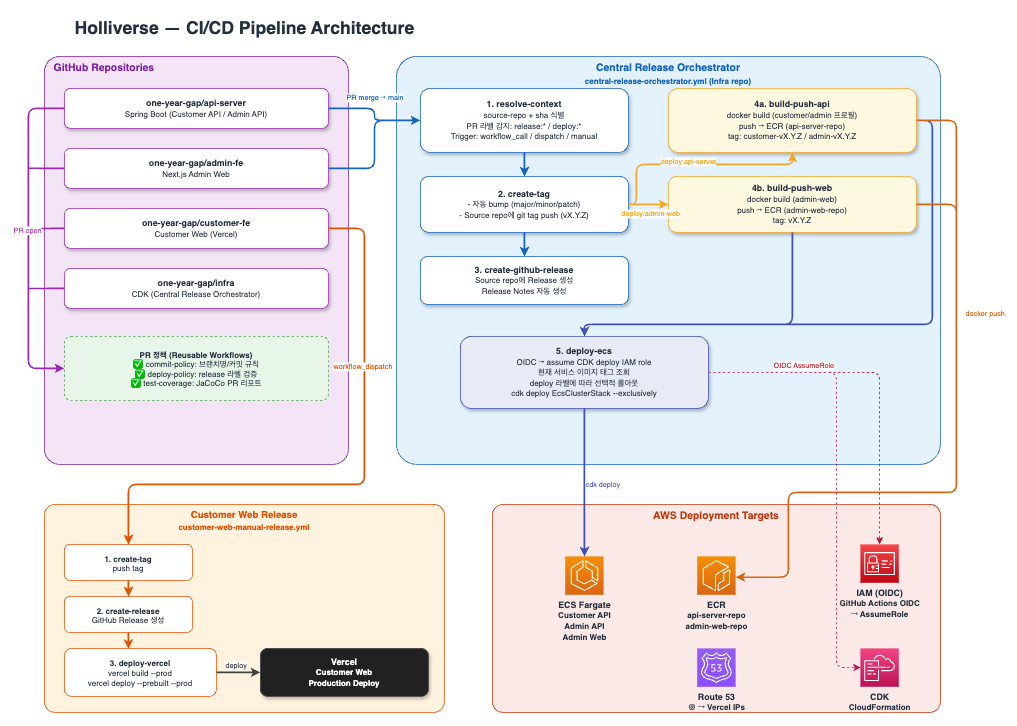
1. 개요 - 중앙 Infra Repository 하나로 배포 통합
이번에 인프라를 설계하면서 Network Architecture 다음으로 가장 먼저 손댄 영역은 CI/CD/CT였다. 이유는 단순했다. 개발을 빠르게 시작하고, MVP를 만들고, 실제 E2E 테스트를 반복하려면 결국 가장 먼저 필요한 것은 지속적으로 배포할 수 있는 구조였기 때문이다.
CI/CD/CT 워크 플로우를 구성하며, 1가지의 큰 컨셉을 가져가기로 결정했다.
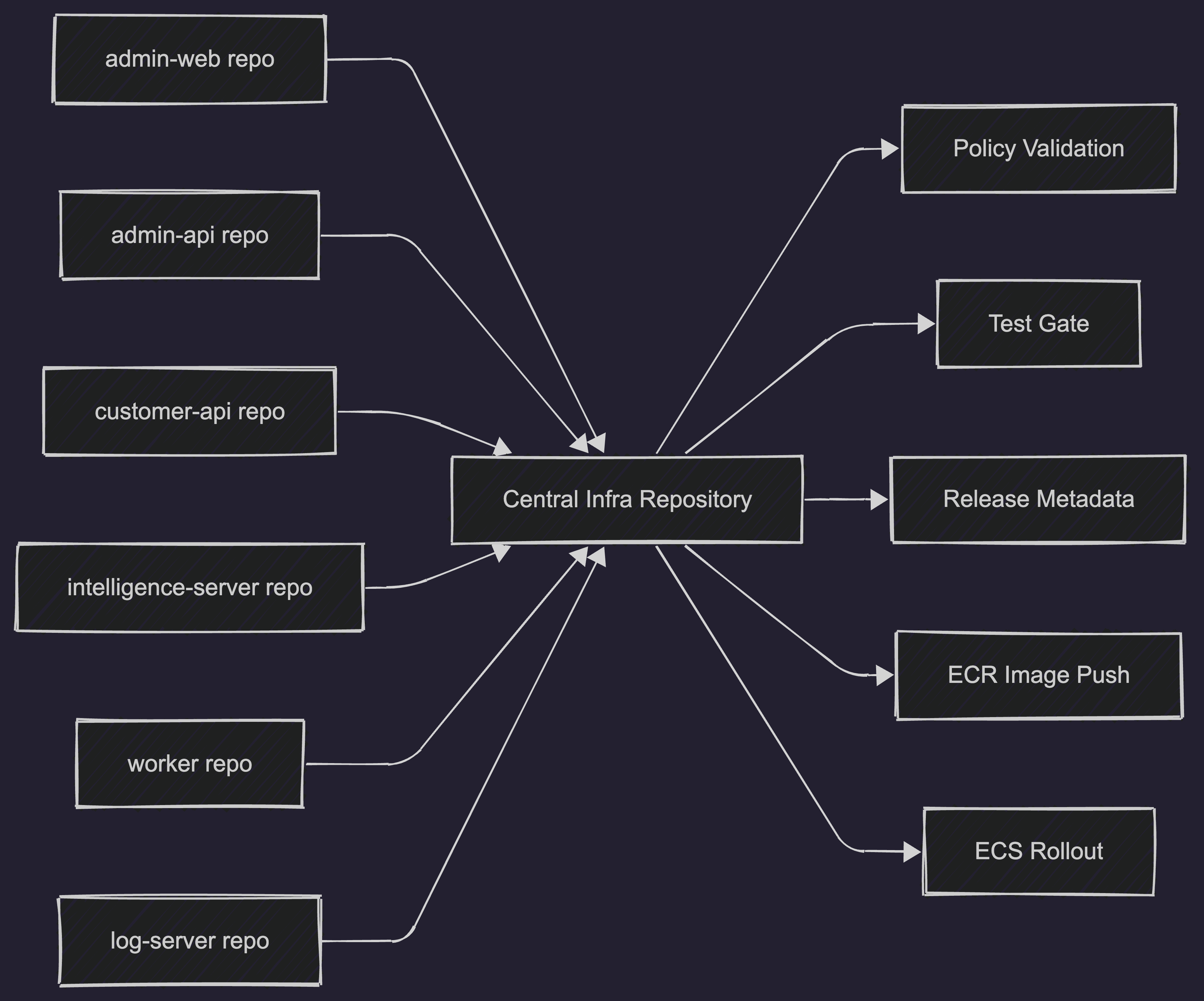
우리 서비스 Holliverse는 로그를 담당하는 서버(log-server), 관리자 웹 서버(admin-web), 관리자 api 서버(admin-api), 사용자 api 서버(customer-api), 고객 상담 분석,키워드 추출, 추천 서버(intelligence-server), **배치 서버(worker)**가 존재하는데 ECR로의 자동 이미지 업로드, ECS로의 자동 배포를 하나하나의 레포지토리에서 관리하는 방법보다 1개의 레포지토리에서 관리하는게 좋지 않을까?
각 서비스 레포지토리에서 ECR 이미지 업로드와 ECS 배포까지 모두 관리하게 할지, 아니면 중앙 인프라 저장소 하나가 이를 해석하고 실행하도록 만들지. 내가 선택한 방향은 후자였다.
즉, 배포 자동화를 서비스별로 흩뿌리는 대신 중앙 Infra Repository에서 정책과 실행을 함께 관리하는 구조를 택했다. 이 선택은 GitHub Actions 파일을 한곳에 모아두는 방법이 아니었다. 실제로는 브랜치 및 커밋 정책, PR 템플릿과 릴리즈 메타데이터, 공통 테스트 게이트, 이미지 빌드와 ECR 업로드, ECS 서비스 배포 오케스트레이션, 템플릿 동기화, 유휴 시간대 리소스 중지 운영까지 하나의 운영 체계로 엮는 작업이다.
왜 중앙 Infra Repository 구조인가?
멀티 레포 환경에서는 초기에 각 서비스 레포지토리마다 CI/CD를 따로 두는 방식이 더 빠르고 단순해 보인다. 실제로 서비스가 적을 때는 그렇게 해도 큰 문제가 없다. 하지만 서비스 수가 늘어나기 시작하면 운영 기준이 조금씩 흔들리기 시작한다.
레포마다 커밋 규칙이 달라지고, PR 템플릿과 릴리즈 방식이 중복되며, 어떤 서비스는 ECS 서비스 기준으로 운영되고 어떤 서비스는 별도 절차를 갖게 된다. 정책을 하나 수정하려고 해도 여러 저장소를 직접 수정해야 한다.
Holliverse도 구조적으로는 “하나의 앱”이라기보다 여러 역할을 가진 서비스들의 묶음에 가까웠다. 그래서 배포를 개별 서비스 저장소의 책임으로 두기보다는, 중앙 저장소가 정책과 배포 흐름을 해석하는 구조가 더 적합하다고 판단했다.
이 방식의 장점은 분명했다. 서비스는 독립적으로 개발하되, 배포 품질과 운영 방식은 중앙에서 일관되게 통제할 수 있다는 점이다. 그리고 이 결정은 이후 두 가지 중요한 개선으로 이어졌다.
- 배포 단위를 더 작게 쪼갤 수 있다.
- CD 방식 자체를 더 가볍게 바꿀 수 있다.
2. 구현
아래 이미지는 CI/CD/CT의 전체 workflow 다이어그램이다.
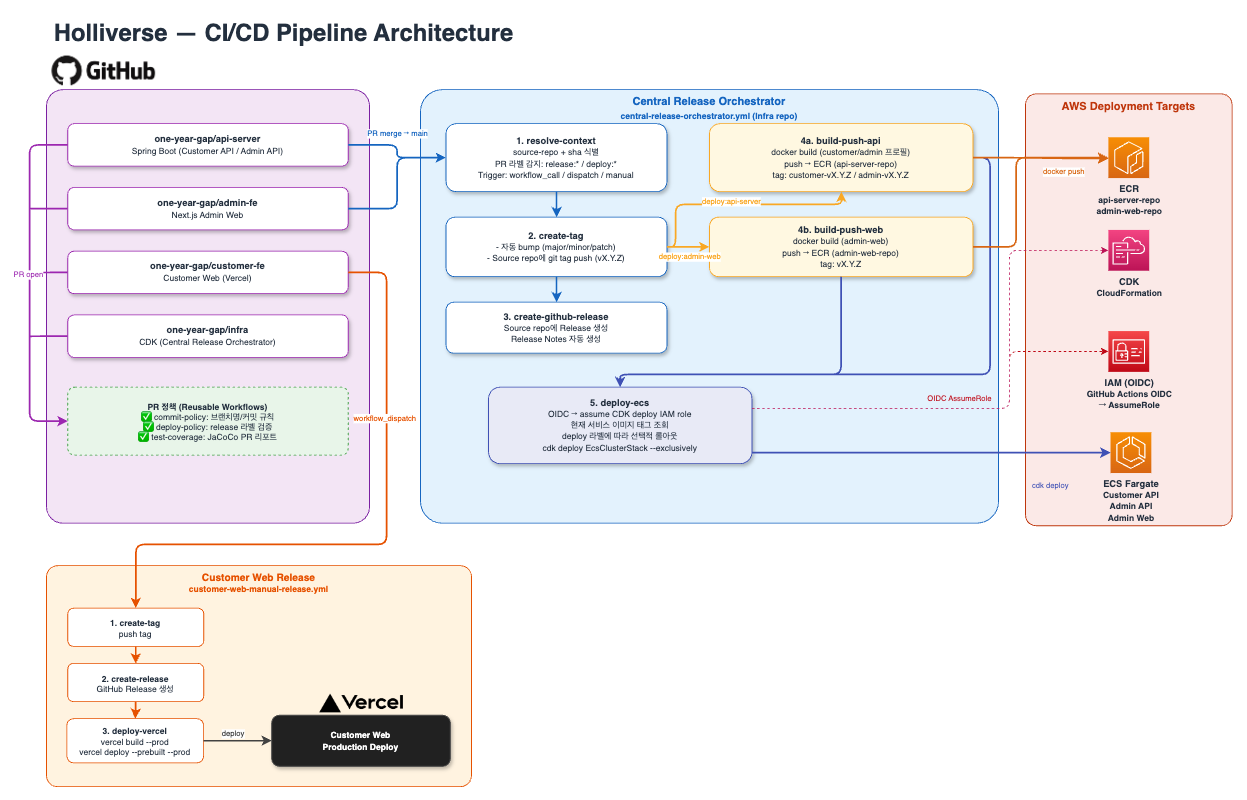
1) CI: 실패를 PR 이후가 아닌 커밋 직전으로 당기기
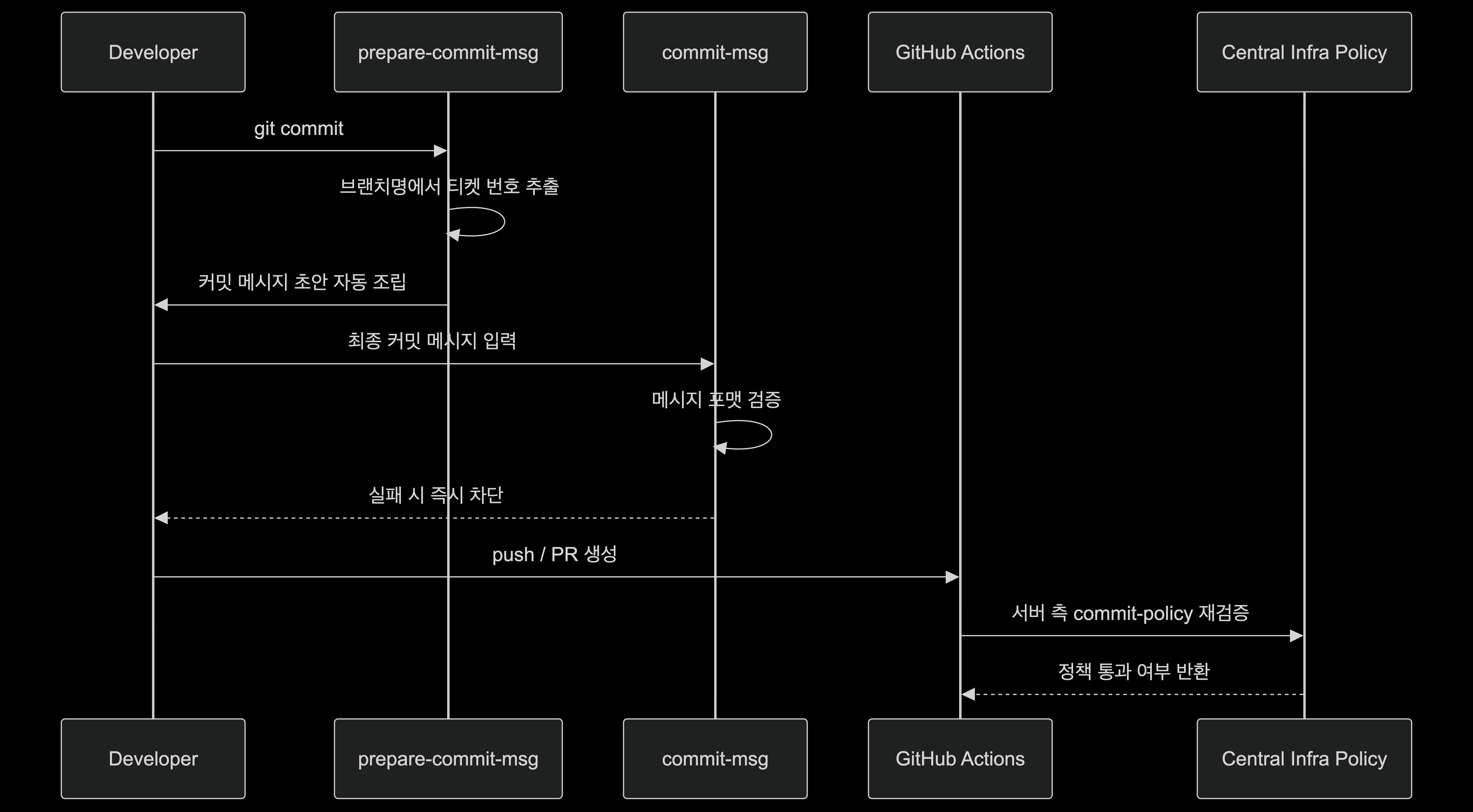
초기에는 브랜치명이나 커밋 메시지 정책 위반이 주로 PR 단계에서 서버 워크플로를 통해 드러났다. 이 구조에서는 잘못된 브랜치를 만들거나 커밋 메시지를 잘못 작성해도 개발자는 PR을 올리고 나서야 실패를 확인할 수 있다. 이건 단순히 불편한 문제를 넘어서, 피드백이 늦어질수록 수정 비용이 커지고 규칙이 점점 형식적으로 느껴진다는 문제가 있었다.
그래서 방향을 바꿨다. 검증을 늦게 한 번 강하게 하는 것보다, 가능한 앞단에서 바로 실패하게 만드는 편이 낫다고 봤다.
현재는 husky 기반의 prepare-commit-msg에서 브랜치명으로부터 티켓 번호를 읽어 커밋 메시지 초안을 자동 조립하고, commit-msg에서 최종 포맷을 로컬에서 즉시 검증한다. 이후 서버 측 commit-policy에서 한 번 더 검증한다. 핵심은 실패가 드러나는 시점을 PR 이후에서 커밋 직전으로 당겼다는 데 있다.
릴리즈 메타데이터 처리 방식도 마찬가지였다. 과거에는 배포용 PR을 만들 때 사람이 PR body와 release label을 각각 직접 맞춰 넣어야 했다. 하지만 이 방식은 누락과 불일치가 자주 발생했다. 그래서 deploy PR 템플릿의 체크박스를 읽고, 이를 기반으로 release label을 자동 동기화하는 방식으로 바꿨다. 사람이 맞춰 넣어야 동작하던 구조 -> 시스템이 읽고 맞춰주는 구조로의 변경이 발생했다.
여기에 sync-template.yml도 추가했다. 중앙 저장소에서 템플릿을 한 번 수정하면 6개 서비스 레포지토리에 자동 반영되도록 만들었다. 덕분에 멀티 레포 환경에서도 템플릿 드리프트를 줄이고, 운영 규칙을 한 방향으로 유지할 수 있게 됐다.
2) CD: stack deploy에서 service rollout으로 배포 단위를 낮추기
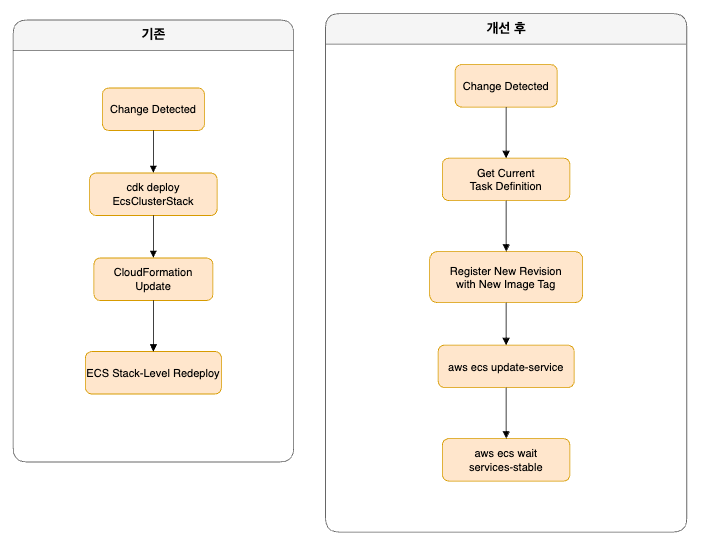
초기 중앙 릴리즈 오케스트레이터는 이미 존재했지만, 실제 배포 흐름은 cdk deploy EcsClusterStack 기반에 가까웠다. 즉 특정 서비스 하나의 이미지만 바뀌더라도 실제 실행 단위는 ECS 관련 스택 재배포에 가까웠다. 이 구조는 서비스 하나만 바뀌어도 배포 범위가 넓고, 배포 job마다 Node, Java, CDK CLI 부트스트랩 비용이 반복되며, stack 단위 재배포라 변경 영향 범위도 커졌다.
현재 중앙 오케스트레이터는 다음 순서로 동작한다. 먼저 현재 task definition을 조회하고, 새 이미지 태그를 반영한 revision을 등록한 뒤, aws ecs update-service를 수행하고 aws ecs wait services-stable로 안정화만 기다린다. 즉 배포를 stack deploy가 아니라 service rollout 중심으로 재설계했다.
AS-IS
- name: Set up Node.js
uses: actions/setup-node@v4
- name: Set up Java 17
uses: actions/setup-java@v4
- name: Install CDK CLI
run: npm install -g aws-cdk@latest
- name: Deploy ECS stack (image rollout)
shell: bash
working-directory: infrastructure
env:
DEPLOY_MODE: ecs
ADMIN_API_IMAGE_TAG: admin-latest
CUSTOMER_API_IMAGE_TAG: customer-latest
ADMIN_WEB_IMAGE_TAG: latest
run: |
set -euo pipefail
cdk deploy EcsClusterStack --require-approval never
TO-BE
- name: Roll out new images via ECS task definition update
shell: bash
run: |
get_service_arn() {
aws cloudformation describe-stack-resources \
--stack-name EcsClusterStack \
--query "StackResources[?ResourceType=='AWS::ECS::Service' && starts_with(LogicalResourceId,'${pattern}')].PhysicalResourceId | [0]"
}
register_new_revision() {
taskdef_json="$(aws ecs describe-task-definition ...)"
aws ecs register-task-definition --cli-input-json "$new_taskdef_json"
}
rollout_service() {
aws ecs update-service \
--cluster "$cluster" \
--service "$service" \
--task-definition "$new_taskdef_arn" \
--force-new-deployment
aws ecs wait services-stable \
--cluster "$cluster" \
--services "$service"
}
중앙 오케스트레이터는 다음 순서로 동작한다.
- 현재 task definition을 조회
- 새 이미지 태그를 반영한 revision을 등록
aws ecs update-service를 실행aws ecs wait services-stable로 안정화 대기
배포 시간은 AWS CloudFormation/ECS의 원본 이벤트 시각을 기준으로 산출했다. CloudFormation은 stack의 UPDATE_IN_PROGRESS와 UPDATE_COMPLETE 차이를 사용했고, ECS는PRIMARY deployment createdAt과 steady state이벤트 차이를 사용했다.
개선 지표 (By AWS CLI)

스택 분리: 모니터링은 ECS 클러스터와 같이 배포하지 않기
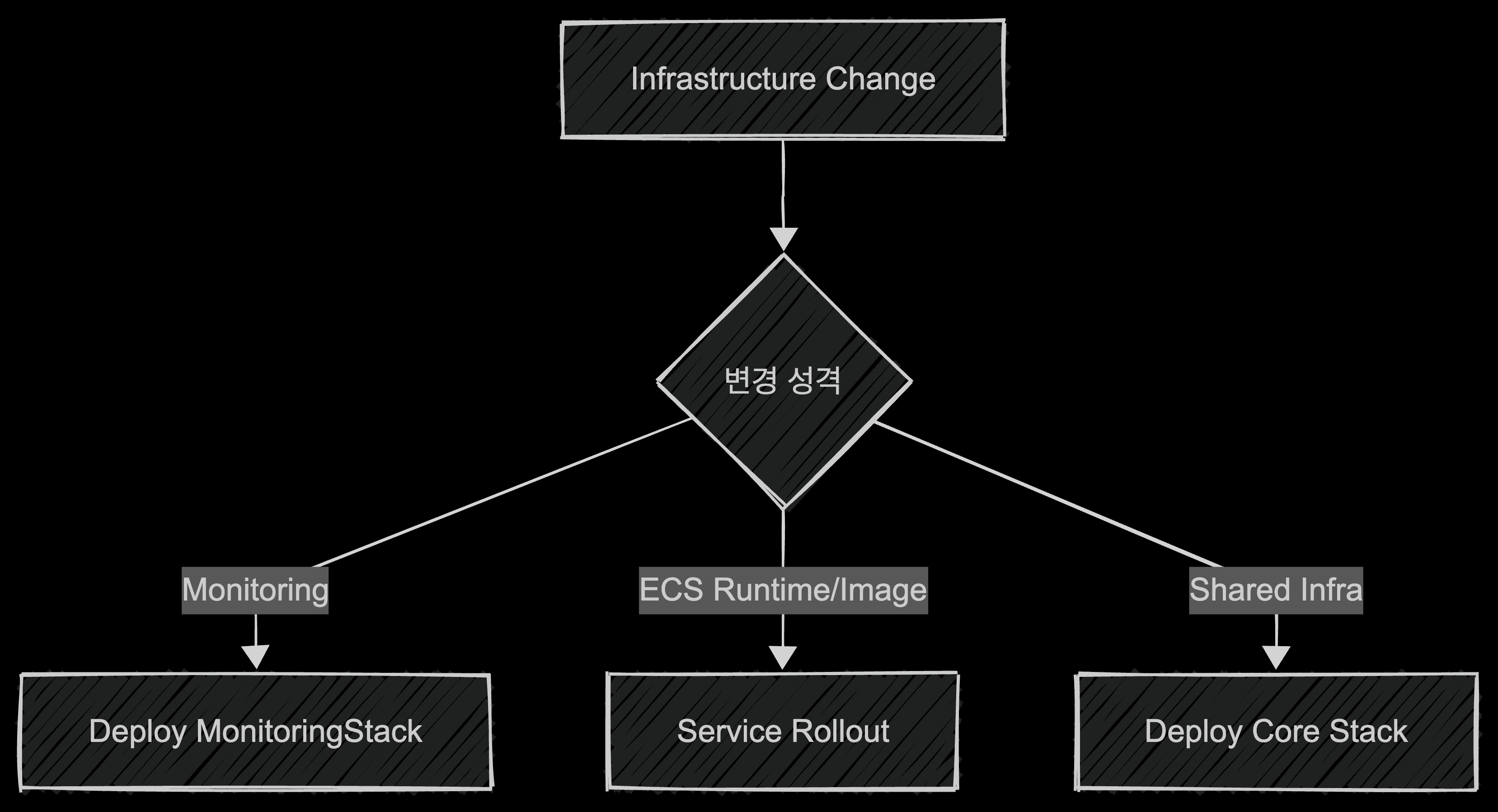
배포 속도를 줄인 또 하나의 중요한 포인트는 변경 성격이 다른 리소스를 같은 배포 단위에 태우지 않는 것이었다. 리소스의 성격이 전혀 다른데도 같은 배포 흐름 안에 묶여 있으면, 작은 변경에도 전체 배포가 필요 이상으로 무거워진다. 대표적인 예가 모니터링 리소스였다.
모니터링은 ECS 서비스 이미지 변경과 성격이 다르다. 그런데 이것을 같은 workflow에 포함하면, 단순한 모니터링 관련 수정에도 전체 ECS 관련 스택 배포 비용을 함께 지불하게 된다. 그래서 MonitoringStack을 별도로 분리해 배포할 수 있도록 구조를 정리했다.
AS-IS
private static final String DEPLOY_MODE_DNS = "dns";
private static final String DEPLOY_MODE_FULL = "full";
switch (deploymentContext.deployMode()) {
case DEPLOY_MODE_ALB -> deployAlb(deploymentContext);
case DEPLOY_MODE_DNS, DEPLOY_MODE_FULL -> deployDns(deploymentContext);
}
TO-BE
private static final String MONITORING_STACK_ID = "MonitoringStack";
private static final String DEPLOY_MODE_MONITORING = "monitoring";
switch (deploymentContext.deployMode()) {
case DEPLOY_MODE_ALB -> deployAlb(deploymentContext);
case DEPLOY_MODE_MONITORING -> deployMonitoring(deploymentContext);
case DEPLOY_MODE_DNS, DEPLOY_MODE_FULL -> deployDns(deploymentContext);
}
private static void deployMonitoring(DeploymentContext context) {
NetworkStack networkStack = createNetworkStack(context);
new MonitoringStack(
context.app(),
MONITORING_STACK_ID,
context.stackProps(),
networkStack.getVpc(),
networkStack.getDbSg(),
networkStack.getAdminApiSg(),
networkStack.getCustomerApiSg(),
PortConfig.getAdminServerPort(),
...
);
}
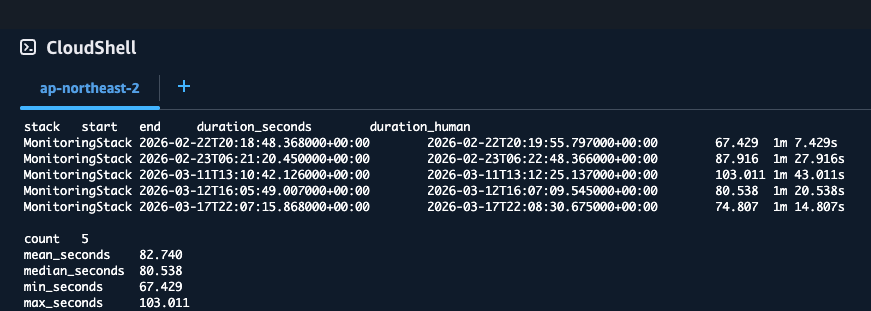
개선 지표 (By AWS CLI)
3) CT: 빠른 배포를 버티게 하는 공통 품질 게이트
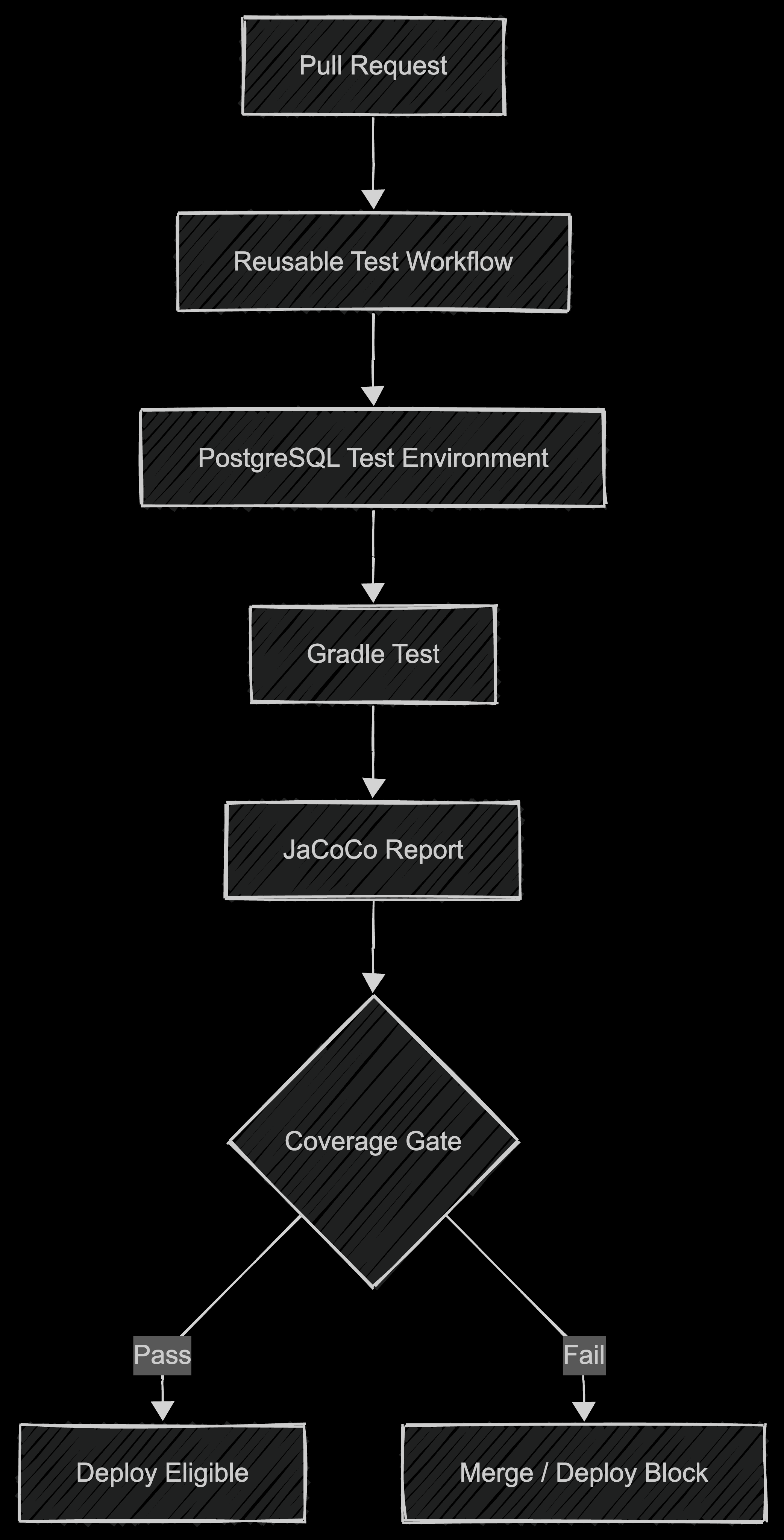
배포 속도를 높이면 그만큼 더 자주, 더 안정적으로 검증해야 한다. 그래서 CT에서는 테스트를 단순 실행하는 것이 아니라, 빠른 변경을 감당할 수 있는 최소한의 품질 게이트를 공통화하는 데 초점을 맞췄다.
현재 공통 테스트 워크플로는 reusable workflow 기반으로 묶여 있고, PostgreSQL 기반 테스트 환경을 구성한 뒤 Gradle 테스트 실행, JaCoCo 리포트 생성, 전체 커버리지와 변경분 커버리지를 평가하는 구조로 되어 있다.
그래서 CI가 실수를 빨리 드러내는 구조라면, CD는 변경을 작게 반영하는 구조이고, CT는 그 빠른 흐름을 버틸 수 있게 만드는 품질 게이트라고 정리할 수 있다.
임계치는 다음과 같이 설정했다.
- overall line coverage 70%
- overall branch coverage 70%
- changed line coverage 80%
- changed branch coverage 80%
로그 파이프라인도 운영형으로 다듬었다
운영 측면에서 함께 의미 있었던 부분은 로그 파이프라인 설계였다.
사용자 로그를 수집하는 MSK Connect S3 Sink는 flush.size=1000, rotate.interval.ms=60000, partition.duration.ms=3600000 기준으로 구성했다. 이 설정 덕분에 raw click log는 최대 60초 이내에 S3로 적재할 수 있었고, 1시간 파티션 단위와 비교하면 98.3% 더 빠른 속도로 원본 로그를 저장하는 구조를 만들 수 있었다.
4) 개선 지표
| 지표 | 기존 방식 | 개선 방식 | 개선율 | 의미 |
| 모니터링 변경 배포 시간(평균) | 449.1초 | 82.7초 | -81.6% | 모니터링 변경을 ECS 전체 스택 배포와 분리해 더 빠르게 반영 |
| 모니터링 배포 처리량 | 8.0회/시간 | 43.5회/시간 | +442.8% | 동일 시간 내 반영 가능한 모니터링 변경 수 대폭 증가 |
| 서비스 배포 시간(중앙값) | 449.1초 | 220.4초 | -50.9% | stack deploy 대신 ECS revision rollout으로 전환 |
| 서비스 배포 처리량 | 8.0회/시간 | 16.3회/시간 | +103.7% | 서비스 단위 배포 효율 증가 |