이나 404와 같은 서버 에러나 릴리즈 태그 불일치 에러는 발견되지 않았다. 다만 네트워크 레벨에서의 urlopen timeout 예외가 5초 간격으로 누적되어 발생하고 있었다. 이는 Lamdbda가 대상 서버로 연결조차 하지 못하는 상태임을 의한다. 이를 근거로 가설2는 배제했다.
실제로 오류가 발생하는 시점의 코드는 아래와 같다.

3) Analysis ECS Service Task 상태 확인
이어서, 타겟 서버인 analysis-server 자체의 업-다운 여부 확인을 위해 ECS Task 상태를 확인했다. 확인 결과 ECS Task는 Step Functions가 실행하기 이전부터 정상적으로 기동되어 RUNNING 상태임을 확인했다.

따라서, Analysis Server task가 늦게 기동되어 timeout이 발생했을 것이라는 첫 번째 가설은 아님을 입증했다.
3) Security Group 규칙 확인
네트워크 통신 간 보안 문제 확인을 위해 각각 할당된 Security Group의 규칙을 확인했다. 타겟 서버인 Analysis-Server의 인바운드 규칙은 올바르게 설정되어 접근을 허용하고 있었다. 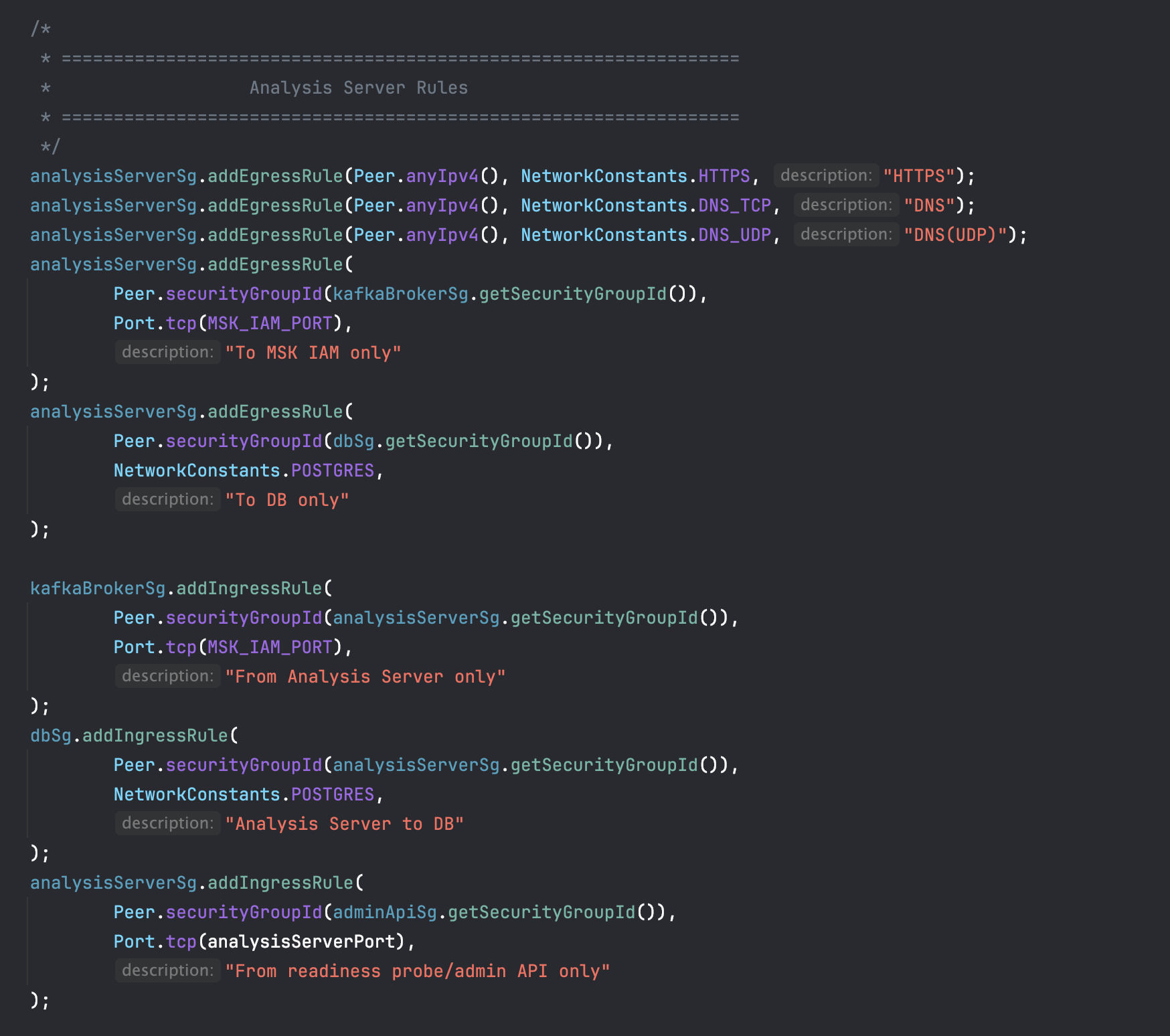
하지만, Security Group 간 통신이 가능하려면 인바운드 뿐만 아니라 출발지의 아웃바운드 규칙 역시 설정되어있어야 한다. AWS CDK 코드상으로 Probe Lambda가 속한 AnalysisServerSg의 8000번 포트로 향하는 Egress 규칙이 명확히 정의되어 있었다. 하지만 실제 AWS 환경에 프로비저닝된 리소스를 확인해 보니 해당 아웃바운드 규칙이 누락되어 있었다. 이로 인해 TCP 3-Way Handshake조차 이루어지지 않아 타임아웃이 발생했던 것이다.
4) CloudFormation 스택 상태 확인
코드에는 존재하는 규칙이 실제 인프라에 반영되지 않은 이유를 찾기 위해 CloudFormation의 스택 배포 상태를 확인했다. 확인 결과, 워크플로우 로직을 담은 OnDemandWorkflowStack은 정상적으로 배포(UPDATE_COMPLETE)되었으나, 네트워크 규칙 변경을 포함하는 NetworkStack은 모종의 이유로 롤백(UPDATE_ROLLBACK_COMPLETE)된 상태였다.
결과적으로 Readiness Probe 기능 자체는 추가되었으나, 해당 기능이 의존하는 네트워크 계층의 변경 사항이 반영되지 않아 코드와 실제 인프라 간의 드리프트(Drift)가 발생한 것이 장애의 근본 원인이었다.
4. 해결 조치 및 회고
1) 해결 방법
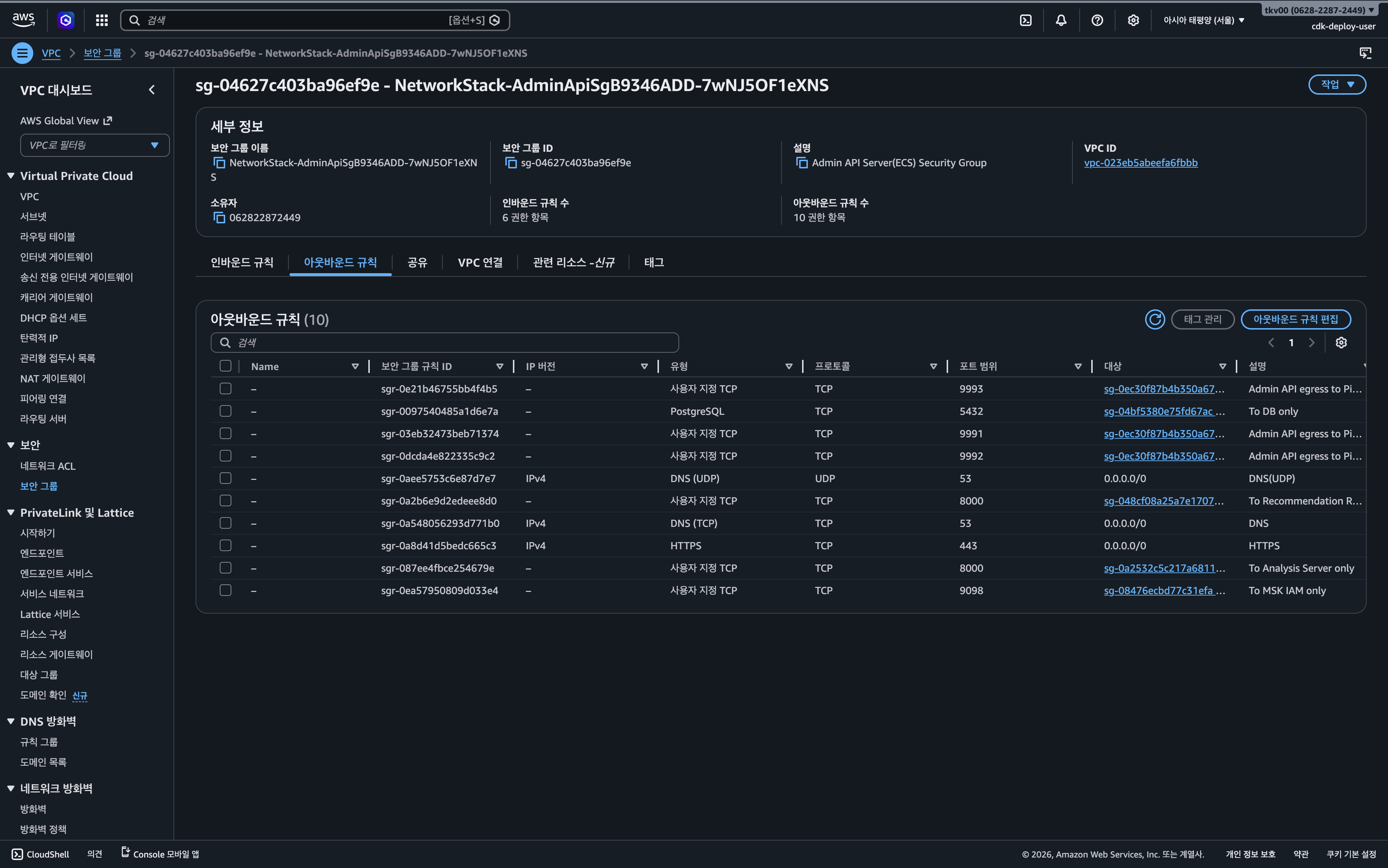
운영 환경의 즉각적인 정상화를 위해, AWS 콘솔을 통해 AdminApiSg에 누락되었던 TCP 8000 아웃바운드 규칙을 수동으로 추가하는 임시 대응을 진행했다.
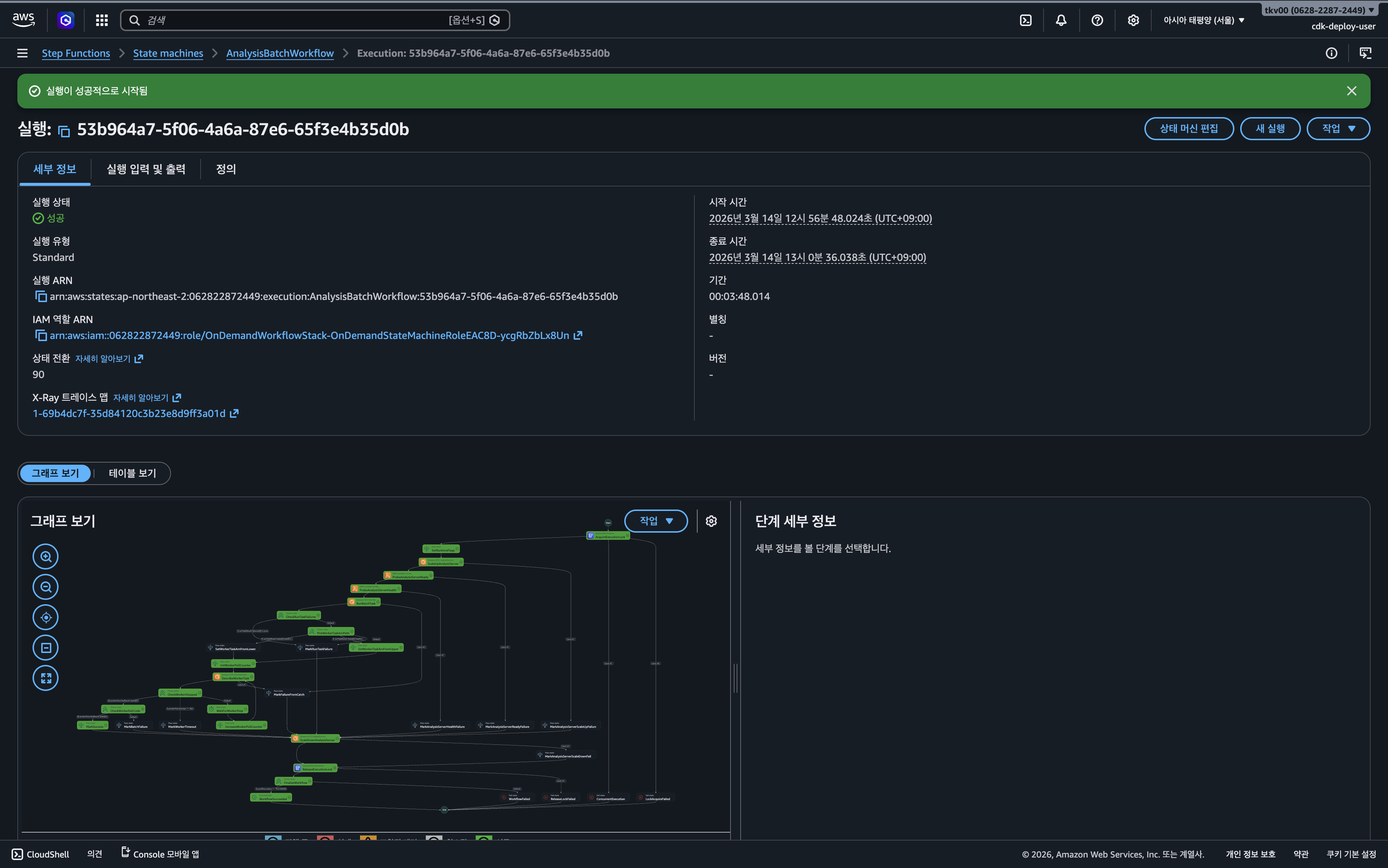
조치 직후 Readiness Probe가 정상적으로 엔드포인트에 도달하며 워크플로우가 복구되었다.
2) 회고
Security Group 설정 검토
이번 장애를 겪으면서 느낀 점은, Security Group을 설정할 때 목적지의 인바운드(Ingress)뿐만 아니라 출발지의 아웃바운드(Egress) 규칙도 반드시 함께 챙겨야 한다는 기본기이다.
사실 CDK로 인프라 코드를 작성하고 리뷰할 때는 아웃바운드가 누락되었다는 걸 전혀 눈치채지 못했다. 사람이 눈으로만 코드를 쫓다 보면 이런 사소한 실수는 정말 놓치기 쉽고, 이 작은 실수가 실제 운영 환경에서는 전체 워크플로우를 멈추게 만드는 큰 위험으로 돌아온다.
‘테스트 코드가 중요하다’는 건 늘 머리로는 알고 있었지만, 애플리케이션 코드가 아닌 인프라(IaC) 영역에서도 그 중요성을 다시금 실감한 케이스였다. 아래와 같은 교훈을 마음 속에 새겼다.
사람의 코드를 믿지 말고 테스트 코드를 통해 시스템을 믿자
시스템 실행 중 ≠ 시스템 동작
장애 발생 직후 ECS 클러스터 콘솔을 열어봤을 때, Analysis Server는 아무 이상 없이 초록색 ‘RUNNING’ 상태를 띄우고 있었다. 그걸 보고 당연히 분석 서버 쪽은 문제가 없다고 단정 지어버렸고, 배치 서버의 로그만 주구장창 파헤쳤다. 트러블슈팅의 방향이 처음부터 엇나갔었다.
하지만 결국 진짜 원인은 네트워크 단의 방화벽(SG) 문제였다. 즉, 컨테이너 프로세스가 잘 떠서 ‘실행 중’이라는 사실이, 곧 그 서비스가 외부 요청을 정상적으로 받고 ‘동작’한다는 것을 의미하지는 않는다는 걸 확실히 배웠다.
앞으로는 단순히 프로세스 생존 여부만 볼 것이 아니라, 실제로 네트워크 통신이 가능한지 실질적인 상태를 모니터링해야한다. 그리고 이렇게 서비스가 실질적인 정상 동작을 하지 못할 때, 개발자가 지체 없이 인지할 수 있도록 알림(Alert) 체계를 촘촘하게 보완할 예정이다.