Holliverse는 DAU 3만 명 규모의 트래픽을 안정적으로 수용하고, 실시간 추천과 대용량 분석을 동시에 처리하기 위해 이벤트 주도 아키텍쳐를 채택했습니다.
사실, 도입한 이유는 단순히 트래픽이 엄청 커서가 아니라, 로그 수집과 실시간 점수 반영, 원본 적재를 메인 API와 분리하기 위해서 입니다.
Kafka를 사용한 이유
Holiverse에서는 Kafka를 로그 수집 및 실시간 이벤트 처리의 중심 메시지 브로커로 사용하였습니다. Kafka를 도입한 가장 큰 이유는, 고객 행동 로그와 서버 API 로그를 메인 서비스 로직과 분리하여 안정적으로 적재하고, 동시에 실시간 최신 본 상품과 배치 분석용 원본 저장을 병렬로 처리하기 위해서였습니다.
| 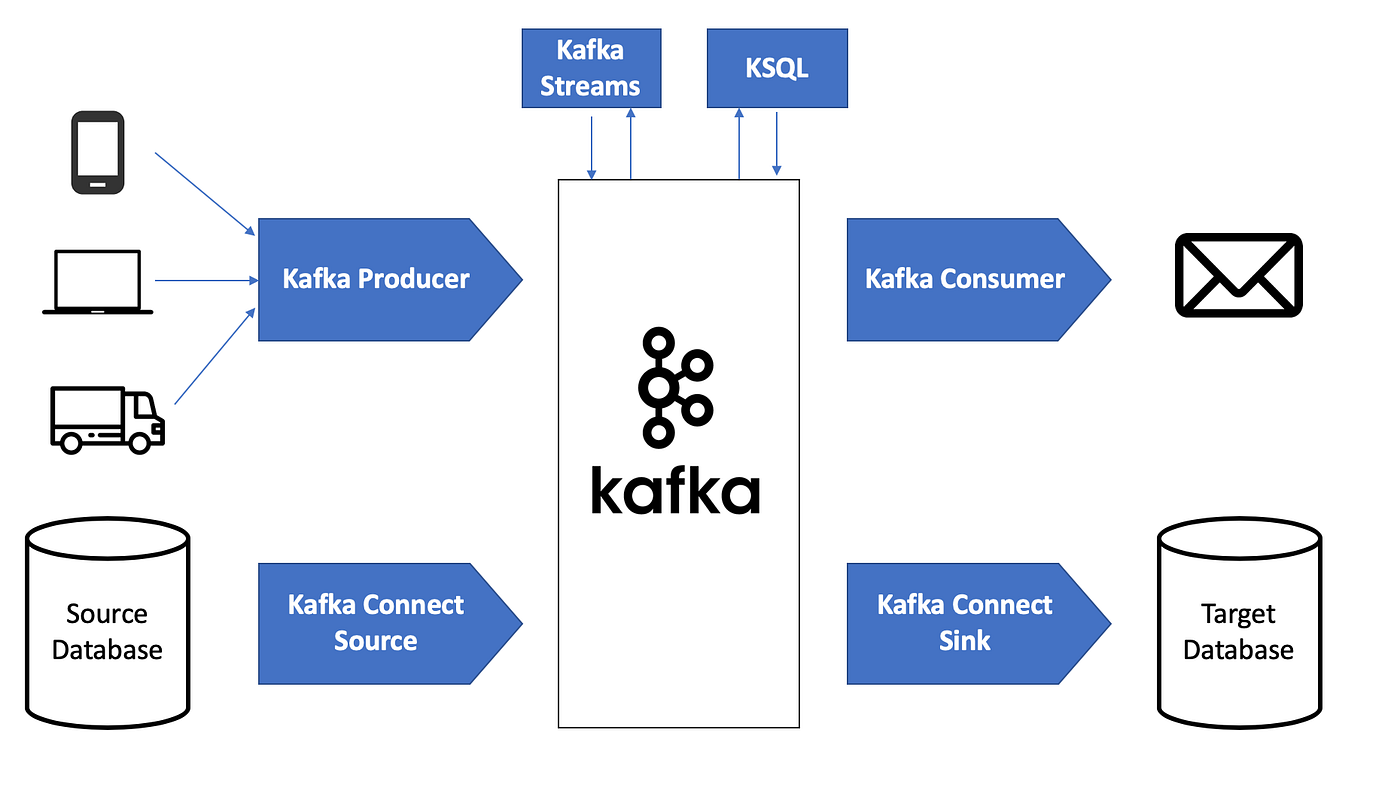 |
Kafka는 하나의 토픽에 들어온 동일한 메시지를 서로 다른 consumer group이 독립적으로 소비할 수 있도록 지원하며, Kafka Connect는 외부 시스템으로의 데이터 입출력을 위한 프레임워크를 제공합니다. 이 구조 덕분에 같은 로그를 실시간 처리용 파이프라인과 원본 적재용 파이프라인으로 동시에 분기할 수 있었습니다.
또한 Kafka는 단순 로그 파이프라인뿐 아니라, LLM 추천 결과를 비동기적으로 전달하는 추천 서빙 파이프라인에도 활용하였습니다.
즉, 우리 프로젝트에서 Kafka는
- 로그 수집과 데이터 레이크 적재를 위한 이벤트 허브
- 실시간 추천에 쓰이는 최근 본 상품을 위한 적제 허브
- FastAPI 기반 LLM 추천 엔진과 Spring 서버를 느슨하게 연결하는 비동기 브로커
역할을 동시에 수행했습니다.
왜 3만 DAU에서 Kafka가 필요했는가 ?
우리 프로젝트의 목표 트래픽은 **일 방문자 3만 명(DAU 30K)** 수준이었습니다. 절대적인 규모만 보면 초대형 서비스 수준은 아니지만, 로그 시스템 관점에서는 단순 DAU보다 이벤트 개수와 처리 방식이 더 중요했습니다.
이 상황에서 API 서버가 로그를 받자마자, 직접 S3와 PostgresSQL에 저장하는 구조를 사용하면 다음 문제가 발생할 수있다고 판단하였습니다.
- S3 또는 DB 응답 지연이 곧바로 API 응답 지연으로 전파되는 문제
- 로그 적재 실패가 메인 기능 장애로 이어지는 문제
- 원본 저장과 실시간 처리 로직이 한 서버에 강하게 결합되는 문제
- 목적지가 늘어날수록 API 서버 코드가 계속 복잡해지는 문제
즉, Kafka는 단순히 엄청난 TPS를 버티기 위해서만이 아니라, 로그 처리 책임을 API 서버에서 분리하고, 후단 저장소 장애가 사용자 응답을 직접 장애가 나지 않기 위한 완충 기술로 필요했습니다.
Kafka를 적용하지 않았을때의 문제
Kafka 없이 direct 방식으로 구성하면 구조는 단순합니다.
클라이언트 로그를 API 서버가 받아 바로 S3, Postgre에 적재하면 됩니다. 하지만 다음과 같은 문제가 있습니다.
1. 장애 전파
S3 업로드가 느려지거나 PostgreSQL 부하가 증가하면, 로그를 처리하는 API 스레드가 함께 묶이게 됩니다. 결과적으로 로그 저장소의 상태가 메인 서비스 응답 품질에 직접 영향을 주는 구조가 됩니다.
2. 부분 실패 처리 복잡성
예를 들어 Postgres에는 반영되었지만, s3 업로드에는 실패한 경우, 어떤 데이터가 성공했고 어떤 데이터가 실패했는지를 직접 추적하고 재처리해야합니다.
3. 목적지 추가 및 서비스 추가시 결합도 증가
지금은 Postgres / S3 두가지 저장소가 있지만, 추후에 더 많은 서비스가 늘어나면, API 서버가 직접 여러군데에 동시에 전송해야하는 구조가 됩니다.
따라서 메인 API는 Kafka까지가 책임이고,
그 이후의 적재와 실시간 처리 책임은 각 consumer가 가져가는 구조가 더 확장성 있는 설계라고 판단하였습니다.
Kafka를 사용해 다음과 같은 장점을 얻었습니다.
1. 동일 로그의 다중 소비: 동일한 로그를 두 경로에 동시에 활용할 수 있었습니다.
- Speed Layer: Postgres에 반영하여 최근 본 상품 볼 수 있도록 저장
- Batch Layer: S3에 raw log 적재해 이후 Athena 기반 분석에 활용
**2. 실시간 처리와 배치 적재의 챔임 분리 **
- 실시간 경로는 1건 단위로 빠르게 소비
- 배치 경로는 여러 건 모아 묶음으로 처리
이 구조로 실시간 반응성과 저장 비용 최적화를 동시에 잡을 수 있었습니다.
**3. 확장성 **
향후 추가 소비처가 생가더라도, consumer만 추가되면 되기에 초기 설계를 깨지 않고 파이프라인을 확장할 수 있습니다.
Kafka가 사용된 지점
크게 세 영역에서 사용되었습니다.
1. 로그 수집 파이프라인
가장 핵심적인 활용으로 , 캐릭터 분류에 필요한 로그 정보들을 계산하기 위한 raw data를 모으는 작업입니다.
- clinet-event-logs 토픽으로 프론트에서 발생한 사용자 행동 로그를 보냅니다.
현재는 클라이언트 로그만 받아 사용자의 행동 의도를 나타냈지만, 추후에 server api 로그도 받아오는 토픽을 받아, 실제 처리 결과와 추천 / 응답의 맥락을 넣을 수 있도록 고도화 할 수 있을것 같습니다.
2. 추천 / 실시간 최근 본 상품 서비스를 위한 실시간 이벤트 처리
Kafka 에 들어온 행동 로그 중 ‘상품 상세 보기’는 즉시 PostgreSQL 적재 파이프라인으로 흘러가도록 설계하였습니다.
즉 Kafka는 단순 저장용 큐가 아니라, 추천 시스템과 최근 본 상품 서비스를 위한 역할을 수행할 수 있는 버퍼역할을 합니다.
3. 추천 시스템의 Kafka 기반 비동기 아키텍쳐
설계 원칙
추천 API는 캐시가 있으면(DB에 결과가 존재하면) 즉시 응답하고, 캐시가 없으면 FastAPI에게 비동기 생성 요청을 보내되, 결과는 Kafka를 통해 다시 수신하도록 설계하였습니다.
즉, 추천 생성 자체는 FastAPI가 담당하고, 최종 결과의 저장과 사용자 응답 완료는 Spring이 담당하는 구조를 택했습니다.
Spring에서 수행한 역할
1) 캐시 조회
persona_recommendation 테이블을 먼저 조회하여,
7일 이내에 생성된 추천 결과가 있으면 이를 즉시 응답하도록 설계하였습니다.
즉, cache hit 시에는 LLM 호출 없이 바로 응답을 내려 서비스 응답 속도를 보장하였습니다.
2) 비동기 추천 요청
캐시가 없거나 7일이 지난 경우에는
FastAPI에 member_id만 전달하여 추천 생성을 요청하였습니다.
이때 Spring은 FastAPI의 결과를 동기적으로 기다리지 않고,
CompletableFuture를 발급하여 프론트와의 연결을 유지한 채 비동기 응답 대기 구조를 만들었습니다.
3) Kafka 결과 수신 및 응답 완료
FastAPI가 Kafka로 추천 결과를 발행하면, Spring Kafka Consumer가 이를 수신하여
persona_recommendation테이블에 결과 저장- 메모리에 보관해둔
CompletableFuture완료 처리 - 프론트엔드 응답 반환
을 수행하도록 설계하였습니다.
즉, Spring은 추천 생성 주체가 아니라 추천 요청 오케스트레이션과 결과 완료 책임을 담당하였습니다.
FastAPI에서 수행한 역할
1) 요청 즉시 수락
Spring으로부터 member_id를 전달받으면,
FastAPI는 즉시 202 Accepted를 반환하였습니다.
즉, FastAPI는 “생성 작업을 받았다”만 응답하고, 실제 추천 생성은 백그라운드에서 수행하도록 하였습니다.
2) LLM 추천 생성
FastAPI는 백그라운드 작업으로
member_llm_context조회- 고객 프로필 / 사용량 / 태그 기반 프롬프트 조합
- OpenAI API 호출
- JSON 추천 결과 생성
을 수행하였습니다.
3) Kafka 발행
최종 생성된 추천 결과는 Kafka의 recommendation-topic으로 발행하도록 설계하였습니다.
즉, FastAPI는 DB 직접 저장이나 Spring 응답 처리까지 책임지지 않고, 추천 결과를 이벤트로 발행하는 것까지를 자신의 책임으로 분리하였습니다.
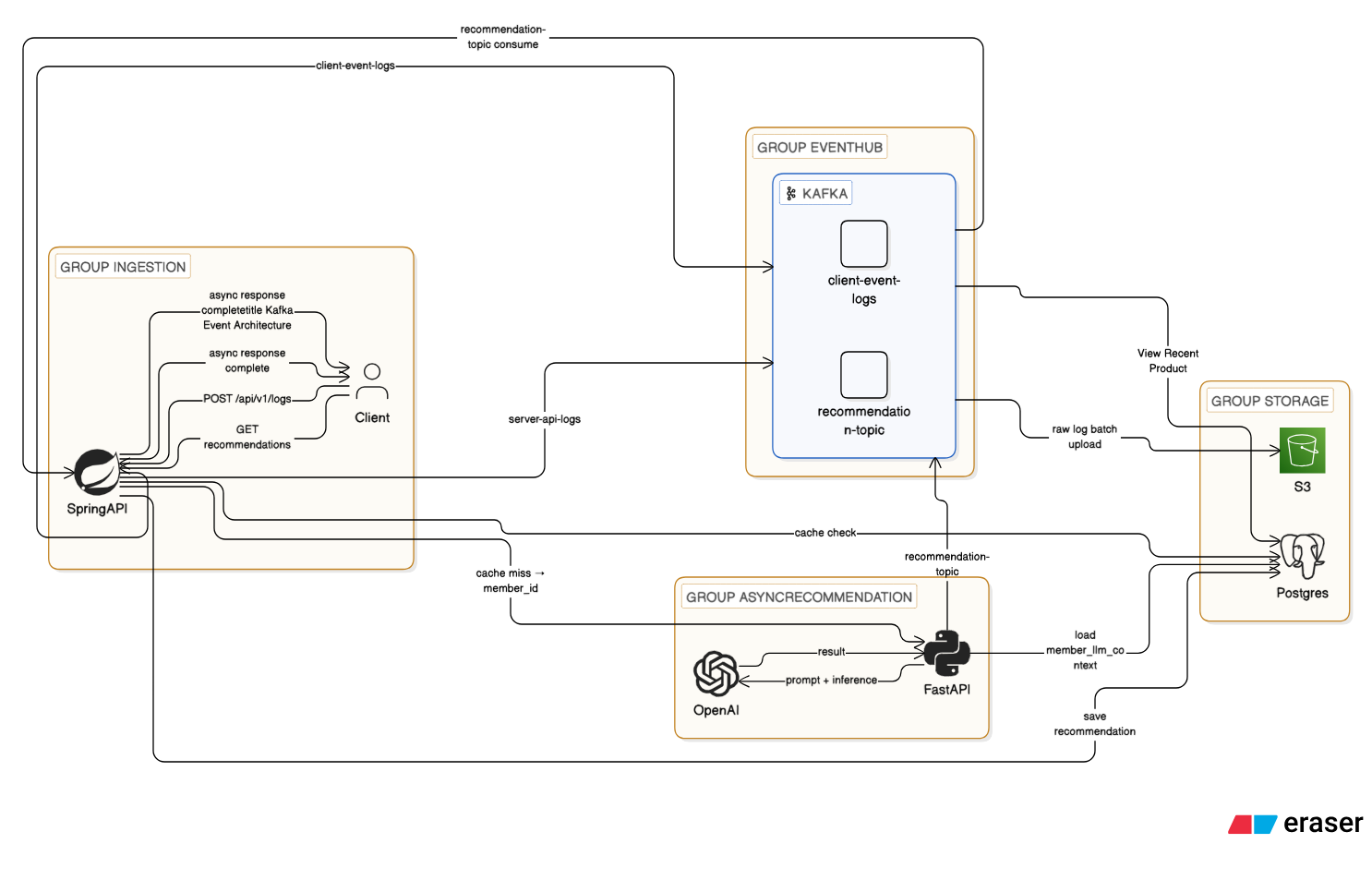
최종 적용 아키텍쳐
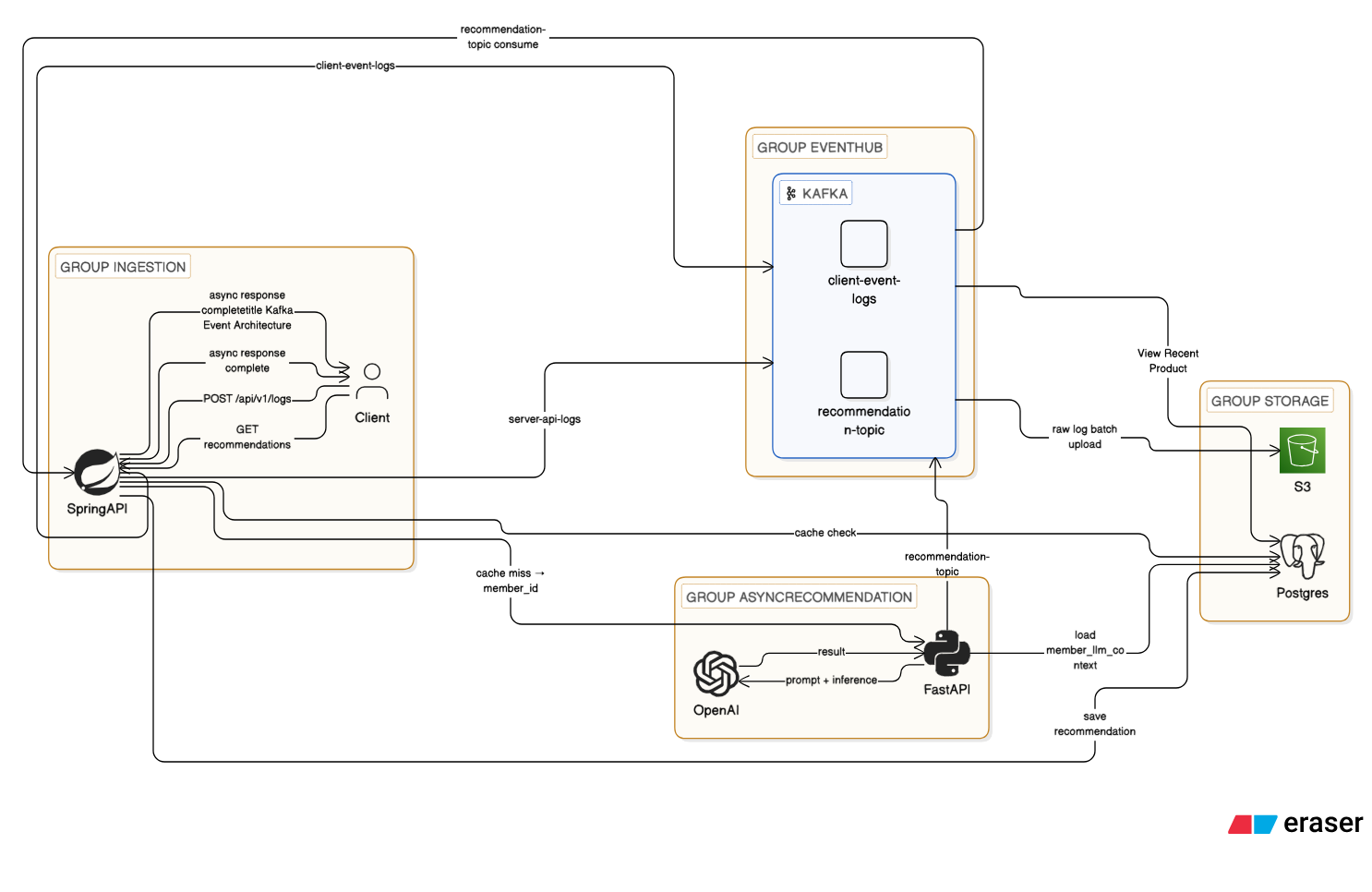
Ingestion
- Client →
POST /api/v1/logs - (Backend Interceptor →
server-api-logs발행)
Kafka Topics
client-event-logsrecommendation-topic