이전 이탈률 설계와 ML용 데이터 셋의 사용을 위해서 우리 서비스에 알맞는 다양한 Feature들을 선정했다. 이번 글에서는 선정된 Feature들에 대해 어떻게 관리하고, 데이터 생명주기에 따라 계산 시점을 어떻게 분리했는지, 나아가 향후 Feature 추가를 고려한 확장 가능한 이탈률 계산 엔진 데이터베이스 스키마 설계에 대해 기록하고자 한다.
1. Feature의 생명 주기 분리: Real Time VS Event VS Default
이제까지는 우리가 가지고 있는 정보를 어떤 Feature로 추출할 것인지에 대해서만 언급했다. 따라서, 이번 글에서는 각 Feature들의 생명주기를 우리가 어떻게 나누었고, 각 생명주기의 관리를 위해 테이블을 어떻게 설계할 수 밖에 없었는지에 대해서 작성하겠다.
앞선 글에서는 단순히 Batch Time과 Real Time으로 나누었지만, 좀 더 명확한 생명 주기의 분리를 위해서 명확하게 3가지의 생명주기별 Feature를 나누었다.
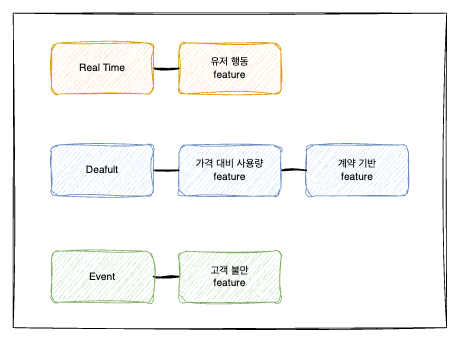
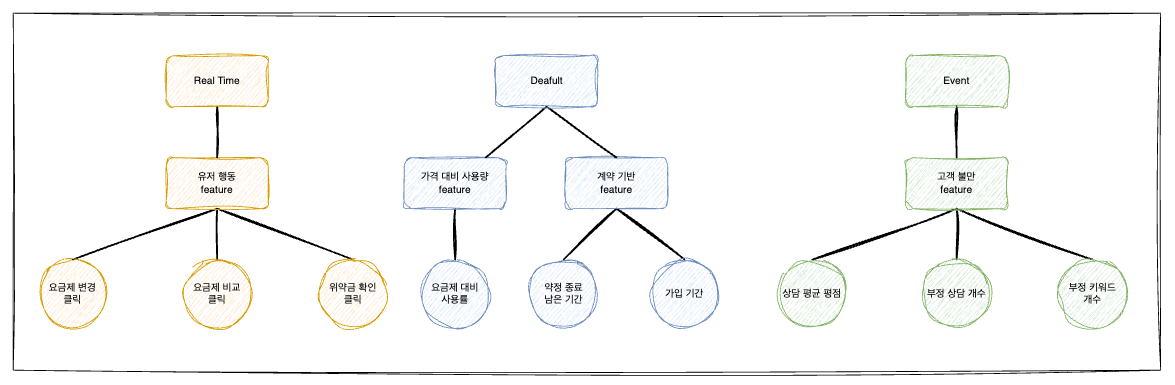
총 4가지의 Feature들에 대해서 위와 같은 3가지의 생명주기를 가진다. 우선 이렇게 생명주기를 분리한 이유부터 작성하겠다.
1) 각 Feature마다 생성 방식과 요구되는 실시간성이 다르다.
- Default (기본 정보):
약정 종료 남은 기한,가입 초기 여부,요금제 대비 사용량등은 사용자의 계약 정보를 바탕으로 계산됩니다. 특히 우리 서비스의 주 목적은 고객 분석이므로, 모바일 요금 사용량 같은 데이터는 1달 단위나 1주일 단위 배치(Batch)로 갱신되어도 충분하다. - Event (이벤트성):
고객의 불만 상담 개수,부정적 키워드 언급,상담 평균 평점등은 고객이 상담을 진행하는 순간 발생합니다. 상담 데이터가 등록되는 즉시 텍스트를 분석하여 이탈률에 반영해야 하므로 이벤트 기반의 생명주기를 가진다. - Real-Time (실시간):
요금제 변경 클릭,요금제 비교 이력,위약금 확인등 유저의 행동 기반 로그는 발생하는 즉시 수집되어야 하는 실시간 생명주기를 가진다.
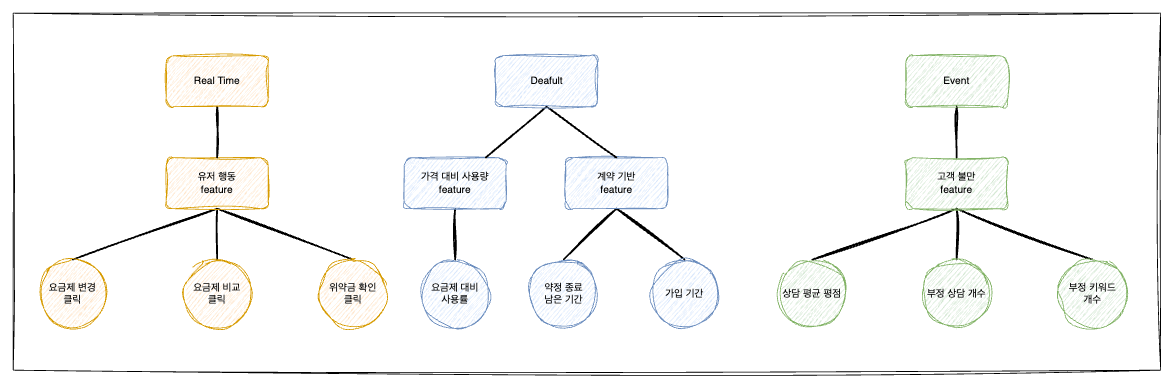
2) 다양한 적재 주체
3가지의 Feature는 아래와 같은 적재 형식으로 데이터가 적재된다.
- RealTime(실시간) - 실시간 로그 수집 API를 통해 집계
- Event(이벤트성) - 상담 내용을 분석하는 python기반 FastAPI가 CDC를 통해 추가/변경 상담 데이터 감지 후 분석 실시 → 분석 결과 HTTP로 api-server에게 전송 → 해당 정보 가중치 계산 후 적재
- Default(기본 정보) - 1주일에 1번씩 Batch를 통해 계산 후 적재
2. 데이터베이스 Feature 설계
위에서 정의한 생명주기와 파이프라인을 담아내기 위해 스키마를 설계했다. 핵심은 단순히 이탈률 점수(Score)만 추가하는 것이 아니라, PostgreSQL의 JSONB 기능을 활용해 ‘왜 위험한지(상담 때문인지, 특정 클릭 로그 때문인지)’에 대한 근거를 함께 저장하는 것이다. 이를 통해 쿠폰 발송, 리텐션 캠페인 등 후속 액션으로 이어질 수 있게 했다.
우리 팀은 Flyway를 통해 DB 스키마를 엄격하게 버전 관리하고 있으며, 아래 DDL은 핵심이 되는 테이블 구조를 보여준다.
1.Feature Snapshot 저장소 테이블 - V28__create_churn_feature_score.sql
-- enum 생성
CREATE TYPE feature_type AS ENUM (
'CONTRACT_FEATURE',
'DISSATISFACTION_FEATURE',
'USAGE_FEATURE',
'MEMBER_ACTION_FEATURE'
);
-- feature snapshot 저장소
CREATE TABLE feature_snapshot_store (
feature_snapshot_id BIGINT PRIMARY KEY,
member_id BIGINT NOT NULL,
feature_type feature_type NOT NULL,
created_at TIMESTAMP NOT NULL,
updated_at TIMESTAMP NOT NULL,
feature_score INTEGER NOT NULL,
CONSTRAINT fk_feature_snapshot_member
FOREIGN KEY (member_id) REFERENCES member(member_id),
CONSTRAINT chk_feature_score
CHECK (feature_score BETWEEN 0 AND 100)
);
-- 1. 계약 기반 feature
CREATE TABLE contract_feature (
feature_snapshot_id BIGINT PRIMARY KEY,
contract_remaining_weeks SMALLINT NOT NULL,
tenure_weeks INTEGER NOT NULL,
CONSTRAINT fk_contract_feature_snapshot
FOREIGN KEY (feature_snapshot_id)
REFERENCES feature_snapshot_store(feature_snapshot_id)
ON DELETE CASCADE,
CONSTRAINT chk_contract_remaining_weeks
CHECK (contract_remaining_weeks BETWEEN 0 AND 106),
CONSTRAINT chk_tenure_weeks
CHECK (tenure_weeks >= 0)
);
-- 2. 사용량 기반 feature
CREATE TABLE usage_feature (
feature_snapshot_id BIGINT PRIMARY KEY,
allowance_usage_rate_pct INTEGER NOT NULL,
CONSTRAINT fk_usage_feature_snapshot
FOREIGN KEY (feature_snapshot_id)
REFERENCES feature_snapshot_store(feature_snapshot_id)
ON DELETE CASCADE,
CONSTRAINT chk_allowance_usage_rate_pct
CHECK (allowance_usage_rate_pct BETWEEN 0 AND 100)
);
-- 3. 유저 행동 기반 feature
CREATE TABLE member_action_feature (
feature_snapshot_id BIGINT PRIMARY KEY,
change_mobile_cnt SMALLINT NOT NULL DEFAULT 0,
comparison_cnt INTEGER NOT NULL DEFAULT 0,
checked_penalty_fee_cnt INTEGER NOT NULL DEFAULT 0,
CONSTRAINT fk_member_action_feature_snapshot
FOREIGN KEY (feature_snapshot_id)
REFERENCES feature_snapshot_store(feature_snapshot_id)
ON DELETE CASCADE,
CONSTRAINT chk_change_mobile_cnt
CHECK (change_mobile_cnt >= 0),
CONSTRAINT chk_comparison_cnt
CHECK (comparison_cnt >= 0),
CONSTRAINT chk_checked_penalty_fee_cnt
CHECK (checked_penalty_fee_cnt >= 0)
);
-- 4. 고객 불만 기반 feature
CREATE TABLE member_dissatisfaction_feature (
feature_snapshot_id BIGINT PRIMARY KEY,
star_mean_score NUMERIC(2,1) NOT NULL DEFAULT 0.0,
negative_cnt INTEGER NOT NULL DEFAULT 0,
terminating_keyword_cnt JSONB NOT NULL DEFAULT '{}'::jsonb,
CONSTRAINT fk_member_dissatisfaction_feature_snapshot
FOREIGN KEY (feature_snapshot_id)
REFERENCES feature_snapshot_store(feature_snapshot_id)
ON DELETE CASCADE,
CONSTRAINT chk_star_mean_score
CHECK (star_mean_score BETWEEN 0.0 AND 5.0),
CONSTRAINT chk_negative_cnt
CHECK (negative_cnt >= 0)
);
ALTER TABLE business_keyword
ADD COLUMN IF NOT EXISTS negative_weight BIGINT NOT NULL DEFAULT 0;
2. 이탈 위험도 Score 테이블 - V31__create_feature_score.sql, V32__add_churn_revision_cursor.sql
-- 이탈 위험도 스냅샷 (이탈 상세 점수의 부모, 1:1)
CREATE TABLE churn_score_snapshot (
snapshot_id BIGINT NOT NULL GENERATED BY DEFAULT AS IDENTITY,
member_id BIGINT NOT NULL,
churn_score INTEGER NOT NULL,
risk_level VARCHAR(20) NOT NULL DEFAULT 'LOW'
CHECK (risk_level IN ('HIGH', 'MEDIUM', 'LOW')),
risk_reasons JSONB NOT NULL DEFAULT '[]'::jsonb,
base_date DATE NOT NULL,
CONSTRAINT pk_churn_score_snapshot PRIMARY KEY (snapshot_id),
CONSTRAINT uq_churn_score_snapshot_member_date UNIQUE (member_id, base_date),
CONSTRAINT fk_churn_score_snapshot_member
FOREIGN KEY (member_id) REFERENCES member (member_id)
ON DELETE CASCADE
);
CREATE INDEX idx_churn_score_snapshot_base_date ON churn_score_snapshot (base_date);
COMMENT ON TABLE churn_score_snapshot IS '이탈 위험도 스냅샷 (회원·기준일별)';
COMMENT ON COLUMN churn_score_snapshot.churn_score IS '이탈 확률 점수';
COMMENT ON COLUMN churn_score_snapshot.risk_level IS '이탈 위험 등급 (HIGH/MEDIUM/LOW)';
COMMENT ON COLUMN churn_score_snapshot.risk_reasons IS '위험 사유 목록 (JSON 배열)';
COMMENT ON COLUMN churn_score_snapshot.base_date IS '스냅샷 기준일';
-- V27 테이블 컬럼 기본값 보강: contract_feature.tenure_weeks, usage_feature.allowance_usage_rate_pct
ALTER TABLE contract_feature
ALTER COLUMN tenure_weeks SET DEFAULT 0;
ALTER TABLE usage_feature
ALTER COLUMN allowance_usage_rate_pct SET DEFAULT 0;
CREATE SEQUENCE IF NOT EXISTS churn_score_revision_seq START WITH 1 INCREMENT BY 1;
ALTER TABLE churn_score_snapshot
ADD COLUMN IF NOT EXISTS revision_id BIGINT NOT NULL DEFAULT nextval('churn_score_revision_seq'),
ADD COLUMN IF NOT EXISTS updated_at TIMESTAMPTZ NOT NULL DEFAULT now();
CREATE UNIQUE INDEX IF NOT EXISTS uq_churn_score_snapshot_revision_id
ON churn_score_snapshot (revision_id);
CREATE INDEX IF NOT EXISTS idx_churn_score_snapshot_revision_id
ON churn_score_snapshot (revision_id DESC);
CREATE INDEX IF NOT EXISTS idx_churn_score_snapshot_updated_at
ON churn_score_snapshot (updated_at DESC);
COMMENT ON COLUMN churn_score_snapshot.revision_id IS '실시간 변경 조회용 증가 커서';
COMMENT ON COLUMN churn_score_snapshot.updated_at IS '최근 갱신 시각';
2) 왜 이렇게 스키마를 선택했는가?
1.원천 데이터와 최종 판단 결과의 Decoupling
상담, 로그, 사용량, 약정 정보는 들어오는 시점도 다르고 갱신 주기도 다릅니다. 어떤 것은 실시간 이벤트이고, 어떤 것은 배치성 데이터입니다. 이런 데이터를 한 테이블에 몰아넣으면 갱신 로직이 복잡해지고, 나중에 신호를 추가하거나 계산 방식을 바꾸기도 어려워진다. 그래서 feature_snapshot_store와 각 세부 테이블로 ‘원천 피처’를 분리하고, 최종적으로 관리자 화면과 API가 보는 값은 churn_score_snapshot에 모으는 구조를 택했습니다.
이렇게 하면 Feature별 저장은 독립적으로 유지하면서도, 최종 점수는 항상 같은 방식으로 합산할 수 있다.
2. 하루 단위의 정합성과 실시간성
운영 화면에서는 “오늘 기준 이 회원의 최신 상태”가 중요하므로 회원별, 기준일별로 하나의 최종 행만 유지하는 구조가 필요하다. 그래서 churn_score_snapshot에 (member_id, base_date) 유니크 제약을 두어 하루에 한 회원당 하나의 정보만 남을 수 있도록 설계했다.
반면 실시간 화면에서는 같은 회원의 점수가 여러 번 바뀌는 것도 구현해야 한다. 이 요구를 해결하기 위해 revision_id를 별도 증가 커서로 두었다. 즉 데이터 모델은 ‘하루에 한 줄’을 유지하지만, 변경 이력 감지는 ‘매번 새로운 revision’으로 처리하도록 분리했다. 이 구성이 있어야 목록 정합성과 실시간 폴링을 동시에 만족시킬 수 있다.
3. 설명 가능한 구조
최종 점수만 저장하면 운영자는 결과를 볼 수는 있어도 이해할 수는 없다. 그래서 churn_feature_score에 기본 점수, 사용량 점수, 상담 점수, 로그 점수를 분해해서 저장했고, risk_reasons는 JSON 형태로 세부 근거를 구조화해 저장했다.
이 설계 덕분에 ‘왜 HIGH가 되었는지’를 사람에게 설명할 수 있고, 이후 프론트엔드에서 근거 리스트를 그대로 렌더링할 수 있다.