1. 테스트 목적
본 테스트는 실제 U+ 전화 상담 데이터(50건)를 텍스트 형태로 정제한 뒤, 이를 기준 데이터셋으로 사용하여 상담 해석 파이프라인의 정확도를 정량적으로 검증하기 위해 수행하였다. 검증 대상은 크게 두 가지이다.
첫째, 일반 상담 문장에서 핵심 키워드를 추출하고 이를 내부 비즈니스 키워드 체계에 매핑하는 과정의 정확도이다.
둘째, 상담 문장의 긍정·부정 성향을 판별할 수 있는지 여부이다.
이번 테스트는 단순히 결과가 맞았는지 여부만 확인하는 것이 아니라, 실제 운영 환경 기준에서 시스템이 어느 수준까지 신뢰 가능한지, 그리고 어떤 단계에서 오류가 주로 발생하는지를 정량적으로 파악하는 데 목적이 있다.
실제 테스트에 사용된 상담 데이터는 구글 드라이브 링크를 참조하면된다.
2. 테스트 개요
테스트는 라벨링된 상담 fixture를 실제 customer counsel API로 생성한 뒤, 후속 분석 결과를 조회하여 리포트를 생성하는 방식으로 진행하였다. 전체 테스트 케이스는 50건이며, 모든 케이스가 정상 완료되었다. 실패 케이스와 분석 타임아웃 케이스는 발생하지 않았다.
2-1. 테스트 실행 결과
| 항목 | 값 |
|---|---|
전체 케이스 수 (total_cases) |
50 |
완료 케이스 수 (completed_cases) |
50 |
실패 케이스 수 (failed_cases) |
0 |
분석 타임아웃 케이스 수 (analysis_timeout_cases) |
0 |
3. 평가 지표 정의
3-1. 실행 안정성 지표
실행 안정성 지표는 전체 테스트가 정상적으로 수행되었는지를 확인하기 위한 값이다.
| 지표명 | 설명 | 해석 포인트 |
|---|---|---|
total_cases |
전체 테스트 대상 상담 케이스 수 | 이번 테스트가 어떤 규모에서 수행되었는지 보여주는 기본 지표 |
completed_cases |
정상적으로 생성 및 분석 결과 조회까지 완료된 케이스 수 | 전체 케이스 수와 같으면 테스트가 안정적으로 수행되었다고 볼 수 있음 |
failed_cases |
API 호출 실패, 조회 실패, 예외 등으로 정상 완료되지 못한 케이스 수 | 이 값이 크면 뒤의 정확도 결과 해석 신뢰도가 낮아짐 |
analysis_timeout_cases |
제한 시간 내 분석 결과가 생성되지 않은 케이스 수 | 비동기 분석 파이프라인의 안정성을 확인하는 지표 |
3-2. 키워드 정확도 지표
| 지표명 | 설명 | 해석 포인트 |
|---|---|---|
keyword_exact_match_accuracy |
예측 키워드 집합이 정답 키워드 집합과 완전히 동일한 비율 | 가장 엄격한 정확도 지표로, 문장 단위 완전 일치 수준을 보여줌 |
keyword_avg_precision |
각 케이스별로 추출한 키워드 중 실제 정답인 비율의 평균 | 불필요한 키워드를 얼마나 적게 추출했는지 확인 가능 |
keyword_avg_recall |
각 케이스별로 실제 정답 키워드 중 찾아낸 비율의 평균 | 중요한 키워드를 얼마나 놓치지 않았는지 확인 가능 |
keyword_avg_f1 |
Precision과 Recall을 함께 고려한 케이스별 평균 성능 | 전반적인 키워드 추출 품질을 대표하는 균형 지표 |
keyword_micro_precision |
전체 예측 키워드 기준으로 실제 정답인 비율 | 전체 누적 기준에서 과잉 추출 정도를 확인 가능 |
keyword_micro_recall |
전체 정답 키워드 기준으로 실제 찾아낸 비율 | 전체 누적 기준에서 키워드 누락 정도를 확인 가능 |
keyword_micro_f1 |
전체 누적 기준 Precision과 Recall의 균형 성능 | 전체 시스템 수준의 안정적인 키워드 추출 성능을 설명할 때 적합 |
3-3. 오류 유형 지표
| 지표명 | 설명 | 해석 포인트 |
|---|---|---|
keyword_true_positive_total |
정답으로 맞춘 키워드 총 개수 | 시스템이 실제로 맞춘 키워드의 총량 |
keyword_false_positive_total |
예측했지만 정답이 아닌 키워드 총 개수 | 과잉 추출 성향을 보여주는 대표 지표 |
keyword_false_negative_total |
정답이지만 예측하지 못한 키워드 총 개수 | 키워드 누락 성향을 보여주는 대표 지표 |
3-4. 지연 시간 지표
| 지표명 | 설명 | 해석 포인트 |
|---|---|---|
create_latency_avg_ms |
상담 생성 API의 평균 응답 시간 | 첫 응답 속도가 어느 정도인지 보여주는 기본 지표 |
create_latency_p50_ms |
상담 생성 API 응답 시간의 중앙값 | 일반적인 사용자 체감 응답 속도를 설명할 때 적합 |
create_latency_p95_ms |
상담 생성 API 응답 시간의 상위 95% 기준값 | 느린 요청까지 포함했을 때의 안정성을 확인 가능 |
analysis_wait_avg_ms |
상담 생성 후 분석 결과가 조회 가능해질 때까지의 평균 대기 시간 | 비동기 분석 파이프라인의 평균 처리 성능을 보여줌 |
analysis_wait_p50_ms |
분석 대기 시간의 중앙값 | 실제 사용자 입장에서 가장 체감되는 전형적인 대기 시간 |
analysis_wait_p95_ms |
분석 대기 시간의 상위 95% 기준값 | 느린 분석 케이스까지 포함했을 때의 처리 안정성 확인 가능 |
4. 테스트 결과
4.1 키워드 정확도
4.2 오류 건수 결과
4-3. 지연 시간 결과
5. 결과 해석
5.1 키워드 추출 성능 해석
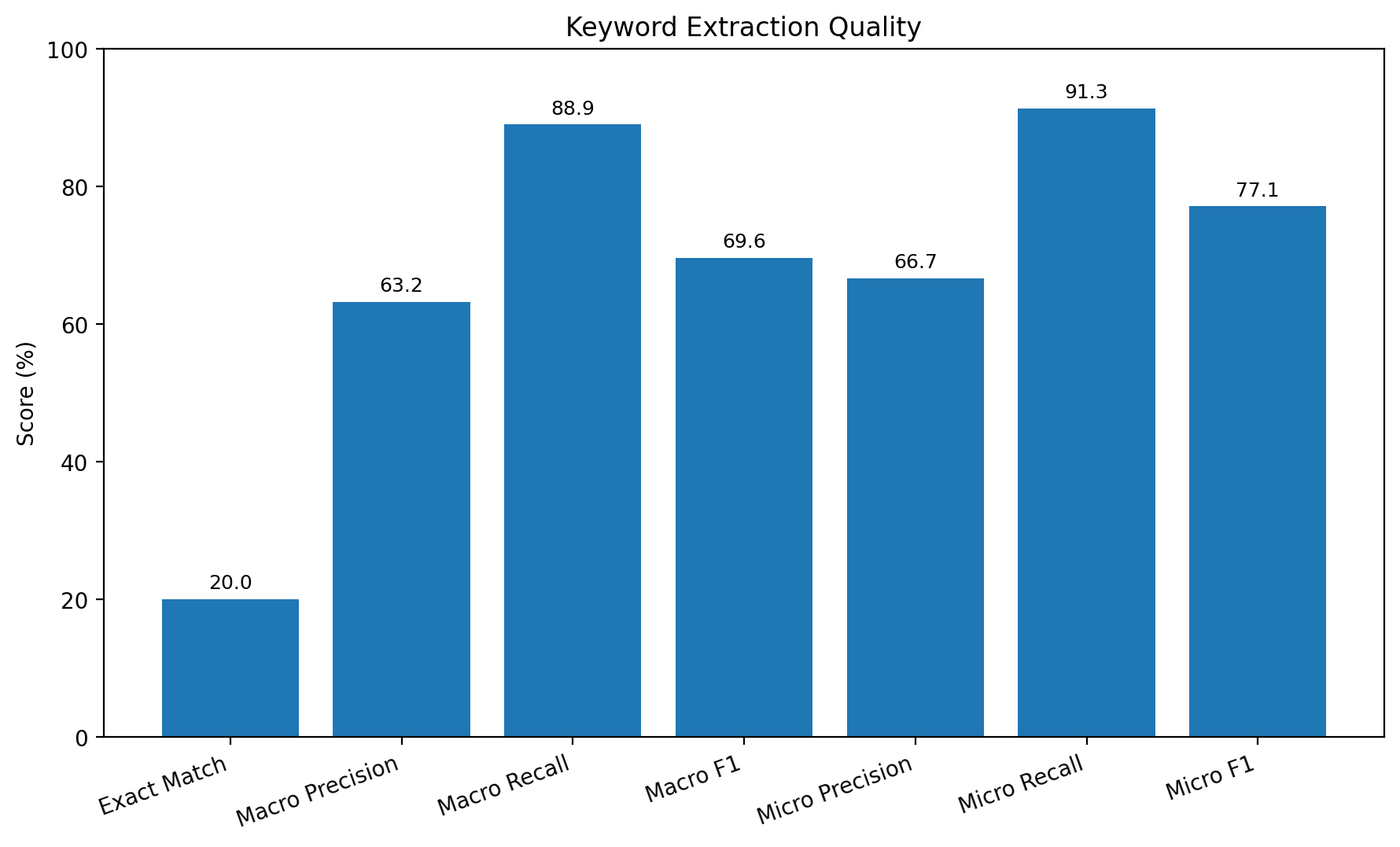
이번 결과에서 가장 먼저 확인할 수 있는 점은 Recall이 매우 높다는 것이다. Macro Recall은 88.95%, Micro Recall은 91.34%로 나타났다. 이는 시스템이 실제 정답 키워드를 놓치는 경우가 많지 않다는 의미이다.
반면 Precision은 Recall보다 상대적으로 낮다. Macro Precision은 63.24%, Micro Precision은 66.67%였다. 즉, 시스템은 정답 키워드를 잘 포착하는 대신, 정답이 아닌 키워드도 함께 예측하는 경향이 있다.
Exact Match Accuracy가 20.00%로 낮게 나타난 점도 이러한 특성과 연결된다. Exact Match는 예측 키워드 집합과 정답 키워드 집합이 완전히 동일해야만 정답으로 처리하기 때문에, 불필요한 키워드가 하나라도 추가되거나 정답 키워드 하나라도 누락되면 실패한다. 따라서 현재 시스템은 핵심 의미는 비교적 잘 포착하지만, _문장 단위 완전 일치 수준의 정밀도는 아직 부족한 상태_라고 볼 수 있다.
5.2 TP/FP/FN 관점 해석
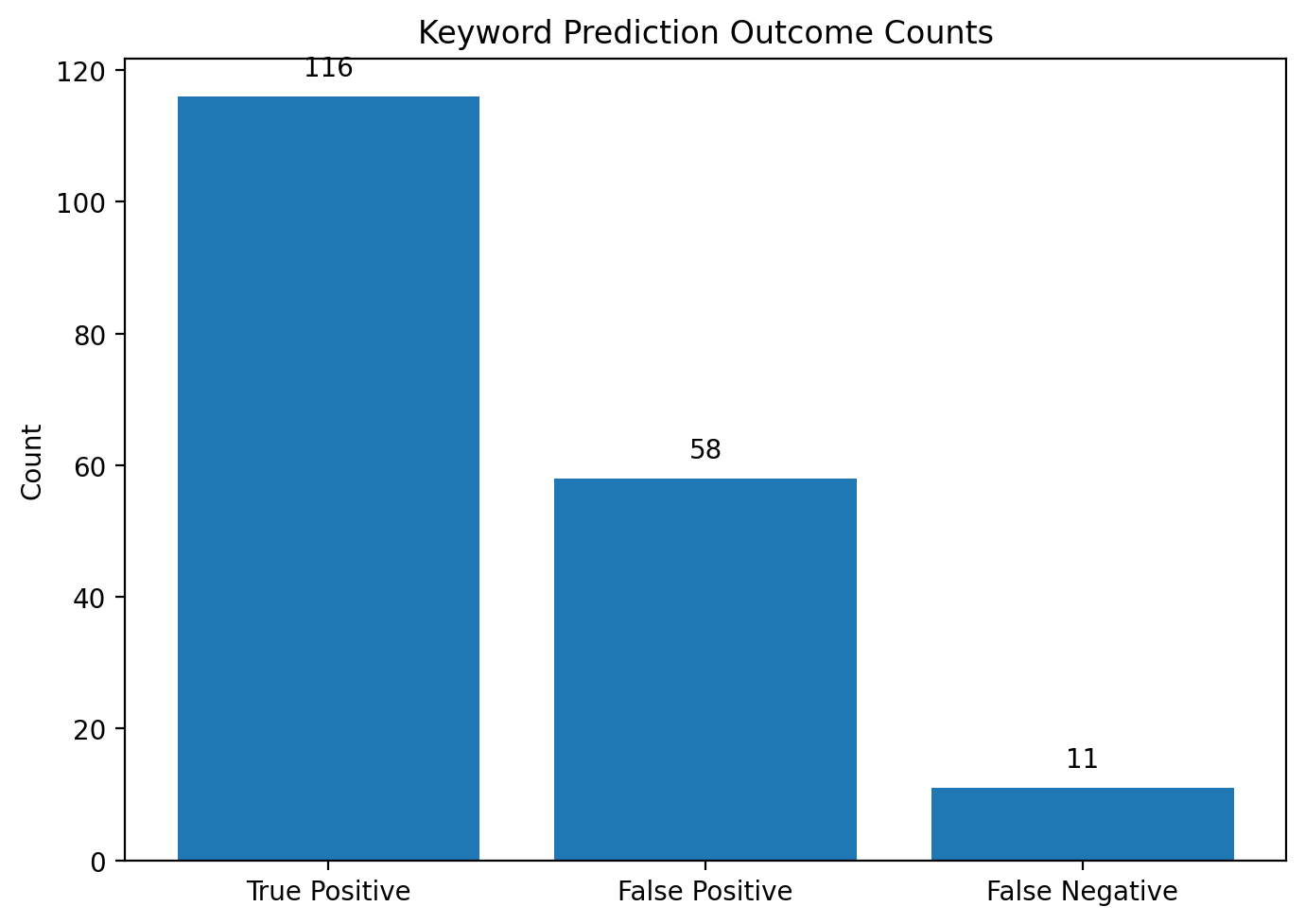
True Positive는 116건, False Positive는 58건, False Negative는 11건이었다. False Negative가 상대적으로 작고 False Positive가 크게 나타난 점은 현재 시스템이 정답을 놓치기보다는 다소 넓게 추출하는 성향을 가진다는 것을 의미한다.
5.3 Macro / Micro 차이 해석
Macro F1은 69.56%, Micro F1은 77.08%로 나타났다. Micro F1이 Macro F1보다 높다는 것은, 일부 어려운 케이스가 케이스 단위 평균 점수를 끌어내렸지만 전체 누적 성능은 그보다 안정적이라는 뜻이다. 다시 말해, 전체 키워드 수준에서는 비교적 준수한 성능을 보였으나, 개별 문장 단위로 보면 편차가 존재한다고 해석할 수 있다.
5.4 지연 시간 해석
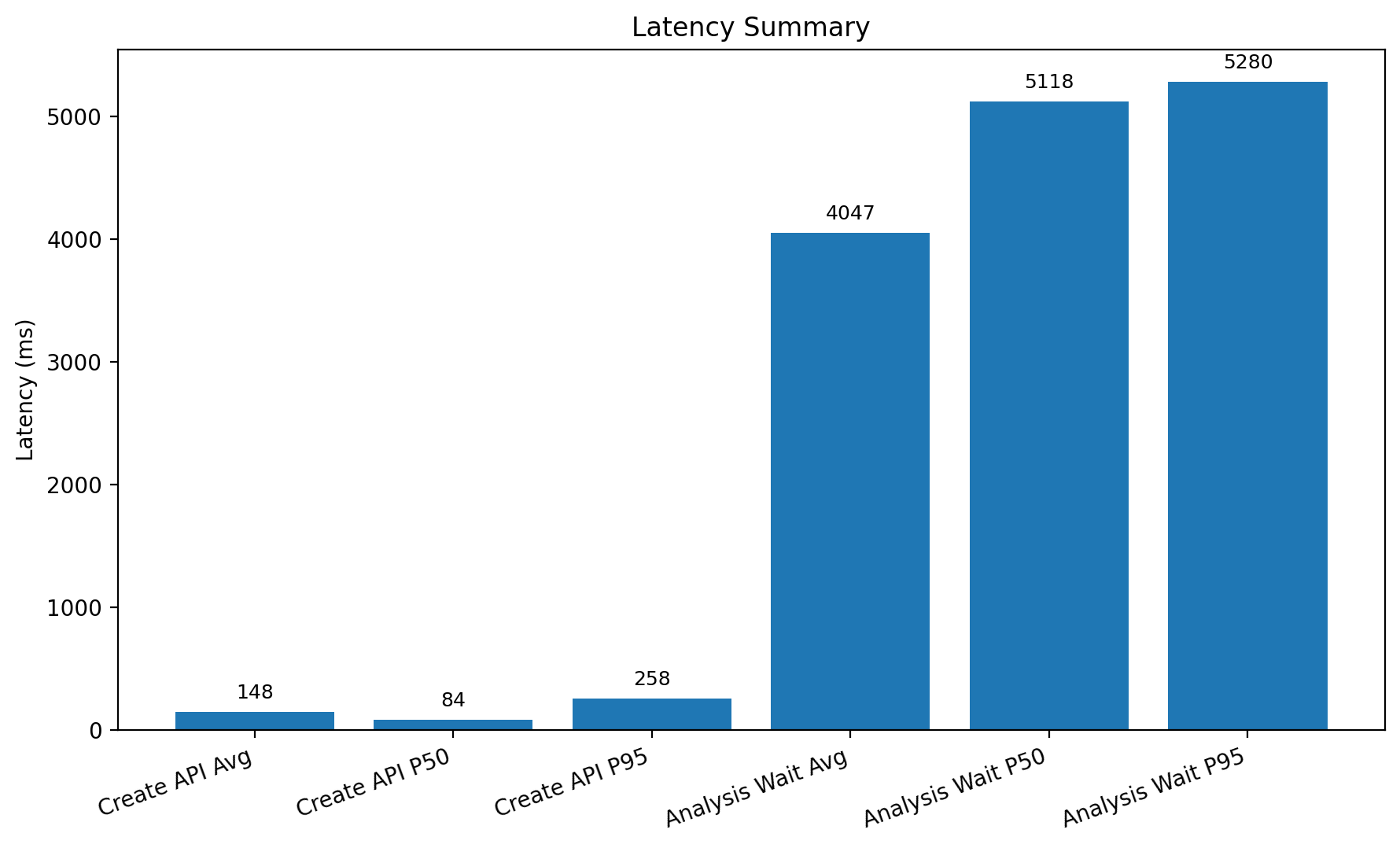
상담 생성 API의 평균 지연 시간은 148.18ms, P95는 258.25ms였다. 이는 API 자체의 응답 속도는 비교적 안정적이고 빠른 편임을 보여준다.
반면 분석 결과가 생성될 때까지의 대기 시간은 평균 4047.12ms, P50은 5118ms, P95는 5280.25ms였다. 즉, 실제 사용자 체감 기준으로는 생성 API보다 분석 완료까지의 비동기 구간이 더 큰 영향을 준다.
특히 평균보다 P50이 더 높게 나타난 점은 일부 매우 빠르게 처리된 케이스가 평균을 낮춘 결과로 볼 수 있다. 따라서 실제 전형적인 사용자 체감 시간은 평균 4초보다 중앙값인 약 5.1초에 더 가깝다고 해석하는 것이 적절하다.
하지만, 상담 분석 특성상 실시간에 준하는 서비스이므로 5초 내외의 응답값이면 개선 포인트라고 생각하지는 않았다.
6. 결론
본 테스트는 실제 U+ 상담 데이터를 기반으로 상담 생성 API와 후속 분석 파이프라인을 end-to-end로 검증했다는 점에서 의미가 있다. 전체 50건이 모두 정상 처리되었으며, 키워드 추출 측면에서는 높은 Recall과 준수한 Micro F1을 확인할 수 있었다. 이는 시스템이 핵심 키워드를 놓치는 비율은 낮고, 전반적으로 의미 중심의 추출은 안정적으로 수행하고 있음을 보여준다.
다만 Precision과 Exact Match Accuracy가 상대적으로 낮게 나타난 점은, 현재 시스템이 정답 키워드를 다소 넓게 추출하는 성향을 가지고 있음을 시사한다. 따라서 향후 개선 방향은 Recall을 유지하면서 False Positive를 줄이는 방향이 되어야 한다.
성능 측면에서는 생성 API보다는 비동기 분석 결과 대기 시간이 실제 병목으로 확인되었다. 또한 감정 분류는 현재 저장 구조상 정확한 정답률 측정이 불가능하므로, 평가 체계 자체의 개선이 선행되어야 한다.
종합하면, 현재 파이프라인은 키워드 누락은 적지만 과잉 추출 경향이 있는 상태이며, 운영 품질을 높이기 위해서는 정밀도 개선과 분석 대기 시간 최적화, 그리고 감정 분류 결과 저장 구조 보완이 주요 과제로 도출된다.